database » NoSQL, Velocity, MongoDB
2016-07-10 :: 4974 WordsNoSQL
ACID
在传统数据库系统中,事务具有ACID属性(Jim Gray在《事务处理:概念与技术》中对事务进行了详尽的讨论)。
(1)原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
(2)一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
(3)隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
(4)持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
对于单个节点的事务,数据库都是通过并发控制(两阶段封锁,two phase locking或者多版本,multiversioning)和恢复机制(日志技术)保证事务的ACID特性。对于跨多个节点的分布式事务,通过两阶段提交协议(two phase commiting)来保证事务的ACID。
可以说,数据库系统是伴随着金融业的需求而快速发展起来的。对于金融业,可用性和性能都不是最重要的,而一致性是最重要的,用户可以容忍系统故障而停止服务,但绝不能容忍帐户上的钱无故减少(当然,无故增加是可以的)。而强一致性的事务是这一切的根本保证。
James Nicholas Gray,1944~2007,出生于美国加州旧金山,UCB博士(1969),图灵奖得主(1988),美国国家科学院院士,美国国家工程院院士,美国艺术与科学院院士。
2007年,Jim驾驶帆船出海,准备把母亲的骨灰撒入大海,但是一去不返。。。
Data Replication
数据复制(data replication)属于分布式计算的范畴,它并不仅仅局限于数据库,但这里主要是指分布式数据库的复制。
在多副本构成的分布式数据库系统中,其事务特性与单个数据库系统的差别主要表现在原子性和一致性两个方面。在原子性方面,要求同一分布式事务的所有操作在所有相关副本上要么提交,要么回滚,即除了保证原有的局部事务的原子性,还需要控制全局事务的原子性;在一致性方面,多副本之间需要保证单一副本一致性。
针对分布式事务的原子性和一致性这两个复制协议中的核心问题,经过近20年的研究,人们提出了各种各样的复制协议。这些协议在外在功能和内部实现两方面都有较大的差别。据此,我们可以从这两个大的方面进行分类说明。
从外在功能的角度看,可以从事务执行的地点和时间两个方面进行分类。从事务执行的地点,可以分为两类:主从(Priamry/Copy)方式和更新所有(Update-Anywhere)方式。
前者的处理过程一般是系统中仅仅指定一个Primary节点接受更新请求,在事务操作执行完毕后,在事务提交前或后将操作广播到其他Copy节点。
后者的处理过程稍微复杂,系统中的任何副本具有相同的地位,都可以接收Update请求,在检测事务冲突、事务提交前或后将各个节点的Update传播到其他副本节点。
Primary/Copy方式并发控制较为简单,由Primary本地的事务控制即可实现,事务原子性的实现也较为简单,一般由Primary节点作为协调节点来实现。但是,其缺陷也显而易见:仅仅单个节点提供Update请求处理能力,对于Update密集类型的应用,如OLTP,容易形成单点性能瓶颈。Update-Anywhere方式则与其相辅相成,可以通过多点提高事务吞吐率,但随之而来的是多个分布式事务之间复杂的并发控制和原子性问题。
从事务提交的时间点看,可以分为积极(Eager)和消极(Lazy)两类。其区别在于,前者是在事务提交前传播更新,后者则是在提交之后才将事务操作传播到其他副本。实际上,前者即通常所谓的同步复制(synchronous replication),后者即所谓的异步复制(asynchronous replication)。
异步复制的优点是可以提高响应速度,但牺牲了一致性,一般实现该类协议的算法需要增加额外的补偿机制。同步复制的优点是可以保证一致性(一般通过两阶段提交协议),但是开销较大,可用性不好(参见CAP部分),带来了更多的冲突和死锁等问题。值得一提的是Lazy+Primary/Copy的复制协议在实际生产环境中是非常实用的,MySQL的复制实际上就属于这种。
CAP
在2000年的PODC(Principles of Distributed Computing)会议上,University of California, Berkeley的计算机科学教授Eric Brewer提出了著名的CAP理论。2002年,Seth Gilbert和Nancy Lynch证明了这一理论。CAP指的是:Consistency、Availability和Partition Tolerance。
(1)Consistency(一致性):一致性是指数据的原子性,这种原子性在经典的数据库中是通过事务来保证的,当事务完成时,无论其是成功还是回滚,数据都会处于一致的状态。在分布式环境中,一致性是说多个节点的数据是否一致。
(2)Availability(可用性):可用性是指服务能一直保证是可用的状态,当用户发出一个请求,服务能在有限时间内返回结果。
(3)Partition Tolerance(分区容错性):Partition是指网络的分区。可以这样理解,一般来说,关键的数据和服务都会位于不同的IDC。
CAP理论告诉我们,一个分布式系统不可能同时满足一致性,可用性和分区容错性这三个需求,三个要素中最多只能同时满足两点。三者不可兼顾,此所谓鱼与熊掌不可兼得也!而对于分布式数据系统而言,分区容错性是基本要求,否则就不称其为分布式系统了。因此架构设计师不要把精力浪费在设计如何能同时满足三者的完美分布式系统上,而是应该进行权衡取舍。这也意味着分布式系统的设计过程,也就是根据业务特点在C(一致性)和A(可用性)之间寻求平衡的过程,要求架构师真正理解系统需求,把握业务特点。
类似的,海量数据下还有另一个不可突破的矛盾:查询性能、写性能和一致性不能同时满足。因为查询性能高意味着增加索引,增加索引意味着写入性能差,要同时保住查询和写入性能,那就不得不异步分布式和缓存,强一致性就得不到保证。
BASE
BASE来自于互联网的电子商务领域的实践,它是基于CAP理论逐步演化而来,核心思想是即便不能达到强一致性(Strong consistency),但可以根据应用特点采用适当的方式来达到最终一致性(Eventual consistency)的效果。BASE是Basically Available、Soft state、Eventually consistent三个词组的简写,是对CAP中C&A的延伸。BASE的含义:
(1)Basically Available:基本可用;指分布式系统在出现故障时,允许损失部分的可用性来保证核心可用。
(2)Soft-state:软状态/柔性事务,即状态可以有一段时间的不同步;
(3)Eventual consistency:最终一致性;指分布式系统中的所有副本数据经过一定时间后,最终能够达到一致的状态。
BASE是反ACID的,它完全不同于ACID模型,牺牲强一致性,获得基本可用性和柔性可靠性并要求达到最终一致性。
CAP、BASE理论是当前在互联网领域非常流行的NoSQL的理论基础。
一致性一般分为:强一致性、顺序一致性、最终一致性。
参考:
https://mp.weixin.qq.com/s/k18Udp-06w5qBJoBfe4wcA
提到数据库一致性,每个开发人员都应该知道这些
NoSQL
NoSQL领域的相关知识点参见如下思维导图:
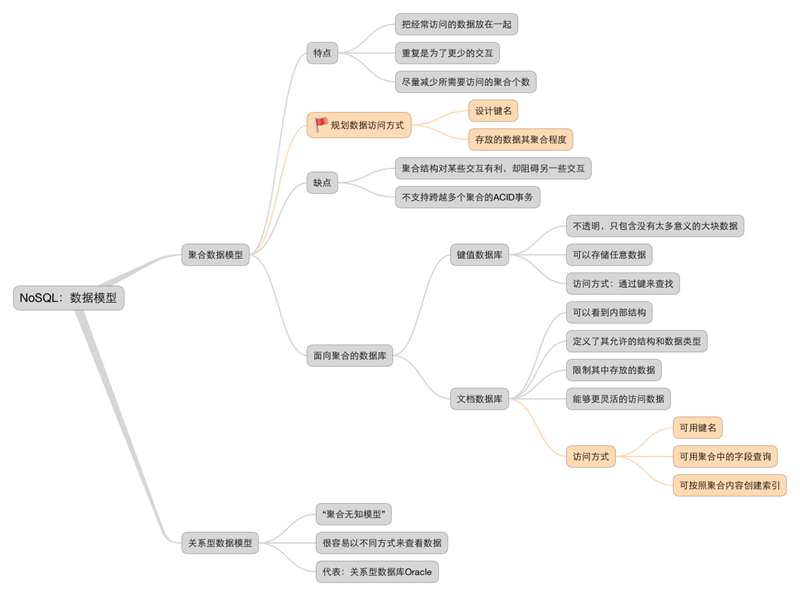
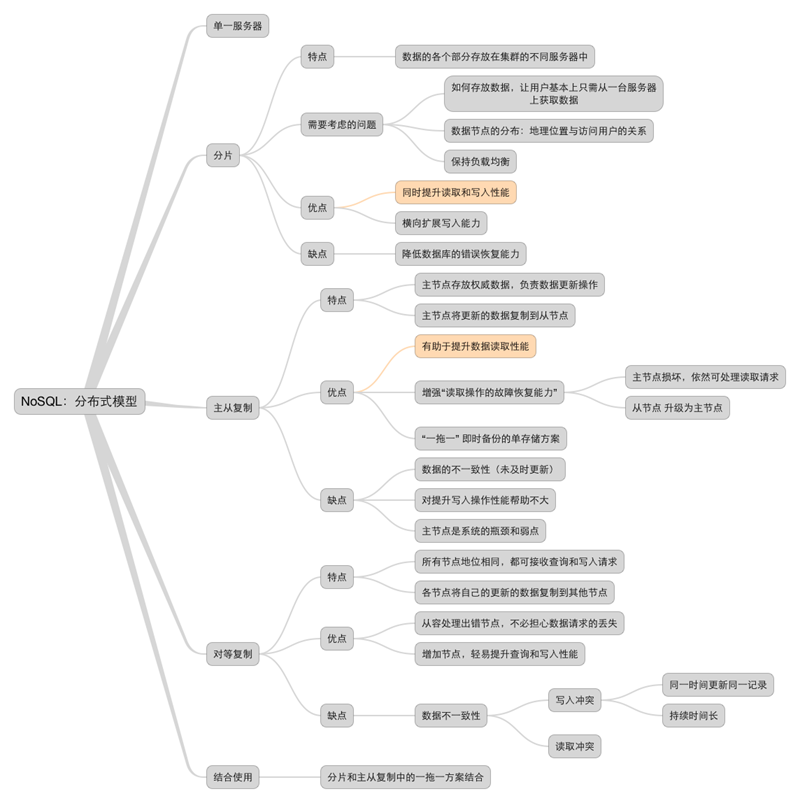
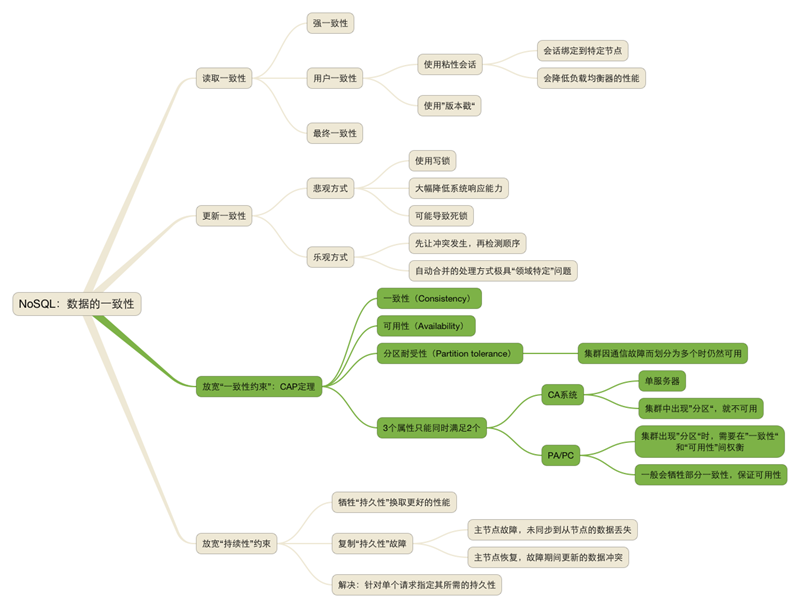
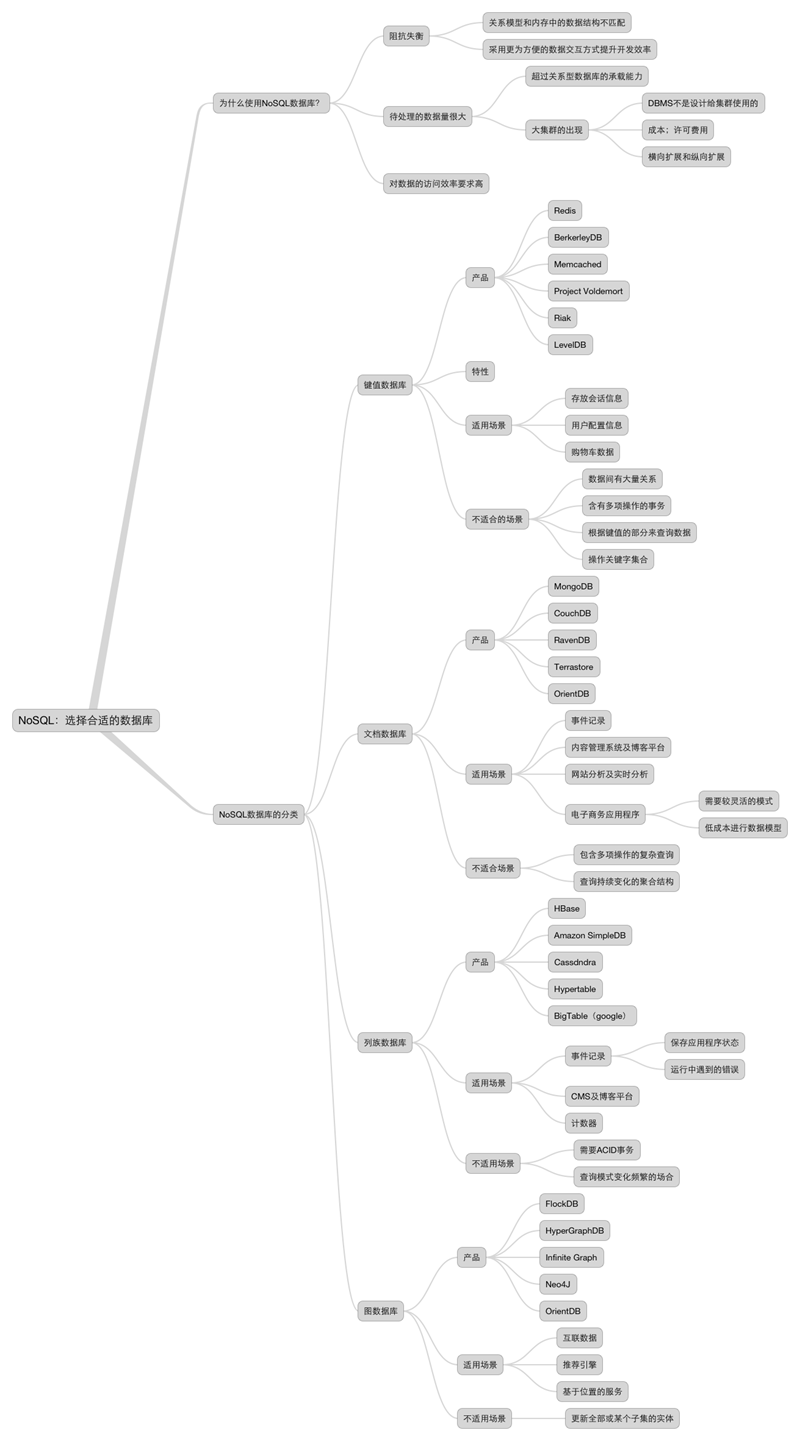
参考
http://www.infoq.com/cn/articles/cap-twelve-years-later-how-the-rules-have-changed
CAP理论十二年回顾:”规则”变了
http://www.cnblogs.com/hustcat/archive/2010/09/07/1820970.html
ACID、Data Replication、CAP与BASE
http://www.cnblogs.com/mmjx/archive/2011/12/19/2290540.html
CAP理论
http://blog.csdn.net/yangbutao/article/details/8365695
分布式数据库的一致性探讨
http://www.cnblogs.com/me115/p/3835050.html
《NoSQL精粹》思维导图读书笔记
https://mp.weixin.qq.com/s/rmOlQwAiXUbmZ130Ekh1Mg
CAP理论—最通俗易懂的解释
https://mp.weixin.qq.com/s/M3GtZ-6p7FWgyCKmRO-FyA
你真的懂吗?分布式系统的基本问题:可用性与一致性
https://mp.weixin.qq.com/s/2NVAy8qL_RNjTnh-h0kuFw
谈谈事务的实现原理吧
Velocity
Velocity是一个基于java的模板引擎(template engine),它允许任何人仅仅简单的使用模板语言(template language)来引用由java代码定义的对象。
Velocity基本等价于之前的JSP,但语法规则和后者有较大差异,其所使用的模板文件为.vm文件。
MongoDB
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。
官网:
https://www.mongodb.com/
安装:
https://docs.mongodb.com/getting-started/shell/tutorial/install-mongodb-on-ubuntu/
参考:
https://www.cnblogs.com/chinesern/p/5581422.html
MongoDB与Redis的比较
https://docs.mongodb.com/manual/reference/sql-comparison/
这里提供了MongoDB查询语法和SQL查询之间的对应关系表。
https://docs.mongodb.com/manual/reference/sql-aggregation-comparison/
这是上面表格的高级版本,专门处理group by的情况。这种情况也叫做Aggregation。
https://mp.weixin.qq.com/s/6UDI8aci-ExVKsdcHJqeiw
MongoDB的水平扩展,你做对了吗?
https://mp.weixin.qq.com/s/n7naUaJKlk_51sEDrdsWcA
如何将关系型数据导入MongoDB?
https://mp.weixin.qq.com/s/vliJVkY0TrccBmTMh-JCBg
菜鸟用Python操作MongoDB
https://mp.weixin.qq.com/s/vIqghJreXyrzlhzPR5PQkA
MongoDB新功能介绍-Change Streams
Robomongo
Robomongo是一个开源的MongoDB的前端工具,基于Qt编写。官网:
https://robomongo.org/

您的打赏,是对我的鼓励
