DL Framework » TF XLA(一)
2022-06-23 :: 6816 WordsFused Graph
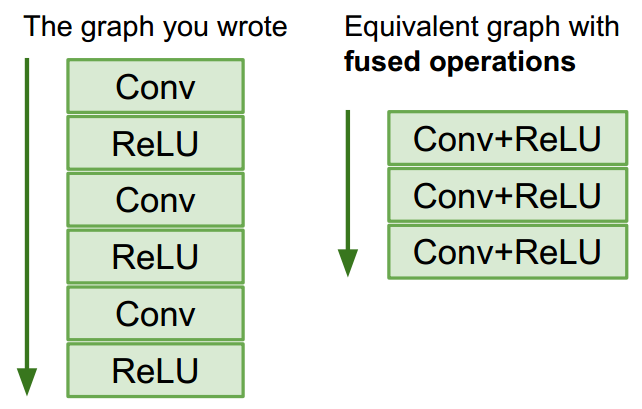
Fused Graph是TensorFlow新推出的概念。这里仍以softmax运算为例,讲一下它的基本思想。
上面的softmax运算计算图中,总共有4个operation。Fused Graph则将这4个op整合为1个op,发给运算单元。
这样不同的硬件厂商就可以自行对这个整合的op进行解释。功能强的硬件,可能直接就支持softmax运算。功能弱的硬件也不怕,反正总归可以将softmax分解为基本运算的。
Qualcomm Hexagon平台的Fused Graph实现可参见:
tensorflow/core/kernels/hexagon
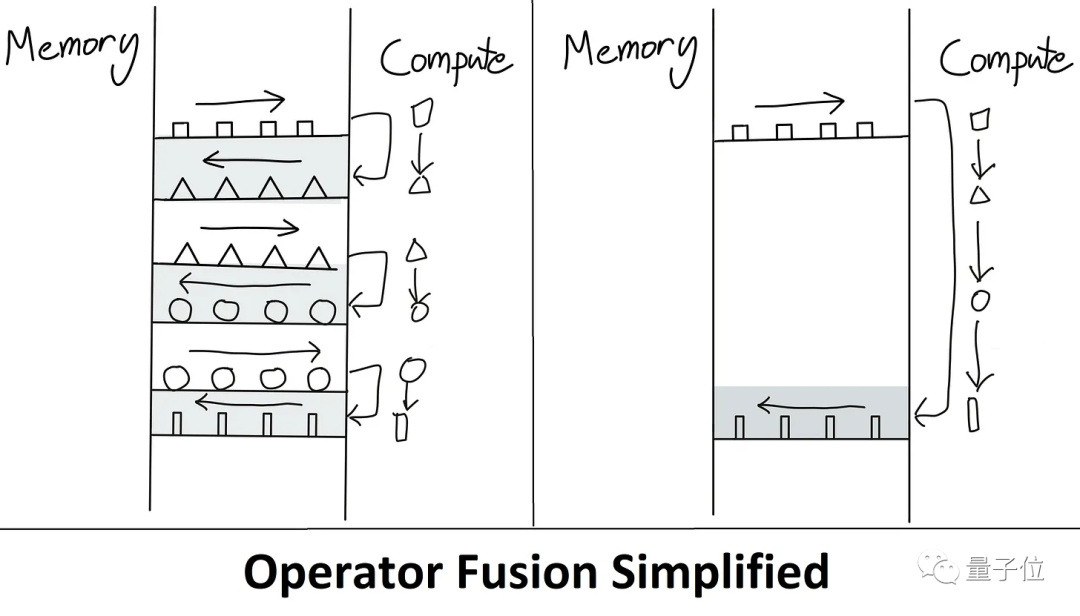
上图是另一个计算图优化的例子。
参考:
https://developers.googleblog.com/2017/03/xla-tensorflow-compiled.html
XLA - TensorFlow, compiled
XLA
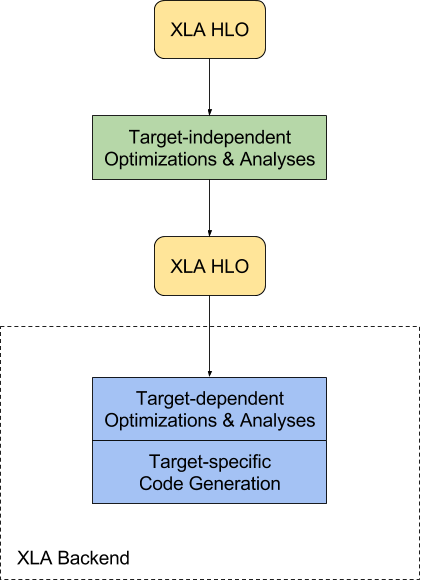
XLA(Accelerated Linear Algebra)是TensorFlow计算图的编译器。
官网:
http://tensorflow.google.cn/xla?hl=zh-cn
基本架构:
http://tensorflow.google.cn/xla/architecture
TFE: Tensorflow Eager
https://github.com/dongbeiyewu/xla.git
一个XLA的专栏
应用层
TF目前(v2.4.1)的默认编译选项中已经包含了XLA,但是默认不会启动。
启动方法:
- 手动启动
设置环境变量:
TF_XLA_FLAGS="--tf_xla_enable_xla_devices"
手动指定需要XLA计算的op:
with tf.device("/device:XLA_CPU:0"):
...
这种方法的缺点是:代码需要修改,且XLA不支持有些复杂的op。
- 自动启动
TF_XLA_FLAGS="--tf_xla_auto_jit=2 --tf_xla_cpu_global_jit"
代码无需修改。
HLO


XLA用HLO(High Level Optimizer)这种中间表示形式,表示正在被优化的计算图。
三个概念,hlo module, computation, instruction。
- hlo module用源码注释的解释,就是一个编译单元,相当于是一个完整可运行的程序。既然是一个程序,就有入口函数,也就是entry_computation,每个module都有且仅有一个entry_computation,相当于main函数,有输入和输出,输入可以是多个参数,但输出只有一个(即root instruction),如果要返回多个值,则需要把多个值构造成一个元组(tuple),并将该元组设置为root instruction。
- 一个module可以包含多个computation,除了entry_computation,其他的都是”nested”,也就是被调用。
- HLO instructions就是op了,对应了官网上列出的operation semantics,看注释已经解释的非常清楚了,op融合和向llvm ir转换都是在这个层面进行的。
op的官方定义:
https://openxla.org/xla/operation_semantics?hl=en
HLO和TVM类似,计算图的遍历都是从所谓的root instruction,也就是输出Tensor开始的。但是实际的HandleXXXX的调用,却是从输入Tensor开始的,毕竟这个更符合一般人的思考习惯。想要做到这一点,也不难,采用PostOrderDFS即可。
graph compile -> hlo graph build -> hlo pass pipelime -> hlo dataflow analysis -> codegen
参考:
https://zhuanlan.zhihu.com/p/71980945
tensorflow xla hlo基本概念和pass pipeline
HloInstruction和HloComputation的互操作
hlo_inst->parent():hlo_inst所属的HloComputation。
hlo_computation->root_instruction():hlo_computation的root instruction。
hlo_computation->instructions():hlo_computation的所有的instruction。
hlo_inst->operands():hlo_inst的输入tensor,或者说是它的prev。
hlo_inst:hlo_inst的输出tensor。
hlo_inst->users():hlo_inst的使用者,或者说是它的next。
从TF到HLO
一个op从上到下一般有这样几个步骤:
TF op -> XLA op -> HLO op
- TF op -> XLA op:
tensorflow/python/ops/nn_ops.py
conv2d
gen_nn_ops.conv2d
_op_def_library._apply_op_helper("Conv2D")
- XLA op -> HLO op:
tensorflow/compiler/tf2xla/kernels/conv_ops.cc
REGISTER_XLA_OP(Name("Conv2D"), Conv2DOp);
ConvOp::Compile
MakeXlaForwardConvOp
HandleConvolution
底层实现
XLA支持两种接入模式:
- AOT。compiler/aot/
用于在Tensorflow应用运行前创建集成了模型和运行时的二进制代码,主要适用于手机等移动端的推理性能优化。AOT方式使用XLA,通过tfcompile命令实现。
- JIT。compiler/jit/
这是最常用的模式。以JIT的方式将tf2xla/接入TF引擎, 核心是9个优化器和3个tfop,其中XlaCompileOp调用tf2xla的“编译”入口完成功能封装,XlaRunOp调用xla/client完成“运行”功能。
将整个计算图用_XlaCompile & _XlaRun替换。
compiler/tf2xla/ -> compiler/xla/client/ -> compiler/xla/service/
最终的计算由service负责实现。
compiler/tf2xla/
xla_compiler.cc: XlaCompiler::CompileFunction()供jit:compile_fn()使用将cluster转化为XlaComputation。核心是利用xla/client提供的接口,实现对XlaOpKernel的“Symbolic Execution”功能。每个XlaOpKernel子类均做的以下工作: 从XlaOpKernelContext中取出XlaExpression或XlaOp,调用xla/client/xla_buidler.h提供的方法完成计算,将计算结果的XlaOp存入XlaKernelContext。
compiler/xla/client/
xla_builder.cc: Builder等供CompileFunction()使用,将Graph由Op表达转化为HloModuleProto:HloComputationProto:HloInstructionProto表达并保存在XlaComputation中。
local_client.cc: LocalClient::Compile(),作为编译入口供jit:BuildExecutable()使用,将已经得到的XlaComputation交给service并进一步编译为二进制。
local_client.cc: LocalExecutable::Run(),作为运行入口供jit/kernels/xla_ops.cc:XlaRunOp使用,通过Key找到相应的二进制交给service层处理。
compiler/xla/service/
local_service.cc: LocalService::BuildExecutable()供LocalClient::Compile()使用实现真正的编译,承接XlaComputation封装的HloProto,将其转化为HloModule:HloComputation:HloInstruction表达,对其进行优化之后,使用LLVM后端将其编译为相应Executable后端的二进制代码。
executable.cc: Executable::ExecuteOnStream()供LocalExecutable::Run()使用实现真正的执行二进制。
StreamExecutor
EagerExecutor::SyncExecute
Status s = node->Prepare();
s = node->Run();
EagerExecutor::Run
ExecuteNode::Run
EagerKernelExecute
KernelAndDevice::Run
XlaCompileOnDemandOp::Compute
XlaCompileOnDemandOp::Run
LocalExecutable::Run
LocalExecutable::RunAsync
Executable::ExecuteAsyncOnStreamWrapper
backward
tensorflow/core/ops/nn_grad.cc:
REGISTER_OP_GRADIENT("BiasAdd", BiasAddGrad);
tensorflow/compiler/tf2xla/g3doc/gpu_supported_ops.md
CanonicalizeBackwardFilterConvolution
Conv2DBackpropFilter
GetKnownXLAWhitelistOp
XlaOpRegistry::GetAllRegisteredOps
REGISTER_XLA_OP
HloInstruction::Visit
class ConvBackpropFilterOp : public XlaOpKernel
MakeXlaBackpropFilterConvOp
ConvGeneralDilated
https://discuss.tvm.apache.org/t/rfc-mlir-frontend/6473
backend
官方backend:
tensorflow/compiler/xla/service
第三方的XLA backend接入:
tensorflow/compiler/plugin
第三方的XLA backend中,比较出名的是graphcore。
它的TF实现:
https://github.com/graphcore/tensorflow/tensorflow/compiler/plugin/poplar
XLA的主要目的是方便硬件厂商更好的适配tensorflow。因此,作为XLA基础的HLO,其op数非常少,仅有不到100个。用户只要实现了这些op,就可以接入tf了——其他不支持的tf op,都被分解为简单的HLO op。
HloTransposeInstruction
HandleTranspose
HLO op的弊端是颗粒度太细,导致执行效率不高。因此,XLA还提供了高级op的注册功能,主要是用xla::CustomCall来实现。
MaxPool2DGradOp
REGISTER_XLA_OP(Name("MaxPoolGrad").Device(DEVICE_IPU_XLA_JIT),
MaxPool2DGradOp);
xla::CustomCall(&b, PoplarOp_Name(PoplarOp::MaxPoolGrad), args,
input_shape, attribute_map_.Serialise());
首先派生一个XlaOpKernel,还要派生一个HloCustomCallInstruction,最后再到HandleCustomCall去接收相关的图信息。
model test:
tensorflow/compiler/plugin/poplar/docs/example_tf2_model_fit.py
op register & filter
REGISTER_XLA_BACKEND(DEVICE_VSI_NPU_XLA_JIT, GetNpuSupportedTypes(), OpFilter);
上例用于设置backend支持的数据类型(以下简称为类型集合A)和op类型。这里的OpFilter用于打开XLA op到HLO op的开关,否则即使对应的HLO op已经被支持,计算也不会被分配到NPU上。
当然这个设置比较粗糙了,比如某个op只支持部分数据类型,该怎么做呢?
REGISTER_XLA_OP(Name("Conv2DBackpropInput")
.Device(DEVICE_XLA_NPU)
.TypeConstraint("T", GetXlaConvTypes()),
Conv2DBackpropInputOp);
同一个op允许有多个kernel来提供支持,只要他们的设置不同即可。比如上例就是一个NPU设备的kernel。如果不指定Device,则该Kernel为所有backend共用。
上面的T是所谓的Attr,它的名字可以在op定义里查到,例如下例:
REGISTER_SYSTEM_OP("_Arg")
.Attr("T: type")
需要指出的是,TypeConstraint里设置的类型,必须在类型集合A之内,才能生效。实际上就是对类型集合A做减法。
如果某个op需要的类型不在`类型集合A时(也就是对类型集合A做加法),就需要有特殊的技巧了。正好TF里就有类似的范例:
if (op_registration->allow_string_type) {
allowed_values->add_type(DT_STRING);
}
这个技巧是有实际意义的,比如某个数据类型如果只用在个别op上的话,给大多数op做减法,就不如给这几个个别的op做加法了。
在REGISTER_XLA_BACKEND之外,还有诸如REGISTER_XLA_DEVICE_KERNELS之类的宏,他们使用类型集合的全集就好。只有REGISTER_XLA_BACKEND需要做加法,也只有这个宏会影响Placer的行为,其他宏都和Placer无关。
上述OpFilter开关一旦打开,则所有计算无论计算量的大小,都会被派发到NPU上,然而有些计算图实在过于微小,在CPU上的计算时间,甚至小于调度到NPU上的时间。
针对这个问题,在graphcore的tf实现中,有LiteralEvaluateForScalarElementwiseGraph函数,用于回退到CPU上。其关键点在于:
HloEvaluator hlo_evaluator(1);
TF_ASSIGN_OR_RETURN(Literal literal_evaluate,
hlo_evaluator.Evaluate(*comp, arg_literals));
HloEvaluator中已经有了一套默认的CPU实现。

您的打赏,是对我的鼓励
