DL acceleration » 并行 & 框架 & 优化(五)——DeepSpeed, Sequence Parallel, Context Parallel, LoRA, FSDP
2023-11-06 :: 6024 WordsDeepSpeed
显存内容可分为两类:
- 模型状态(model states): 模型参数(fp16)、模型梯度(fp16)和Adam状态(fp32的模型参数备份,fp32的momentum和fp32的variance)。假设模型参数量为\(\Phi\),则共需要\(2\Phi+2\Phi+(4\Phi+4\Phi+4\Phi)=16\Phi\)字节存储,可以看到,Adam状态占比75%。
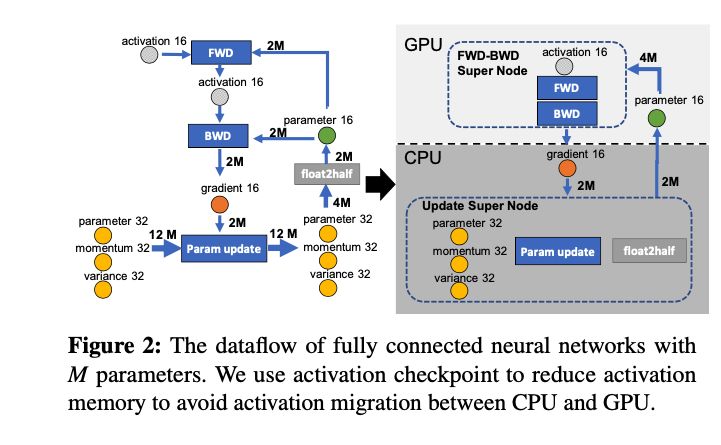
- 剩余状态(residual states): 除了模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
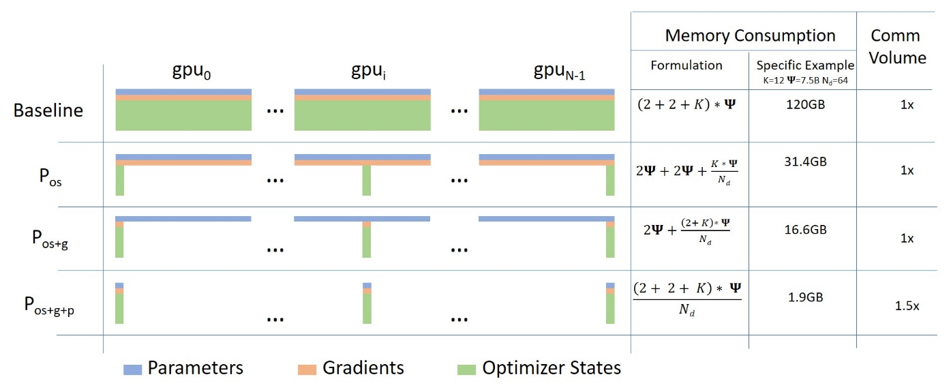
ZeRO使用分片(partition)方法,即每张卡只存1/N的模型状态量。
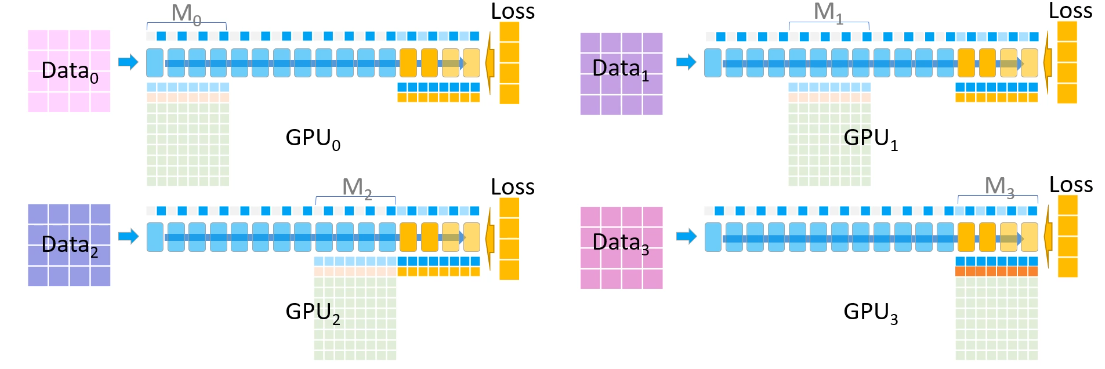
除了模型参数必须广播到各节点之外,模型梯度可以由各节点自己生成,然后再将之Reduce到保存数据的节点(即上图中的GPU 3)中。
只有模型梯度,由于来自不同的Data,需要各节点的同步,其他的Adam状态数据均与Data无关,由各节点自行计算更新即可。
代码:
https://github.com/microsoft/DeepSpeed
示例:
https://github.com/microsoft/DeepSpeedExamples
stage 1 & 2的代码在:
deepspeed/runtime/zero/stage_1_and_2.py
官网:
https://www.deepspeed.ai
DeepSpeed提供了PDSH、OpenMPI、MVAPICH三种方式在多机多卡模式下运行模型。
PDSH:Parallel Distributed Shell
添加backend:
accelerator/cuda_accelerator.py
训练时并行选择,顺序如下:
-
纯DP
-
DP + zero-1
-
分模型
如果每个DP的梯度累加步数足够大:DP + PP + zero-1
如果每个DP的梯度累加步数较小: DP + TP+ zero-1
- DP + PP + TP + zero-1
TP:机内
PP:机器间
zero-2/3和accumulate gradients是有冲突的,两者同时使用,效率反而会更低。所以只有在不使用accumulate gradients的时候,才采用zero-2/3。
参考:
https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters
ZeRO & DeepSpeed
https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
DeepSpeed: Extreme-scale model training for everyone
https://mp.weixin.qq.com/s/Vb3AkoWHQY7WWBMZaVnf4g
微软发布DeepSpeed开源库,支持1000亿个参数模型的训练
https://zhuanlan.zhihu.com/p/621379646
人手一个ChatGPT!微软DeepSpeed Chat震撼发布,一键RLHF训练千亿级大模型
https://zhuanlan.zhihu.com/p/513571706
DeepSpeed之ZeRO系列:将显存优化进行到底
https://zhuanlan.zhihu.com/p/630734624
deepspeed入门教程
https://zhuanlan.zhihu.com/p/576673548
深度学习大模型训练–DeepSpeed源码解读
https://zhuanlan.zhihu.com/p/626420999
deepspeed chat代码解读
GSPMD
GSPMD是在GShard基础上发展而来的并行算法。
《GSPMD:General and Scalable Parallelization for ML Computation Graphs》
Sequence Parallel

MegatronLM提出的Sequence Parallel算法,由于TP和SP交替进行,又被称为TP-SP算法。
对于Attention+MLP采用TP,对于其他部分采用SP。
推理阶段由于weight固定,所以每次生成token的时候,之前的计算大部分可以复用,只需要计算新token引入的那部分计算即可。
然而训练阶段,由于weight可变,即使是input+已生成token不变,也需要重新参与前后向计算。这时就需要SP了。
https://blog.csdn.net/qinduohao333/article/details/131629428
详解MegatronLM序列模型并行训练(Sequence Parallel)
通用性较强的Ulysses,在小规模或长序列上表现更好。
《DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models》

图中N表示序列长度,d表示hidden_size=(hc * hs),hc = head_cnt,hs=head_size,P表示GPU数目(图中 P=4)。红色虚线表示通信,黑色虚线表示计算。
DS-Ulysses 对Q、K、V沿着N维度切分成P份,三个分布式矩阵通过All2All变成沿d维度切分了。All2All等价于一个分布式转置操作。之后就是正常的\(softmax(QK^T)V\)计算,可以用 FlashAttention加速,得到结果再通过All2All转置回来。

和DeepSpeed Ulysses同期的SP方案还有Ring-Attention:
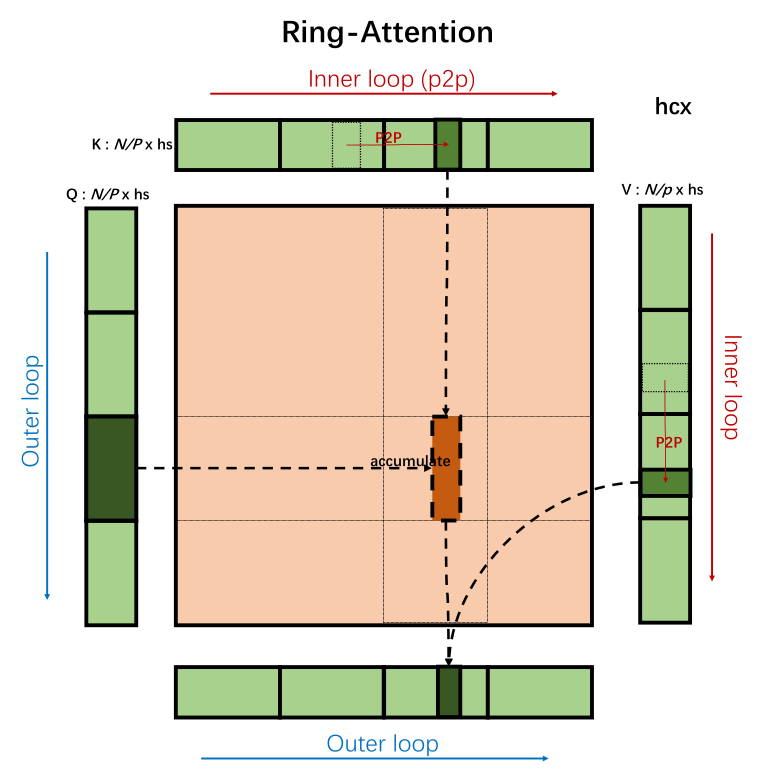
图中的P2P是point to point的意思,Ring-Attention不需要集合通信,取而代之的是相邻结点的P2P通信。
https://zhuanlan.zhihu.com/p/689067888
大模型训练之序列并行双雄:DeepSpeed Ulysses和Ring-Attention
https://zhuanlan.zhihu.com/p/703669087
我爱DeepSpeed-Ulysses:重新审视大模型序列并行技术
https://zhuanlan.zhihu.com/p/707204903
图解序列并行云台28将(上篇)
https://zhuanlan.zhihu.com/p/707435411
图解序列并行云台28将(云长单刀赴会)
https://zhuanlan.zhihu.com/p/707499928
图解序列并行云台28将(下篇)
FastSeq,它能将qkv projection的计算和all-gather通信重叠,只需多占用一点内存就可更进一步提升训练效率。
《FastSeq: Make Sequence Generation Faster》
Context Parallel
SP只针对Layernorm和Dropout输出的activation在sequence维度上进行切分,CP则是对所有的input输入和所有的输出activation在sequence维度上进行切分,可以看成是增强版的SP。

https://blog.csdn.net/qinduohao333/article/details/139250852
Context Parallel
LoRA
LoRA: Low-Rank Adaptation of Large Language Models是微软研究院引入的一项新技术,主要用于处理大模型微调的问题。
lora模型可以简单理解为在基础模型之上的一个补丁模型,用来训练特定风格、特定人物、特定动作等效果。因为基础模型提供了强大的通用能力,但对于指定人物、或者特定的一种风格掌握的并不精,所以需要lora模型来针对性学习下特定领域的效果。
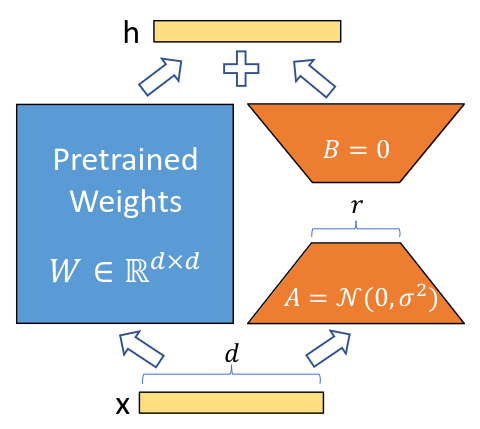
上图为LoRA的实现原理,其实现流程为:
-
在原始预训练语言模型旁边增加一个旁路,做降维再升维的操作来模拟内在秩;
-
用随机高斯分布初始化A,用零矩阵初始化B,训练时固定预训练模型的参数,只训练矩阵A与矩阵B;
-
推理的时候,只需要更新\(W=W_0+BA\)即可。
由于A和B的数据量极小,有的时候也会只发布A和B。用户将之下载之后,自行更新base model即可。这就相当于是model的patch。
由此还衍生出一种用法,一个base model + 若干针对不同领域/任务的patch,就可以服务于多个不同的领域/任务。
LoRA大幅降低了模型训练时的显存占用,因为并不优化主模型,所以主模型对应的优化器参数不需要存储。但计算量没有明显变化——虽然减少了主模型更新权重的计算,但却增加了旁路的正向和反向计算。
代码:
https://github.com/microsoft/LoRA
fine tune的示例:
examples/NLG/src/gpt2_ft.py
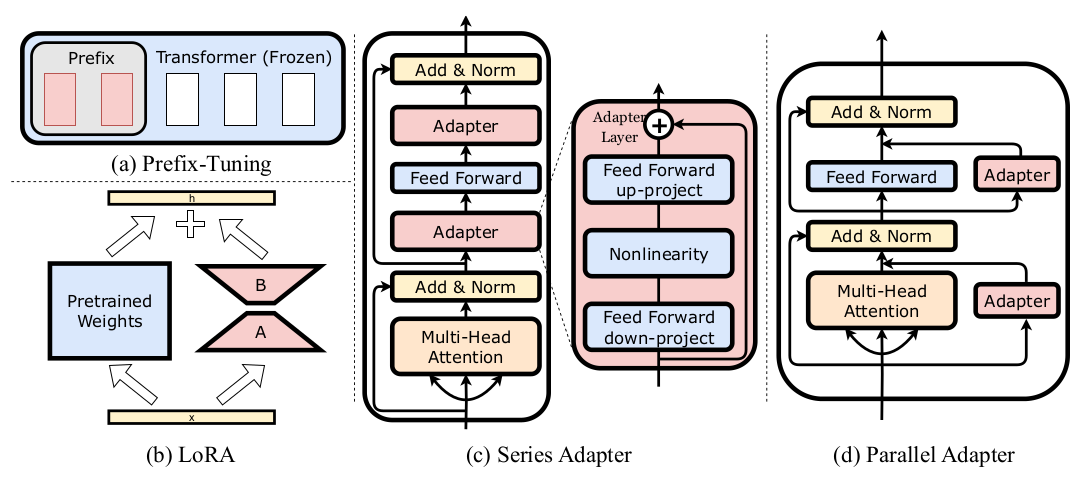
类似LORA这种,用较少参数量的fine-tuning,取代全参数量fine-tuning的方法,被称为Adapter,或者parameter-efficient fine-tuning (PEFT)。
论文:《LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models》
Hugging Face有一个叫做peft的库,支持多种微调方法,包括LoRA(Low-Rank Adaptation)、Prefix Tuning、P-Tuning、Prompt Tuning等,这些方法可以帮助减少可训练参数的数量,使训练更高效。
参考:
https://huggingface.co/datasets/HuggingFace-CN-community/translation/blob/main/lora_cn.md
使用LoRA进行Stable Diffusion的高效参数微调
https://zhuanlan.zhihu.com/p/631411685
微软LoRA:使用万分之一的参数微调你的GPT3模型
https://zhuanlan.zhihu.com/p/620327907
LoRA:大模型的低秩适配-最近大火的lora到底是什么东西?为啥stable diffusion和开源ChatGPT复现都在用?
https://zhuanlan.zhihu.com/p/639229126
深入浅出解析LoRA完整核心基础知识
https://mp.weixin.qq.com/s/nhIRulIRD6VrdPInDsaD8A
使用QLoRA对Llama 2进行微调的详细笔记
https://blog.csdn.net/v_JULY_v/article/details/135375799
从LongLoRA到LongQLoRA(含源码剖析):超长上下文大模型的高效微调方法
GaLore
GaLore的思路和LoRA,也是采用低秩分解,来减少参数的内存占用。方法如下:
for weight in model.parameters():
grad = weight.grad
# original space -> compact space
lor grad = project(grad)
# update by Adam, Adafactor, etc.
lor update = update(lor grad)
# compact space -> original space
update = project back(lor update)
weight.data += update
与传统的优化器在反向传播后同时更新所有层的方法不同,GaLore在反向传播期间实现逐层更新。这种方法进一步减少了整个训练过程中的内存占用。
代码:
https://github.com/jiaweizzhao/GaLore
FSDP
Fully Sharded Data Parallel是Facebook深度借鉴微软ZeRO之后提出的PyTorch DDP升级版本,可以认为是对标微软ZeRO,其本质是parameter sharding。Parameter sharding就是把模型参数切分到各个GPU之上。
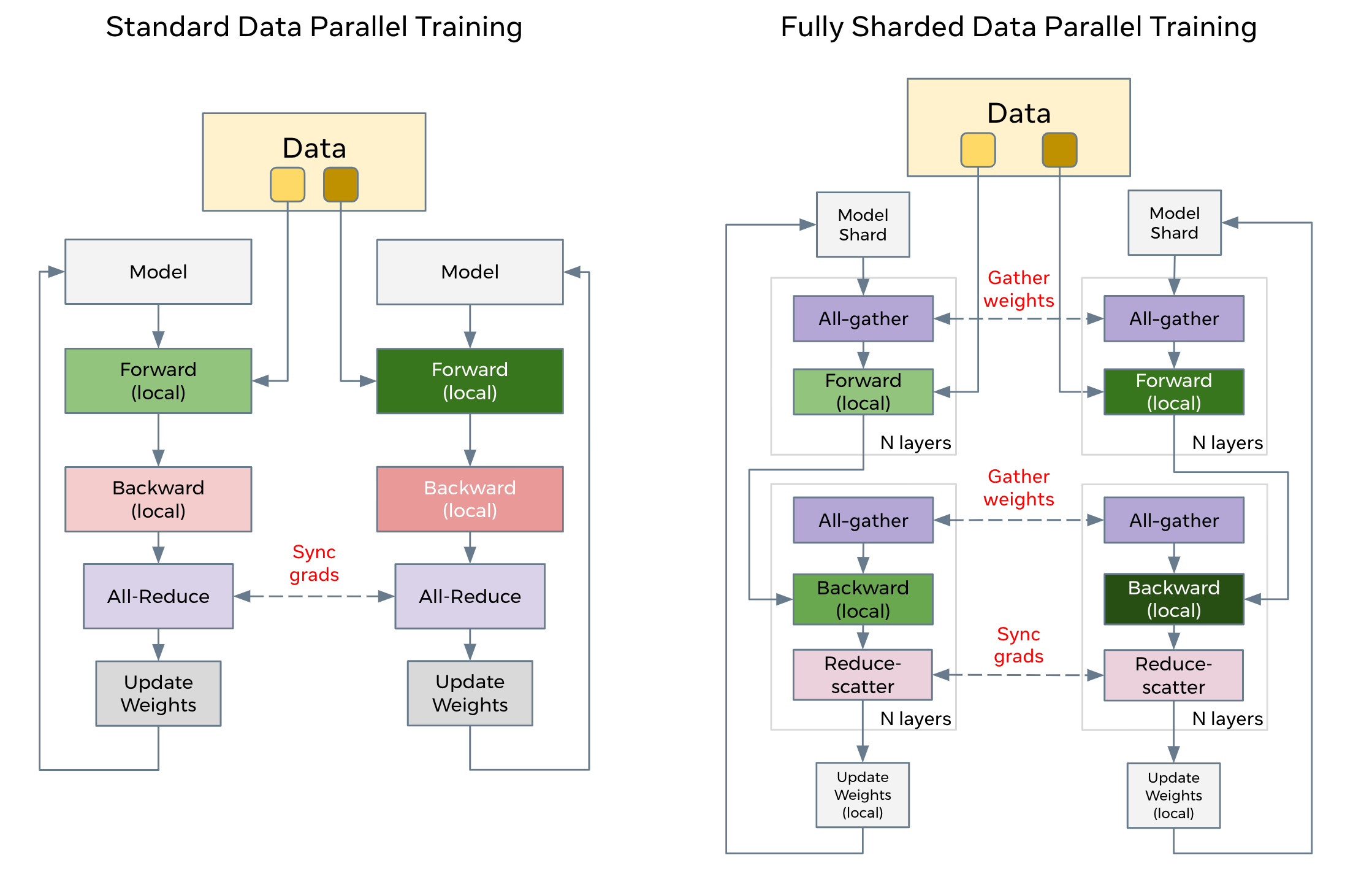
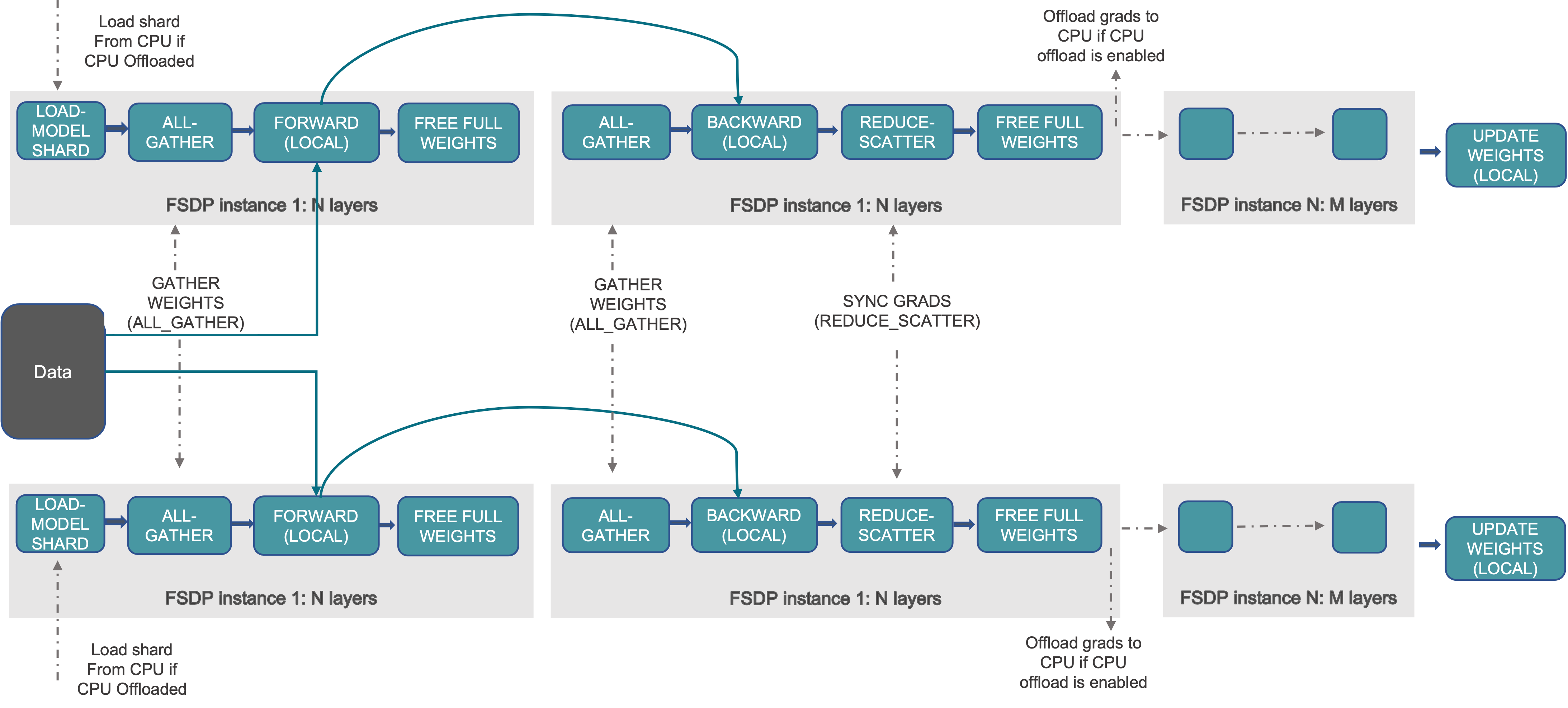
上面的操作之所以能够成立,其实是利用了以下公式:
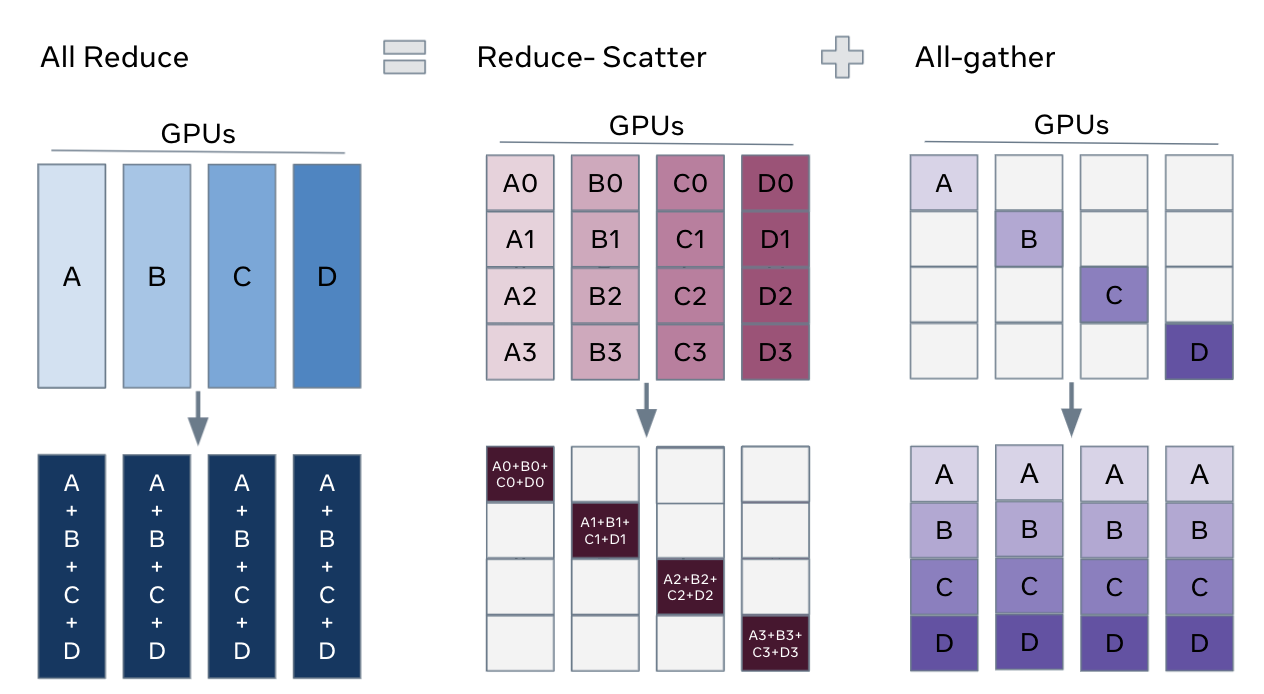
FSDP本身并不能减少数据的通信量,更不可能减少计算量(所有的分布式算法都无法减少理论计算量),甚至还会增加数据的通信量。但是可以通过重叠IO和计算的时间,来提升系统的利用效率。显然与其等待全部计算完成,再All-Reduce,还不如算一部分,通信一部分来的快。
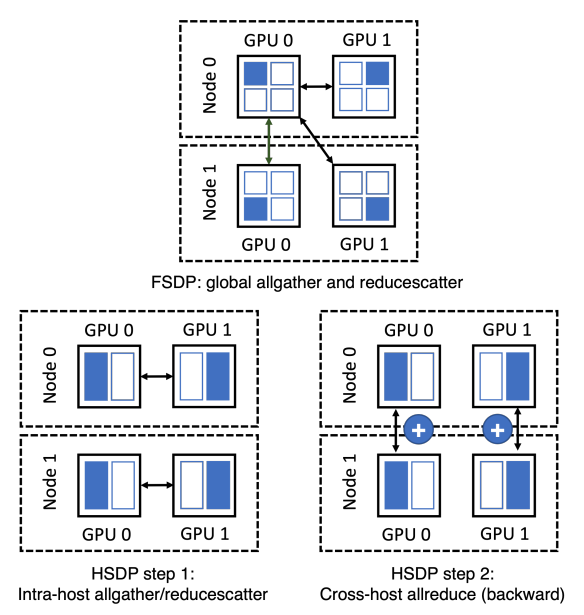
受到FSDP的启发,Facebook又发明了HSDP(hybrid sharding data parallel),进一步用小步快跑的IO策略,提升系统的利用效率。
pytorch roadmap:
- 3DParallel = FSDP2 + ASync SP + PP
- 4DParallel = FSDP2 + ASync SP + CP + PP
- 5DParallel = HSDP2 + Async SP + CP + PP
代码:
https://github.com/facebookresearch/fairscale/blob/main/fairscale/nn/data_parallel/fully_sharded_data_parallel.py
pytorch里已经集成了该代码:
torch/distributed/fsdp/fully_sharded_data_parallel.py

您的打赏,是对我的鼓励
