database » Mysql, LevelDB
2021-05-02 :: 7040 WordsMysql
安装
sudo apt install mysql-server mysql-client mysql-workbench
其中,mysql-workbench是一个查看mysql的GUI工具。
安装过程中,会提示输入root用户的密码。注意:这里的root是mysql的登录帐号,而不是系统的登录帐号。
·/etc/my.cnf是默认的MySQL配置文件。
导入csv文件
http://www.mysqltutorial.org/import-csv-file-mysql-table/
Import CSV File Into MySQL Table
示例:
LOAD DATA LOCAL INFILE 'c:/tmp/discounts.csv'
INTO TABLE discounts
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
上面的语句中,LOCAL必不可少,否则会报如下错误:
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
执行脚本
mysql命令行下执行:
source a.sql
日志
http://www.cnblogs.com/jevo/p/3281139.html
MySQL日志
时间的格式
| 名称 | 格式 |
|---|---|
| DATE | YYYY-MM-DD |
| DATETIME | YYYY-MM-DD HH:MM:SS |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS |
| YEAR | YYYY或YY |
中间数据的存储
有的时候,SQL中间处理的结果需要存储起来,以备后用。这时有两种办法:
1.创建View。
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition;
View并不在数据库中存储数据,而是在查询时,执行其中的select语句(每次查询,都会执行),生成中间结果。因此,View从原理来说,更像是一种语法糖,而非存储机制。
2.使用select语句创建table。
Create table new_table_name (Select * from old_table_name);
这种方法会将中间结果存储到数据库中,下次使用的时候,就无需重新生成了。但缺点是原table中的更新不会体现到新table中,只适合处理历史数据。
模糊查询
http://www.cnblogs.com/GT_Andy/archive/2009/12/25/1921914.html
SQL模糊查询
MyISAM & Innodb
Mysql底层数据引擎以插件形式设计,最常见的是Innodb引擎和Myisam引擎,用户可以根据个人需求选择不同的引擎作为Mysql数据表的底层引擎。
MyISAM虽然数据查找性能极佳,但是不支持事务处理。Innodb最大的特色就是支持了ACID兼容的事务功能,而且他支持行级锁。
常用操作
登录方法:
mysql -h 192.168.4.251 -u root -p
语句以“;”结尾。
| 名称 | 操作 |
|---|---|
| 添加用户 | insert into mysql.user(Host,User,Password) values(“localhost”,”test”,password(“1234”)); |
| 列出所有数据库 | show database; |
| 切换数据库 | use 数据库名; |
| 列出所有表 | show tables; |
| 显示数据表结构 | describe 表名; |
| 创建自增ID | create table github(id int auto_increment primary key not null,name varchar(256)); |
| 查询头N条记录 | select * from shop_info limit N; |
| 检索记录行 6-15 | select * from table limit 5,10; |
| 删除记录 | delete from shop_info where shop_id=”1”; |
| 排序+别名+分组+count | select city_name,count(*) as city_count from shop_info group by city_name order by city_count desc limit 5; |
| 两列排序+两列相乘 | select shop_id,count()per_pay from shop_info order by per_pay desc,shop_id desc; |
| 每日统计 | select count(shop_id),date(time_stamp) as dates from user_pay where shop_id=’1234’ group by dates order by dates asc; |
| 年月日 | select year(ordertime),month(ordertime),day(ordertime) from book; |
| 周数+星期几 | select week(ordertime),weekday(ordertime) from book; |
| 统计表中的记录条数 | select count(*) from user_pay; |
| 统计某一列中不同值的个数 | select count(distinct user_id) from user_pay; |
参考:
http://www.cnblogs.com/wuhou/archive/2008/09/28/1301071.html
Ubuntu安装配置Mysql
http://www.cnblogs.com/wanghetao/p/3806888.html
MySQL添加用户、删除用户与授权
三种Join的区别
left join(左联接)返回包括左表中的所有记录和右表中联结字段相等的记录。
right join(右联接)返回包括右表中的所有记录和左表中联结字段相等的记录。
inner join(等值连接)只返回两个表中联结字段相等的行。
http://www.cnblogs.com/pcjim/articles/799302.html
sql之left join、right join、inner join的区别
查询语句的执行顺序
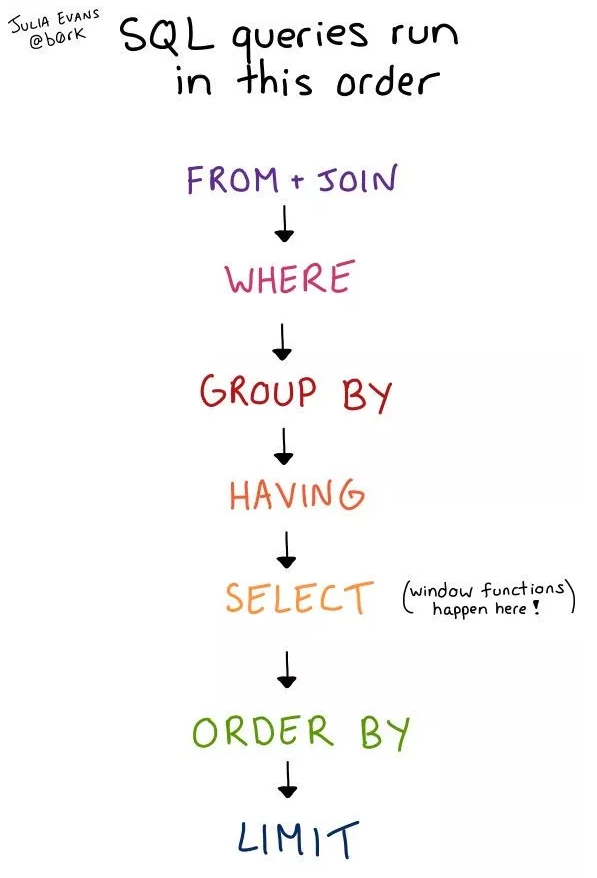
https://mp.weixin.qq.com/s/CMcgybfgya7ftTUeUFigKg
SQL查询语句总是先执行SELECT?你们都错了
当Explain与SQL语句一起使用时,MySQL会显示来自优化器关于SQL执行的信息。也就是说,MySQL解释了它将如何处理该语句,包括如何连接表以及什么顺序连接表等。
https://mp.weixin.qq.com/s/xf4VRBFLhhIAGGZPhbRetQ
不会看Explain执行计划,简历敢写SQL优化?
参考
https://mp.weixin.qq.com/s/9tIy1IqjaB0NdKaO76dgCw
47张图带你MySQL进阶!!!
https://mp.weixin.qq.com/s/ok6VD1b5fhG_mY9O3d_VGA
记住,永远不要在MySQL中使用“utf8”
https://mp.weixin.qq.com/s/duYi1Y5jEWSPQbO3Bgsrrw
SQL Server与MySQL中排序规则与字符集相关知识的一点总结
https://mp.weixin.qq.com/s/N7-8vtVUg3MRY2u_NYpAiA
一份值得收藏的的MySQL规范
https://mp.weixin.qq.com/s/YX1XqKVfPS9DpMi_gTFNiA
1000行MySQL学习笔记
https://www.jianshu.com/p/bdc9e57ccf8b
mysql索引篇之覆盖索引、联合索引、索引下推
https://mp.weixin.qq.com/s/PgGDeowQaQ6MlUExZE-TMA
如果是MySQL引起的CPU消耗过大,你会如何优化?
https://mp.weixin.qq.com/s/L3ydmN1TP5YsxJ97WeFXGg
万字总结:学习MySQL优化原理,这一篇就够了!
https://mp.weixin.qq.com/s/vmKPKn9Y1FPY8MWy2Xcu6A
MySQL的自增ID用完了,怎么办?
https://mp.weixin.qq.com/s/H0FI_Ci0YAQyUfaK3OVDJw
InnoDB自增原理都搞不清楚,还怎么CRUD?
https://mp.weixin.qq.com/s/QduIxKOykMmoZp13UGF1XQ
MySQL索引知识点总结
https://mp.weixin.qq.com/s/E0PIOTflCicyPs5fcv0qAg
Mysql高性能优化规范建议
https://mp.weixin.qq.com/s/0AlXjjYIQUU9tkw2LNiR_A
MySQL不会丢失数据的秘密,就藏在它的7种日志里
https://mp.weixin.qq.com/s/b7Qnzh1EIM4wbExwmIkJyA
一个线上SQL死锁异常分析:深入了解事务和锁
https://mp.weixin.qq.com/s/58Xm6IrrTClny6DsNAbxrg
详解一条SQL的执行过程
https://mp.weixin.qq.com/s/Vlsm9rHHaCl02gZmDQfgDA
到底是什么原因才导致 select * 效率低下的
https://www.toutiao.com/i6843323300764975628/
MySQL压力测试工具
https://mp.weixin.qq.com/s/giy44TE0QVHWoQwMg84jNA
MySQL中ORDER BY与LIMIT不要一起用
https://www.cnblogs.com/andy6/p/6959028.html
从Oracle迁移到MySQL的各种坑及自救方案
https://mp.weixin.qq.com/s/txbusDvTKwFZdX94kDp7VQ
10个不为人知的SQL技巧
https://mp.weixin.qq.com/s/qquMk4M81Pjw9fxkostf4Q
小米:Mysql数据实时同步实践
https://shockerli.net/post/1000-line-mysql-note/
一千行MySQL学习笔记
https://mp.weixin.qq.com/s/SCW_3AypO-rSolMcjCxVtA
MySQL事务隔离级别和MVCC
https://mp.weixin.qq.com/s/SMNMM4wmEOGeUJjRy6XSBA
MVCC机制了解吗
https://mp.weixin.qq.com/s/qHJiTjpvDikFcdl9SRL97Q
深入理解MySQL索引底层原理
https://mp.weixin.qq.com/s/KBvNzs_y1RDXoDnwB319JA
MySQL磁盘清理
https://mp.weixin.qq.com/s/t0gfW7UHzkKgNrAVyOfK7Q
吊打MySQL,MariaDB到底强在哪?
https://mp.weixin.qq.com/s/-QPabXE2plPB0lok-Ic9jA
MySQL锁系统总结
https://mp.weixin.qq.com/s/sRFmW57KUY3yyyRkyw0L4A
MySQL深入学习总结
https://mp.weixin.qq.com/s/5brbbLOJrnwZxnF5RpbMqA
MySQL隐式转换的坑,一起来看看究竟!
https://mp.weixin.qq.com/s/pb3U4oYDSnmx0ZhLnVy58A
MySQL为Null会导致5个问题,个个致命!
https://mp.weixin.qq.com/s/WD804KImL5jCvq-EJUdmSw
100道MySQL数据库经典面试题解析
LevelDB
LevelDB是一个持久化的key/value存储。作者是大名鼎鼎的Sanjay Ghemawat和Jeff Dean。
代码:
https://github.com/google/leveldb
和它类似的还有LMDB。
官网:
https://www.openldap.org/
参考:
https://zhuanlan.zhihu.com/p/53299778
既生Redis何生LevelDB?
https://cloud.tencent.com/developer/article/1602204
LevelDB从入门到原理详解
数据库参考资源

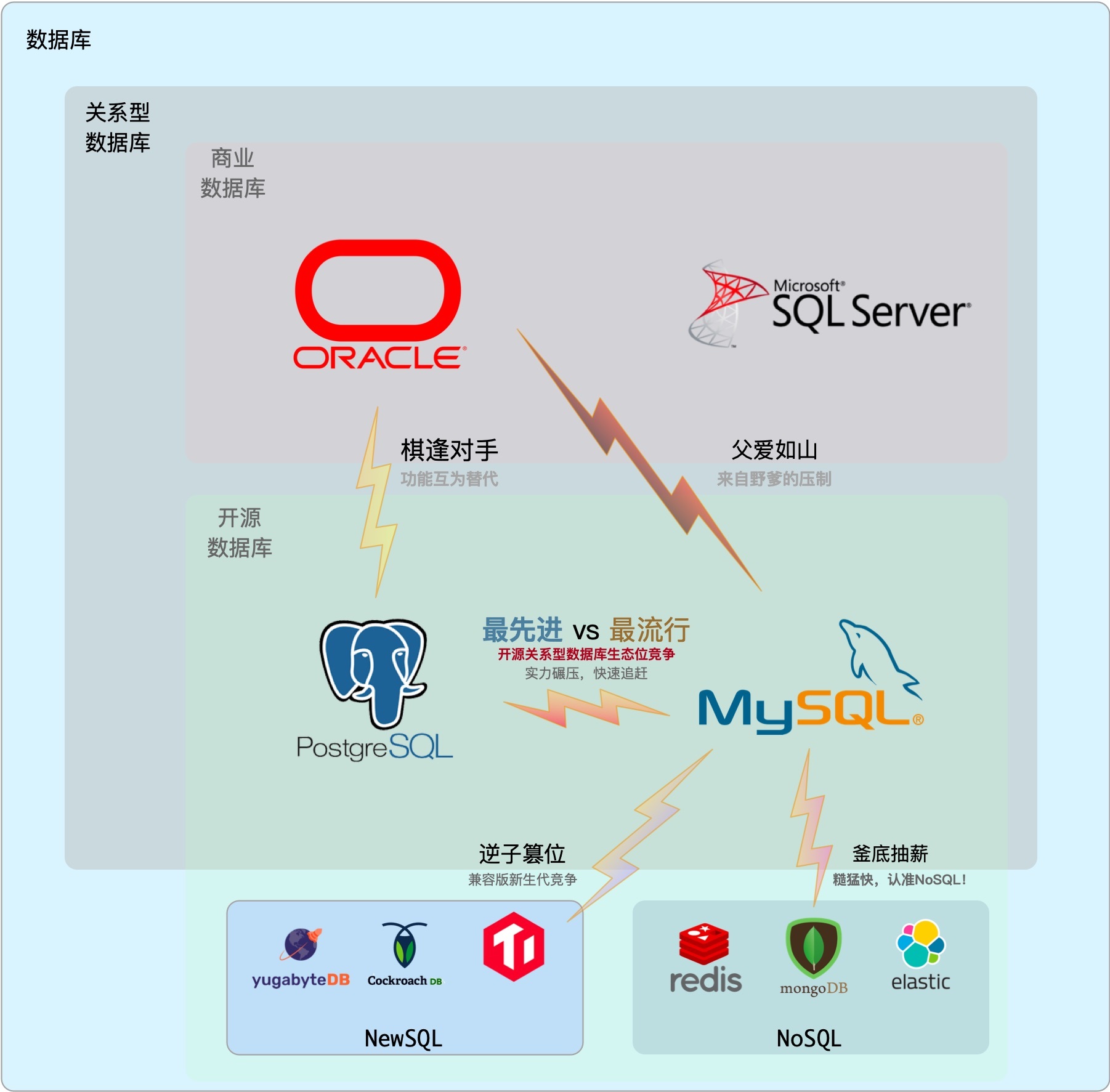
https://hpi.de/naumann/projects/rdbms-genealogy.html
https://zhuanlan.zhihu.com/p/439807305
为什么说PostgreSQL前途无量?
https://mp.weixin.qq.com/s/CvXKbp5Id6_lOWNs6ntWiA
SQL最大竞争对手(QUEL)的简史
https://www.zhihu.com/question/31955622
postgresql也很强大,为何在中国大陆,mysql成为主流,postgresql屈居二线呢?
https://mp.weixin.qq.com/s/ActS6PxbtZGqPb0jOn0iFg
不懂数据库索引的底层原理?那是因为你心里没点b树
http://www.ruanyifeng.com/blog/2014/07/database_implementation.html
数据库的最简单实现
https://blog.csdn.net/zhengzhb/article/details/8590390
SQL查找删除重复行
https://www.cnblogs.com/ahu-lichang/p/10899747.html
数据库三大范式(1NF,2NF,3NF)及ER图
https://mp.weixin.qq.com/s/m_JMXU6iMS4SckzWZYtIUA
腾讯分布式数据库TDSQL金融级能力的架构原理解读
https://mp.weixin.qq.com/s/jdPE9WClBuimIHVxJnwwUw
字节跳动自研强一致在线KV&表格存储实践-上篇
https://mp.weixin.qq.com/s/DvUBnWBqb0XGnicKUb-iqg
字节跳动自研强一致在线KV&表格存储实践-下篇
https://mp.weixin.qq.com/s/PPlrrtcdrtKT3afgWOU8Pg
为什么数据库不应该使用外键
https://mp.weixin.qq.com/s/k1sK-QQjVqdJnpWNCV0pUA
并发环境下,先操作数据库还是先操作缓存?
https://mp.weixin.qq.com/s/I3ca2HAuSTtUJSZyHNe1vA
数据库读写分离要注意哪些细节
https://mp.weixin.qq.com/s/oV5F_K2mmE_kK77uEZSjLg
字节跳动分布式表格存储系统的演进
https://mp.weixin.qq.com/s/ZjnRzI18plggKTv_nPBsEw
字节跳动表格存储中的事务

您的打赏,是对我的鼓励
