DL acceleration » 并行 & 框架 & 优化(三)——tf.distribute & MultiDevice
2022-09-13 :: 6064 WordsMPI(续)
Alltoall
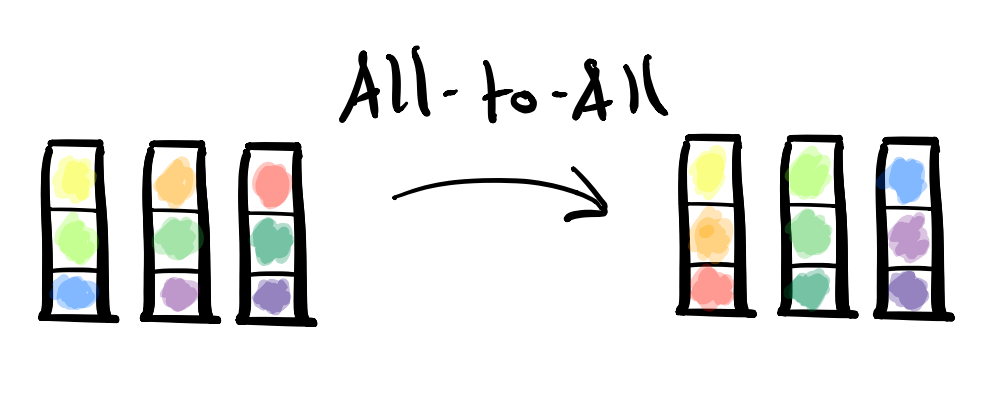
MPI_Alltoall的工作方式是MPI_Scatter和MPI_Gather的组合。它的用途之一就是上图所示的数据的行列转置,但它比转置要灵活的多。
groups
以上这些操作都涉及了多个计算节点。执行同一操作的多个节点组成一个group。
group里包含了相关的节点的id,如果group为null,则该操作会在整个计算集群上执行。两个group可以进行交集、并集之类的集合运算,生成新的group。
总结
ScatterGather(SrcIDRange,SrcAddr,DstIDRange,DstAddr,UnitSize,TotalSize)
When there is only one source and UnitSize = TotalSize, it is a Broadcast
When there is only one source and UnitSize != TotalSize, it is a Scatter
When there is only one destination and UnitSize = TotalSize, it is a Gather
When UnitSize = TotalSize and there are multiple sources and destinations, it is a AllGather operation
When UnitSize != TotalSize and there are multiple sources and destinations, it is a All-to-All operation
从上面可以看出,除了Reduce一系的操作之外,其他的都可以总结为Scatter+Gather。
Scatter也被称为One-to-all,Gather也被称为All-to-one。
AllReduce
AllReduce有多种具体的实现方式。
- Ring AllReduce:
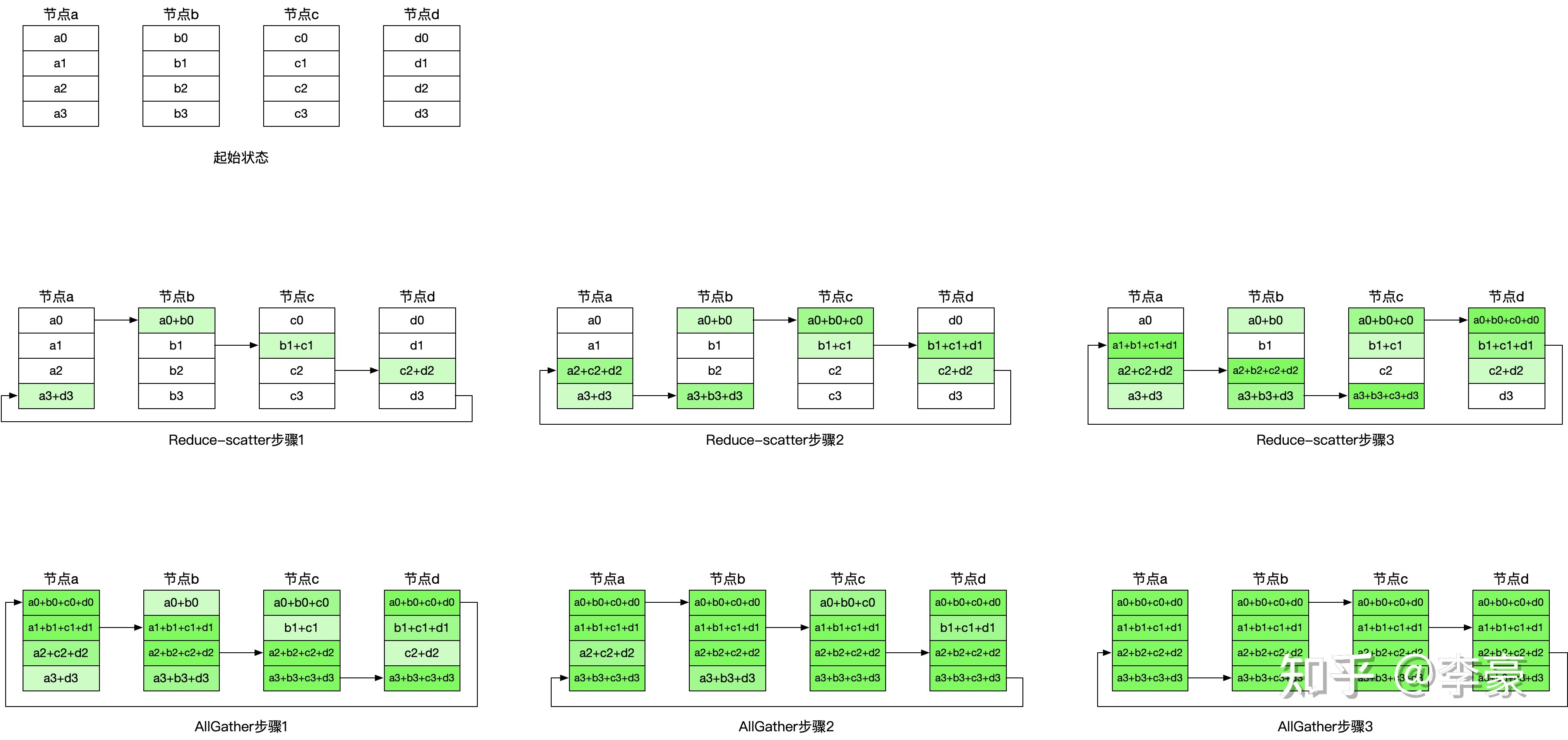
- Having-Doubling AllReduce:
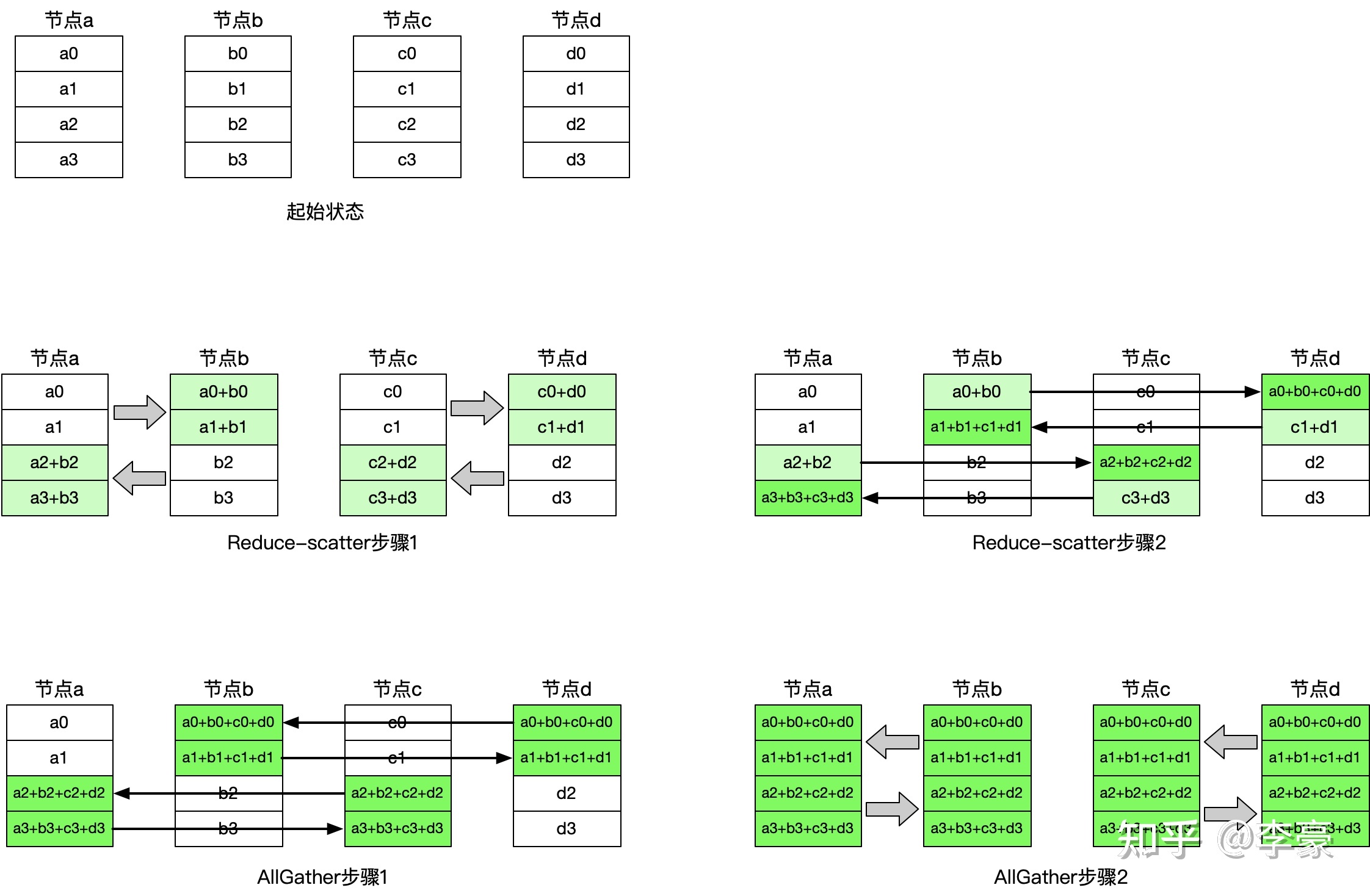
该算法每次选择节点距离倍增的节点相互通信,每次通信量倍减(或倍增)。
该算法的优点是通信步骤较少,只有\(2 * log_2N\)次(其中N表示参与通信的节点数)通信即可完成,所以其有更低的延迟。相比之下Ring算法的通信步骤是\(2 ∗ (N−1)\)次;缺点是每一个步骤相互通信的节点均不相同,链接来回切换会带来额外开销。
-
Recursive Doubling算法
-
Rabenseifner算法
-
Binary blocks算法
ring all-reduce具有理论上最优的传输带宽,而没有考虑每次传输都包含的延迟(latency)。当数据量V比较大时,延迟项可以忽略。当V特别小,或者设备数p特别大时,带宽就变得不重要了,反而是延迟比较关键。
这也是为什么英伟达NCCL里既实现了ring all-reduce,也实现了double-tree all-reduce算法。
AllReduce的实现方式不仅和原理相关,也和真实的物理连接方式有关:

实际情况要更加复杂,用户可能指定某几块GPU进行通信,这个时候树或者环的结构就不好找了。
例如,在图C中,我们有一个双NVLink连接的骨干环。但是如果我要在GPU 0/1/2/7之间进行allreduce,可怎么办呢?7和0/1/2离得太远了,对算法效率有很大影响。事实上,即使对于成熟的集合通信库,例如nccl,当GPU数目是3或者5的时候效果表现也不好。最好的办法还是学习理解这些拓扑结构,不要出现这样的情况,尽量同时使用拓扑上靠近的GPU。
参考:
https://www.zhihu.com/question/57799212
ring allreduce和tree allreduce的具体区别是什么?
https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
Bringing HPC Techniques to Deep Learning
https://zhuanlan.zhihu.com/p/79030485
AllReduce算法的前世今生
https://mp.weixin.qq.com/s/4XMVYXnzpYZ4DrIabuTUig
Ring All-reduce: 分布式深度学习的巧妙同步
https://zhuanlan.zhihu.com/p/504957661
手把手推导Ring All-reduce的数学性质
https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4/
Massively Scale Your Deep Learning Training with NCCL 2.4
https://zhuanlan.zhihu.com/p/611229620
NVIDIA的custom allreduce
https://zhuanlan.zhihu.com/p/692947173
一文读懂nvidia-smi topo的输出
https://zhuanlan.zhihu.com/p/653968730
一文搞懂MPI通信接口的特点及原理
https://zhuanlan.zhihu.com/p/652690336
消息传递接口MPI诞生记
其他概念
这里的有些概念并非MPI的内容,但在分布式计算中,应用的比较广,所以就放在这里了。
rank:进程号,在多进程上下文中,我们通常假定rank 0是第一个进程或者主进程,也被称为coordinator(master)。其余的进程为worker。由Rank0来协调所有Rank的进度。
node:物理节点,可以是一个容器也可以是一台机器,节点内部可以有多个GPU。
local_rank:指在一个node上进程的相对序号,local_rank在node之间相互独立。
![]()
rank与GPU之间没有必然的对应关系,一个rank可以包含多个GPU;一个GPU也可以为多个rank服务(多进程共享GPU),只是习惯上默认一个rank对应着一个GPU。
local_world_size:本地worker数量nproc_per_node。
world_size:所有机器进程的和。world_size = nproc_per_node * nnodes
举例说明:假如有2台机器,每台机器有4块GPU,那么,RANK为[0, 7];每台机器上的LOCAL_RANK的取值为[0, 3];world_size的值为8;
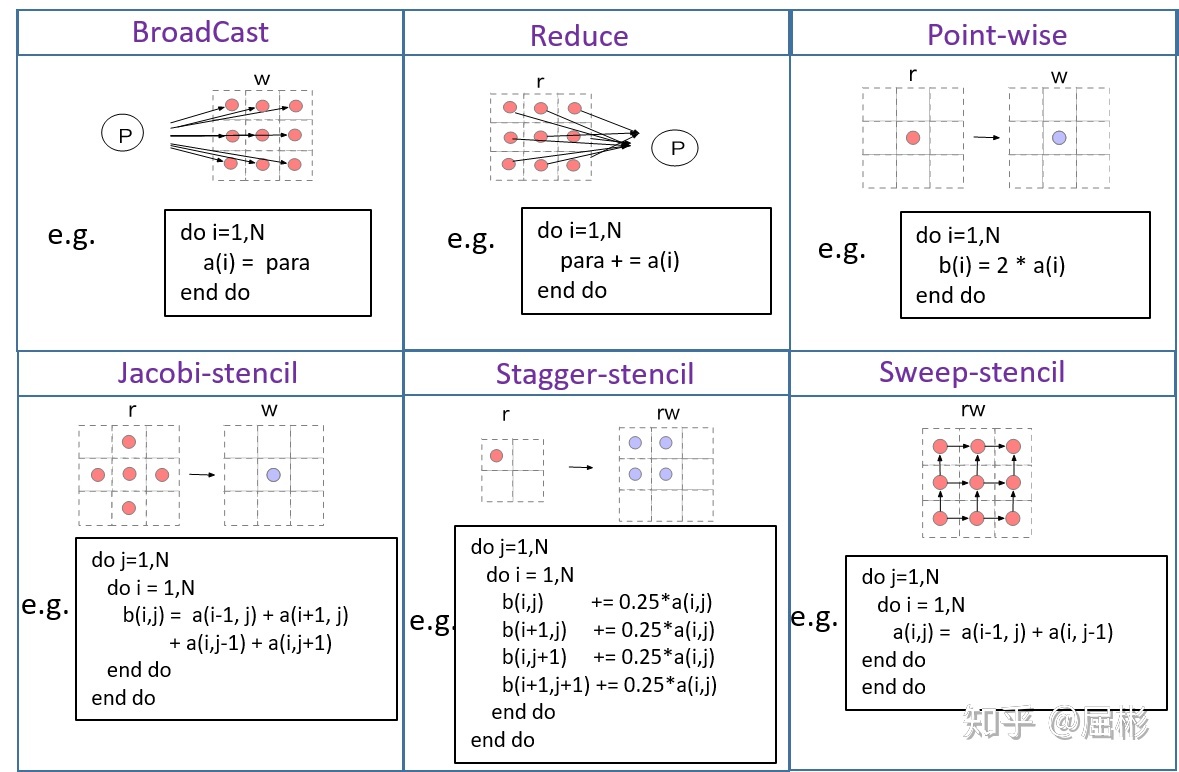
stencil计算:
参考
https://zhuanlan.zhihu.com/p/69497154
高性能计算–mpi
https://mpitutorial.com/tutorials/
MPI Tutorials
https://zhuanlan.zhihu.com/p/363710263
集体通信
https://downey.io/notes/omscs/cse6220/distributed-memory-model-mpi-collectives/
distributed memory model and mpi collectives
https://blog.csdn.net/q19149/article/details/102594031
集合通信函数图解
https://zhuanlan.zhihu.com/p/465967735
分布式训练硬核技术——通讯原语
https://zhuanlan.zhihu.com/p/276122469
分布式训练常用技术简介
https://zhuanlan.zhihu.com/p/425830285
最理想的点到点通信库究竟是怎样的?
tf.distribute & MultiDevice
MirroredStrategy:单机多卡训练
MultiWorkerMirroredStrategy:多机训练
CentralStorageStrategy也执行同步训练,但是变量不会被镜像,而是放在CPU上。各操作(operation)在本地GPU之间复制进行。如果只有一个GPU,变量和操作都会放在GPU上。在对CPU上的变量进行更新前,该策略会先将所有 GPU副本的上的变量梯度进行聚合,然后应用到CPU变量更新中。
tensorflow::ProcessFunctionLibraryRuntime::RunMultiDevice
https://www.cnblogs.com/rossiXYZ/p/16142677.html
TensorFlow之分布式变量(该作者写了一系列的TF分布式文章)
示例:
https://github.com/antkillerfarm/antkillerfarm_crazy/tree/master/python/ml/tensorflow/xla/multi_device_lenet_xla.py
Rendezvous
Rendezvous是一个法语单词,发音也比较特殊,一般直译为“约会、相会、会和”,而在TensorFlow中,Rendezvous是用来完成消息传输的通信组件。
消息传输的唯一标识符——ParsedKey
Send和RecvAsync二者的相对顺序是不能保证先后的,经常出现需求比供给在时间片上先到的情况,总是迟到的一方执行waiter函数。
Send方——将Ready的Tensor挂入本地Table
Recv方——向Send方主动发出请求,触发通信过程
所以,真正的通信过程由Recv方触发,而不是Send方。
TensorFlow已经支持包括gRPC,RDMA(Remote Direct Memroy Access),GDR(GPU Direct)和MPI四种通信协议。
BFC(Best-Fit with Coalescing)是dlmalloc的一个简单实现版本。
https://www.cnblogs.com/deep-learning-stacks/p/10354258.html
TensorFlow中的通信机制——Rendezvous(一)本地传输
https://www.cnblogs.com/deep-learning-stacks/p/10355770.html
TensorFlow中的通信机制——Rendezvous(二)gRPC传输
https://blog.csdn.net/gaofeipaopaotang/article/details/80736452
模型优化之分布式执行
https://xieyu.github.io/blog/tensorflow/rendezvous.html
Tensorflow Rendezvous
Host to Device:
SameWorkerRecvDone -> CopyTensor::ViaDMA -> CopyHostToDevice -> XlaDeviceContext::CopyCPUTensorToDevice ->
GenericTransferManager::TransferLiteralToDeviceAsync -> TransferManager::TransferBufferToDevice -> Stream::ThenMemcpy
StreamExecutor
StreamExecutor是Google内部为并行编程模型开发的库。TensorFlow中的StreamExecutor是StreamExecutor的开源简版。
https://www.cnblogs.com/deep-learning-stacks/p/9386188.html
TensorFlow中的并行执行引擎——StreamExecutor框架
TF使用stream_executor::DeviceMemoryBase作为设备内存的抽象。用DeviceMemoryBase::opaque作为对于不可直接访问的设备地址的指针。
class GpuExecutor : public internal::StreamExecutorInterface
所以上面提到的Memcpy的调用路径,还有设备相关的后半部分:
Stream::ThenMemcpy -> StreamExecutor::Memcpy -> GpuExecutor::Memcpy -> GpuDriver::AsynchronousMemcpyH2D -> cuMemcpyHtoDAsync
TransferManager
TransferManager类使后端能够提供特定于平台的机制,用于通过给定的设备内存句柄构造XLA literal data。换言之,它可以帮助封装主机与设备之间的双向数据传输。
TransferManager类已经有了一个通用实现:GenericTransferManager,设备只需要派生该类,做一些定制化的修改。所以xxx_transfer_manager.h是关注的重点。
TPU和GPU的修改主要集中在TransferLiteralToInfeed和TransferLiteralFromOutfeed两个函数。
这两个函数的GPU实现在InfeedManager类中。
TransferLiteralToInfeed关键函数调用:
gpu::CopyBufferToDevice -> Stream::ThenMemcpy
如果不对GenericTransferManager做修改,则该类会用Host上的mem buffer,虚拟一个DeviceMemoryBase来处理Feed。
graphcore的实现没有动GenericTransferManager,而是自己单独弄了一套基于TranslatedFeedInfo类的cache机制。
tensorflow/compiler/plugin/poplar/driver/poplar_executable_cache.cc

您的打赏,是对我的鼓励
