DL Framework » Pytorch(一)
2018-01-16 :: 6585 WordsPytorch
概述
Torch是一个非常老牌的DL框架,它的历史可以追溯至2003年,几乎是现存框架中最古老的了。
官网:
http://torch.ch/
Torch采用Lua语言编写,这和目前ML/DL界主流的python有较大差别。
因此,Facebook和Uber联合于2016年推出了Torch的python版本——Pytorch。由于Pytorch在开发者社区更受欢迎,短短时间它的开发进度就超越了Torch,成为了2017年DL的年度语言。
官网:
https://pytorch.org/
和TensorFlow主要面向工业界不同,Pytorch的抽象更为傻瓜,类似于Keras,但也提供了TensorFlow式的基本运算功能,更适合学术界的使用。当然了,它的效率和可扩展性,是不如TensorFlow的。
文档:
https://pytorch.org/docs/stable/index.html
官网教程:
http://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html
还有一个非官网的教程,一个韩国人写的:
https://github.com/yunjey/pytorch-tutorial
Model Zoo(非官方):
https://github.com/Cadene/pretrained-models.pytorch
官方书籍:
https://pytorch.org/deep-learning-with-pytorch-thank-you
安装
Pytorch的安装方法在官网首页就可查到,非常方便。
https://pytorch.org/get-started/locally/
这是我的平台的安装方法:
pip3 install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp36-cp36m-linux_x86_64.whl
pip3 install torchvision
测试:
import torch
torch.cuda.is_available()
参考:
https://zhuanlan.zhihu.com/p/44068797
Windows装TensorFlow+MXNet+PyTorch
编译
conda install cmake ninja
pip install -r requirements.txt
conda install mkl mkl-include
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursive
# CPU only
export USE_CUDA=0
export _GLIBCXX_USE_CXX11_ABI=1
# CUDA
export CMAKE_CUDA_ARCHITECTURES=86
export CMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc
export CMAKE_BUILD_PARALLEL_LEVEL=4 # set build threads num
python setup.py develop
python setup.py develop会在python环境中建立指向源代码build路径的符号链接,这样修改代码也无需重新安装wheel包了,如果想体验完整流程可以使用python setup.py install。
python setup.py bdist_wheel:生成wheel包,一般放在dist路径下。
使用python setup.py develop,且在同一python env下,多次切换多份代码的时候。需要留意site-packages路径或者它的父目录下的.pth文件。
.pth文件会改变sys.path,从而导致torch包指向并不期望的旧代码路径。
示例
Lenet+MNIST+GPU:
https://github.com/antkillerfarm/antkillerfarm_crazy/tree/master/python/ml/pytorch/mnist_gpu.py
项目
https://github.com/CSAILVision/semantic-segmentation-pytorch
Semantic Segmentation PyTorch:PyTorch上最好的语义分割工具包
https://github.com/PetrochukM/PyTorch-NLP
支持快速成型的深度学习NLP工具包
fastai
fastai和Pytorch的关系,类似于Keras和Tensorflow。
参考:
https://mp.weixin.qq.com/s/kEC-5huq6cFjd1iPjSuK-g
5行代码秀碾压,比Keras还好用的fastai来了,尝鲜PyTorch 1.0必备伴侣
QNNPACK
QNNPACK (Quantized Neural Networks PACKage) 是 Marat Dukhan (Facebook) 开发的专门用于量化神经网络计算的加速库。其卓越的性能表现一经开源就击败了几乎全部已公开的加速算法,甚至直至今日(2019 年中)。
它已经集成到pytorch中。
代码:
https://github.com/pytorch/qnnpack
参考:
https://mp.weixin.qq.com/s/30cxIX9aKIpELC8H4_k8Gg
比TFLite快2倍!FB开源移动深度学习优化库QNNPACK
https://zhuanlan.zhihu.com/p/81026071
神经网络加速库QNNPACK实现揭秘
模型保存
经常会看到后缀名为.pt,.pth,.pkl的pytorch模型文件,其实它们并不是在格式上有区别,只是后缀不同而已(仅此而已)。.pkl文件是python里面保存文件的一种二进制格式,用pickle库去加载pkl文件或pth文件,效果都是一样的。
https://www.jianshu.com/p/e37e4e49dbc1
pytorch模型保存方式(.pt, .pth, .pkl)
模型处理
https://github.com/antkillerfarm/antkillerfarm_crazy/blob/master/python/ml/pytorch/pytorch_hook.py
上面的示例包含以下内容:
1.如何使用hook打印中间层的输出。
2.如何截取模型的一部分,并执行。
3.量化模型的输入和输出有一个Quantize和Dequantize的过程。而且这两个过程由于是后期加入的,因此在print(model)中被排在最后。可见model结构中的顺序,并不是真正的执行顺序的拓扑排序。
参考:
https://blog.csdn.net/Pl_Sun/article/details/106978171
PyTorch中的model.modules(), model.children(), model.named_children(), model.parameters(), model.nam…
https://www.jianshu.com/p/d2a066e05078
pytorch拆分已定义的网络结构(slicing network)
代码解读
PyTorch的代码主要由C10、ATen、torch三大部分组成。其中:
-
C10,Caffe Tensor Library的缩写。这里存放的都是最基础的Tensor库的代码,可以运行在服务端和移动端。PyTorch目前正在将代码从ATen/core目录下迁移到C10中。C10的代码有一些特殊性,体现在这里的代码除了服务端外,还要运行在移动端,因此编译后的二进制文件大小也很关键。
-
ATen,A TENsor library for C++11的缩写;PyTorch的C++ tensor library。ATen部分有大量的代码是来声明和定义Tensor运算相关的逻辑的,除此之外,PyTorch还使用了aten/src/ATen/gen.py来动态生成一些ATen相关的代码。
-
Torch,部分代码仍然在使用以前的快要进入历史博物馆的Torch开源项目。
CNN format
Pytorch默认支持NCHW格式的数据,这与Caffe相同。
op
Pytorch目前已经和Caffe2合并,所以相关op的代码在caffe2/operators下。一般XXX_op.h包含了CPU实现,而XXX_op.cu包含GPU实现。
xxx_stub
xxx_kernel
xxx_kernel_impl
Conv Backprop
caffe2/operators/conv_op_impl.h: ConvGradientOp::RunOnDeviceWithOrderNCHW
caffe2/utils/math.h: Gemm
caffe2/utils/math_cpu.cc: Gemm
Eigen or cblas_sgemm
// calc the cost of ConvGradient
caffe2/operators/conv_gradient_op.cc: CostInferenceForConvGradient
// cuDNN
cudnnGetConvolutionBackwardDataAlgorithm_v7
参考
https://mp.weixin.qq.com/s/rCocDz2kW2tpkZel5Wh-hw
Pytorch网络结构可视化
https://mp.weixin.qq.com/s/0VNTBY1KrOXBldRoi1Ky5A
Pytorch autograd,backward详解
https://zhuanlan.zhihu.com/p/55966063
PyTorch ATen代码的动态生成
https://zhuanlan.zhihu.com/p/56924766
PyTorch Autograd代码的动态生成
https://fkong.tech/posts/2023-05-24-torch-source/
一点PyTorch源码阅读心得
https://pytorch.org/blog/a-tour-of-pytorch-internals-1/
A Tour of PyTorch Internals (Part I)
https://pytorch.org/blog/a-tour-of-pytorch-internals-2/
PyTorch Internals Part II - The Build System
tensorboardX
Pytorch并没有一个比较好的可视化库。所谓的torchvision实际上是一个用于CV领域的工具库,和可视化一点关系都没有。
而tensorboardX项目,提供了导出Pytorch模型到tensorboard的功能。这样,Pytorch项目也可以使用tensorboard作为可视化工具。
官网:
https://github.com/lanpa/tensorboardX
文档:
https://tensorboardx.readthedocs.io/en/latest/tensorboard.html
参考:
https://mp.weixin.qq.com/s/Zxoug2sMoWsOWnZPCQ22ug
PyTorch模型训练特征图可视化(TensorboardX)
torchinfo
torchinfo提供了类似TF的model.summary()的功能。
代码:
https://github.com/TylerYep/torchinfo
在torchinfo之前还有一个叫torch-summary的项目也提供了类似功能。而torchinfo正是它的后继者。
Torch Vision
代码:
https://github.com/pytorch/vision
JIT
动态图:其核心特点是计算图的构建和计算同时发生(Define by run)。
静态图:将计算图的构建和实际计算分开(Define and run)。
pytorch支持scripting/trace两种模式动态图转静态图的方法。
PyTorch在前向执行过程中会执行轨迹相关的记录。这种方式我们通常会称为tracing,就是代码实际执行一遍,隐藏在其后的数据流计算图(DataFlow Graph)就很容易得到了。但是这种方式会由于输入不一样,每次的trace可能不一样! 这就是动态图。
动态图+Trace:通过追溯输出(比如损失值、预测值)所依赖的网络结构,得到整体的计算图,再进行编译。
静态图+Eager:直接迭代和直观调试,Eager模式下求解梯度与自定义训练。
前者无法真正做到静态图的优化,而是一种折中策略,而后者则是完全开发了一套不同的API书写方法,也是Tensorflow 2.x版本饱受诟病的核心原因。
https://www.cnblogs.com/isumi/p/18838496
Pytorch Eager Mode
神经网络编译器主要考虑如何把Eager表达转换到图层的IR进行优化,目前主要有两种方式:
AST-Based:以Pytorch TorchScript为例,主要通过Python的修饰符,把Python代码的AST拿到,然后变换成图层的IR,进行编译优化。
Tracing-Based:以JAX为例,主要把Python代码假执行一遍,保存执行序列,基于执行序列变换到图层IR进行编译优化。
两种方案各有优缺点,第一种方案实现复杂,第二种方案在一些处理上有限制(比如控制流的处理)。
参考:
https://blog.csdn.net/ljp1919/article/details/102514357
在生产环境中基于PyTorch的C++API运行模型-以图像分类为例
https://blog.csdn.net/xxradon/article/details/86504906
pytorch JIT浅解析
https://www.zhihu.com/question/326862986
Pytorch实现动态图执行的原理和机制是什么?
TorchDynamo
PyTorch 1.0对追踪模型图结构(graph capture)这件事也付出了很多的努力,例如torch.jit.trace/script,torch.fx等,但是无一例外,上述各种graph capture方法其使用手感只能用一言难尽来形容。
因此PyTorch痛定思痛,终于在年底搞了个大新闻,在2.0里推出了他们新一代的trace工具Dynamo。
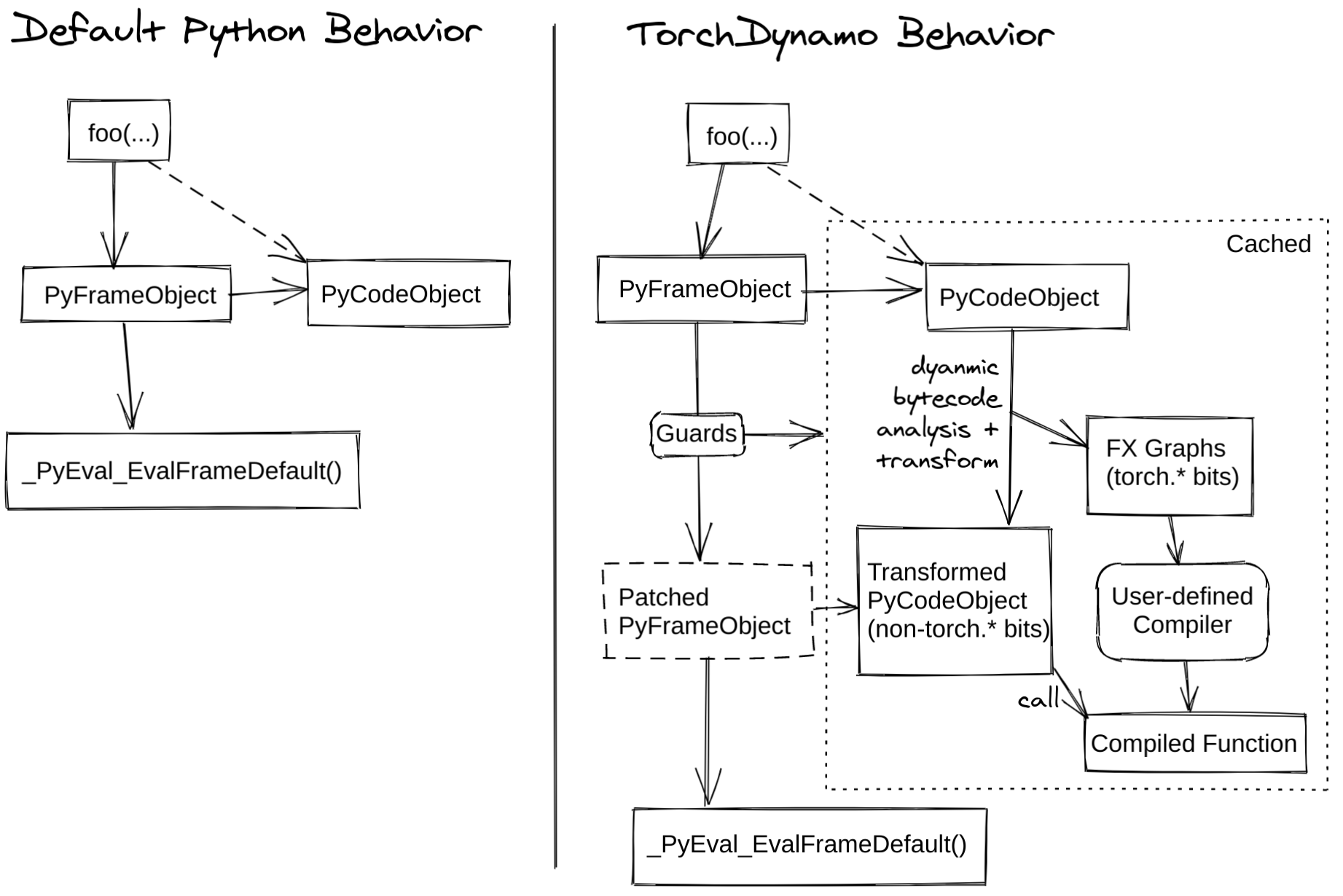
简单来说,TorchDynamo就是一种嵌入在Python解释器里面的JIT优化器。
文档:
https://pytorch.org/docs/2.0/dynamo/index.html

您的打赏,是对我的鼓励
