DL » 深度学习(六)——词向量(2)
2017-06-21 :: 6010 Words词向量
word2vec(续)
CBOW & Skip-gram
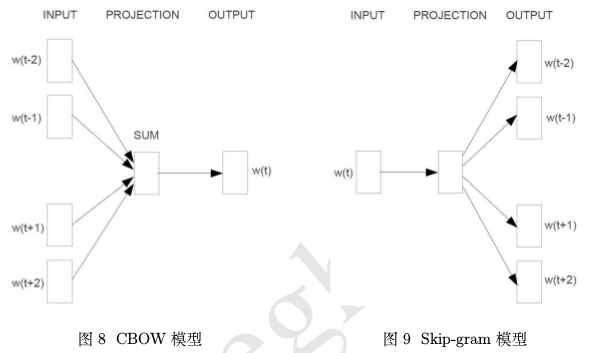
上图是word2vec中使用到的两种模型的示意图。
从图中可知,word2vec虽然使用了神经网络,但是从层数来说,只有3层而已,还谈不上是Deep Learning。但是考虑到DL,基本就是神经网络的同义词,因此这里仍然将word2vec归为DL的范畴。
深度学习不全是神经网络,周志华教授提出的gcForest就是一个有益的另类尝试。
研究一个神经网络模型,最重要的除了神经元之间的连接关系之外,就是神经网络的输入输出了。
CBOW(Continuous Bag-of-Words Model)模型和Skip-gram(Continuous Skip-gram Model)模型脱胎于n-gram模型,即一个词出现的概率只与它前后的n个词有关。这里的n也被称为窗口大小.
上图中,窗口大小为5,即一个中心词\(\{w_t\}\)+前面的两个词\(\{w_{t-1},w_{t-2}\}\)+后面的两个词\(\{w_{t+1},w_{t+2}\}\)。
| 名称 | CBOW | Skip-gram |
|---|---|---|
| 输入 | \(\{w_{t-1},w_{t-2},w_{t+1},w_{t+2}\}\) | \(\{w_t\}\) |
| 输出 | \(\{w_t\}\) | \(\{w_{t-1},w_{t-2},w_{t+1},w_{t+2}\}\) |
| 目标 | 在输入确定的情况下,最大化输出值的概率。 | 在输入确定的情况下,最大化输出值的概率。 |
参考:
https://zhuanlan.zhihu.com/p/27234078
通俗理解Word2Vec之Skip-Gram模型
https://mp.weixin.qq.com/s/reT4lAjwo4fHV4ctR9zbxQ
漫谈Word2vec之skip-gram模型
https://mp.weixin.qq.com/s/9YoeoSpeAXo-QryZ9rxfug
一文理解Skip-Gram上下文的预测算法
https://mp.weixin.qq.com/s/IzWq51xrTYdm5KSQBy7idA
Koan:一段来自彭博社的公案
Hierarchical Softmax
word2vec的输出层有两种模型:Hierarchical Softmax和Negative Sampling。
Softmax是DL中常用的输出层结构,它表征多分类中的每一个分类所对应的概率。
然而在这里,每个分类表示一个单词,即:分类的个数=词汇表的单词个数。如此众多的分类直接映射到隐层,显然并不容易训练出有效特征。
Hierarchical Softmax是Softmax的一个变种。这时的输出层不再是一个扁平的多分类层,而变成了一个层次化的二分类层。
Hierarchical Softmax一般基于Huffman编码构建。在本例中,我们首先统计词频,以获得每个词所对应的Huffman编码,然后输出层会利用Huffman编码所对应的层次二叉树的路径来计算每个词的概率,并逆传播到隐藏层。
由Huffman编码的特性可知,Hierarchical Softmax的计算量要小于一般的Softmax。
参考:
https://mp.weixin.qq.com/s/N1Yt_GK57-FXU-brfu6o8A
GPU上的高效softmax近似
Negative Sampling
在CBOW模型中,已知w的上下文Context(w)需要预测w,则w就是正样本,而其他词是负样本。
负样本那么多,该如何选取呢?Negative Sampling就是一种对负样本采样的方法。
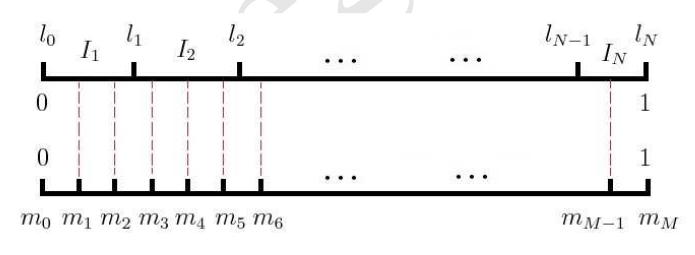
上图是Negative Sampling的原理图。L轴表示的是词频分布,很明显这是一个非等距剖分。而M轴是一个等距剖分。
每次生成一个M轴上的随机数,将之映射到L轴上的一个单词。映射方法如上图中的虚线所示。
除了word2vec之外,类似的Word Embedding方案还有SENNA、RNN-LM、Glove等。但影响力仍以word2vec最大。
Skip-Gram Negative Sampling,又被简称为SGNS。
doc2vec
我们知道,word是sentence的基本组成单位。一个最简单也是最直接得到sentence embedding的方法是将组成sentence的所有word的embedding向量全部加起来。
显然,这种简单粗暴的方法会丢失很多信息。
doc2vec是Mikolov在word2vec的基础上提出的一种生成句子向量的方法。
论文:
《Distributed Representations of Sentences and Documents》
http://cs.stanford.edu/~quocle/paragraph_vector.pdf
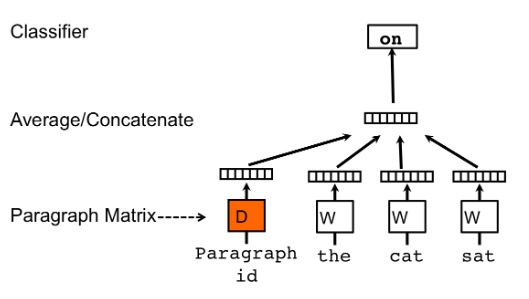
上图是doc2vec的框架图,可以看出doc2vec的原理与word2vec基本一致,区别仅在于前者多出来一个Paragraph Vector参与CBOW或Skip-gram的训练。
Paragraph Vector可以和Word Vector一起生成,也可以单独生成,也就是训练时,采用预训练的Word Vector,并只改变Paragraph Vector的值。
https://www.zhihu.com/question/33952003
如何通过词向量技术来计算2个文档的相似度?
https://mp.weixin.qq.com/s/x_y_yygV0L5FdqfKM9xzig
Doc2vec原理解析及代码实践
FastText
Word2Vec作者Mikolov加盟Facebook之后,提出了文本分类新作FastText。
FastText模型架构和Word2Vec中的CBOW模型很类似。不同之处在于,FastText预测标签,而CBOW模型预测中间词。
Github:
https://github.com/facebookresearch/fastText
FastText的论文其实有两篇:
《Bag of Tricks for Efficient Text Classification》
这篇就是上述文本分类的论文。
《Enriching Word Vectors with Subword Information》
这篇是根据词根改进词向量的论文。因此,有的blog说,使用FastText生成词向量,实际上就是指的这篇文章。
参考:
http://www.algorithmdog.com/fast-fasttext
超快的 fastText
https://mp.weixin.qq.com/s/tXgF7rQdZm3IFAluMU5ywg
fastText之源码分析
https://mp.weixin.qq.com/s/S4RGicXwZqis6vQFpB31qQ
Bag of Tricks for Efficient Text Classification
https://mp.weixin.qq.com/s/eq1I92rjIAWEpYw-1fEHeQ
从Facebook AI Research开源fastText谈起文本分类:词向量模性、深度表征和全连接
https://mp.weixin.qq.com/s/aq_kWkwgwtz5qFo0lNEEqg
Tomas Mikolov论文简评:从Word2Vec到FastText
https://mp.weixin.qq.com/s/v1-mLhmbp5MoRR824tdPDw
玩转词向量:用fastText预训练向量做个智能小程序
https://mp.weixin.qq.com/s/LLrq1F2uEC2xEWZrd9uijA
一行代码自动调参,支持模型压缩指定大小,Facebook升级FastText
https://mp.weixin.qq.com/s/VxODwO8qA33Cr1n62YXYBQ
fastText:极快的文本分类工具
https://mp.weixin.qq.com/s/TRrL6_nI4GimH_OJ1CswiQ
NLP重铸篇之Fasttext
RNNLM
RNNLM是Mikolov早期提出的文本分类的工具。(其实就是他的博士毕业论文)
官网:
http://rnnlm.org/
yandex后来又提出了一个加速版本的RNNLM:
https://github.com/yandex/faster-rnnlm
Item2Vec
本质上,word2vec模型是在word-context的co-occurrence矩阵基础上建立起来的。因此,任何基于co-occurrence矩阵的算法模型,都可以套用word2vec算法的思路加以改进。
比如,推荐系统领域的协同过滤算法。
协同过滤算法是建立在一个user-item的co-occurrence矩阵的基础上,通过行向量或列向量的相似性进行推荐。如果我们将同一个user购买的item视为一个context,就可以建立一个item-context的矩阵。进一步的,可以在这个矩阵上借鉴CBoW模型或Skip-gram模型计算出item的向量表达,在更高阶上计算item间的相似度。
论文:
《Item2Vec: Neural Item Embedding for Collaborative Filtering》
在实际的新闻信息流推荐中,Word2Vec的点击效果比ALS要好30%+,主要有两个原因:
-
用户的兴趣和行为是多样的,局部的行为往往更偏相关,往往整体的样本差异是很大的;
-
在负样本采样中,ALS 是全局的负样本采样,Word2Vec 更倾向高频,倾向高频的采样更不容易让学习出的结果都与高频(头部)的结果相似。
参考:
https://mp.weixin.qq.com/s/vpxCP1Uw23y9XNTRUhY79w
达观数据推荐算法实现:协同过滤之item embedding
https://www.sohu.com/a/215535516_99992181
有这好事?神经网络模型Word2vec竟能根据个人喜好推荐音乐
https://mp.weixin.qq.com/s/Ta2Im4WCWq5eQ8SF-mNpuQ
万物皆Embedding,从经典的word2vec到深度学习基本操作item2vec
https://mp.weixin.qq.com/s/6XJuZBTmfRWWFwS9J3HOsQ
推荐技术随谈
word2vec/doc2vec的缺点
1.word2vec/doc2vec基于BOW(Bag Of Word,词袋)模型。该模型的特点是忽略词序,因此对于那些交换词序会改变含义的句子,无法准确评估它们的区别。
2.虽然我们一般使用word2vec/doc2vec来比较文本相似度,但是从原理来说,word2vec/doc2vec提供的是关联性(relatedness),而不是相似性(similarity)。这会带来以下问题:不但近义词的词向量相似,反义词的词向量也相似。因为它们和其他词的关系(也就是语境)是类似的。
3.由于一个词只有一个向量来表示,因此,无法处理一词多义的情况。
然而关联性并非都是坏事,有的时候也会起到意想不到的效果。比如在客服对话的案例中,客户可能会提供自己的收货地址,显然每个客户的地址都是不同的,但是有意思的是,这些地址的词向量是非常相似的。
总之,只利用无标注数据训练得到的Word Embedding在匹配度计算的实用效果上和主题模型技术相差不大,它们本质上都是基于共现信息的训练。
4.除了余弦相似度之外,词向量的模长,也是一个重要的特征,词向量模长越大,重要性越低(或者越高,取决于生成词向量的算法)。
参考:
https://www.zhihu.com/question/22266868
Word2Vec如何解决多义词的问题?
参考
http://www.cnblogs.com/iloveai/p/word2vec.html
word2vec前世今生
https://mp.weixin.qq.com/s/NMngfR7EWk-pa6c4_FY9Yw
图解Word2vec,读这一篇就够了
http://www.cnblogs.com/maybe2030/p/5427148.html
文本深度表示模型——word2vec&doc2vec词向量模型
https://www.zhihu.com/question/29978268
如何用word2vec计算两个句子之间的相似度?
https://mp.weixin.qq.com/s/kGi-Hf7CX6OKcCMe7IC7zA
NLP之Wrod2Vec三部曲
https://mp.weixin.qq.com/s/VMK_UpOUI0y7apTGR02D1Q
图解Word2Vec
https://mp.weixin.qq.com/s/CMcNkEFW9UUXAW0832dT6g
对学习/理解Word2Vec有帮助的材料
https://mp.weixin.qq.com/s/XMGZXAt_LUX5iTet7_SX4Q
深度学习和自然语言处理:诠释词向量的魅力
https://mp.weixin.qq.com/s/Rn_aJYozQ0f53Mjq4MKSwA
哪种词向量模型更胜一筹?Word2Vec,WordRank or FastText?
https://mp.weixin.qq.com/s/H7m7lqWpK27pJp9obXxlIQ
见微知著,从细节处提升词向量的表示能力
http://licstar.net/archives/328
词向量和语言模型
http://geek.csdn.net/news/detail/135736
漫谈词向量之基于Softmax与Sampling的方法

您的打赏,是对我的鼓励
