speech » 语音识别(六)——FBank, 语音识别的评价指标, 声学模型进阶, 语言模型进阶, GMM-HMM, WFST(1)
2018-07-26 :: 6718 Words- Mel-Frequency Analysis(续)
- FBank
- Pitch Detection
- Vector Quantization
- fMLLR
- SGMM
- PLP
- VTLN
- HMM与语音识别
- 语音识别的评价指标
- 声学模型进阶
- 语言模型进阶
- GMM-HMM
- LDA-MLLT
- WFST
Mel-Frequency Analysis(续)
参考
http://blog.csdn.net/zouxy09/article/details/9156785
梅尔频率倒谱系数(MFCC)
https://my.oschina.net/jamesju/blog/193343
语音特征参数MFCC提取过程详解
https://liuyanfeier.github.io/2017/10/26/2017-10-27-Kaldi%E4%B9%8Bfbank%E5%92%8Cmfcc%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96/
kaldi之fbank和mfcc特征提取
https://zhuanlan.zhihu.com/p/26680599
语音信号预处理及特征参数提取
https://mp.weixin.qq.com/s/QuqdbDmdKCQ_KPmwLm0GRg
机器学习中的音频特征:理解Mel频谱图
FBank
Filter bank和MFCC的计算步骤基本一致,只是没有做IDFT而已。
FBank与MFCC对比:
1.计算量:MFCC是在FBank的基础上进行的,所以MFCC的计算量更大
2.特征区分度:FBank特征相关性较高(相邻滤波器组有重叠),MFCC具有更好的判别度,这也是在大多数语音识别论文中用的是MFCC,而不是FBank的原因
3.使用对角协方差矩阵的GMM由于忽略了不同特征维度的相关性,MFCC更适合用来做特征。
4.DNN/CNN可以更好的利用这些相关性,使用fbank特征可以更多地降低WER。
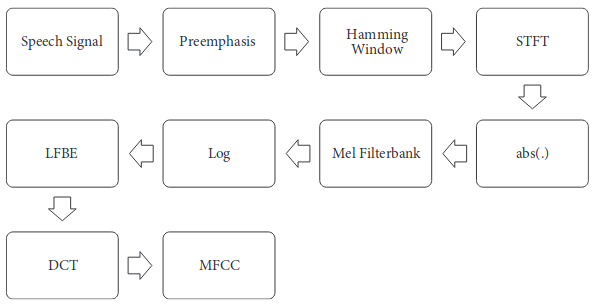
FBank有时也叫做log of filter bank energy(LFBE)。
论文:
《Bandwidth extension of narrowband speech in log spectra domain using neural network》
参考:
http://blog.csdn.net/wxb1553725576/article/details/78048546
Kaldi特征提取之-FBank
Pitch Detection
http://blog.csdn.net/zouxy09/article/details/9141875
基音周期估计(Pitch Detection)
Vector Quantization
http://blog.csdn.net/zouxy09/article/details/9153255
矢量量化(Vector Quantization)
fMLLR
https://blog.csdn.net/xmdxcsj/article/details/78512645
声学特征变换fMLLR
SGMM
https://blog.csdn.net/quhediegooo/article/details/68946100
子空间高斯混合模型-SGMM
PLP
Perceptual Linear Prediction
《Perceptual Time Varying Linear Prediction Model for Speech Applications》
https://www.isip.piconepress.com/courses/msstate/ece_8463/lectures/current/lecture_17/index.html
SPECTRAL TRANSFORMATIONS
VTLN
https://blog.csdn.net/jiangyangbo/article/details/6535928
VTLN(Vocal Tract Length Normalisation)
HMM与语音识别
HMM的基本概念参见《机器学习(二十二)》,这里谈一下HMM在语音识别领域的应用。
从概率的角度来说,语音识别的目标是寻找最可能的\(P(W\mid O)\)。这里的W表示word,O表示observation。
直接找显然没这么容易,所以要用到Bayes公式:
\[\frac{P(W)P(O\mid W)}{P(O)}\]这里只有\(P(O)\)已知,剩下的两个参数都需要额外提供。其中HMM提供\(P(O\mid W)\),LM提供\(P(W)\)。
由于HMM的path上的概率是各个transition probability的乘积,而这些概率都小于1,因此他们的乘积必然是更小的数。这时可以考虑使用对数,不仅可将乘法变为加法,同时数值的范围也得到了改善。
语音识别的评价指标
语音识别的评价指标主要是Word Error Rate(WER)。
错误的情况包括三种:
1.Substitutions:错词。
2.Deletions:漏词。
3.Insertions:多词。
\[WER=100\%\times \frac{Subs+Dels+Ins}{\text{word in correct sentence}}\]类似的还有CER/PER:Character/Phoneme Error Rate。
需要注意的是,评价WER时,需要在ASR output和Label之间进行对齐操作,而不是简单的从左往右匹配,否则将无法正确处理Deletions和Insertions的情形。
还有根据公式可知,WER是可以大于100%的。
参考:
https://blog.csdn.net/quhediegooo/article/details/56834417
语音识别评估标准-WER
声学模型进阶
语音质量
更高的采样率可以降低WER。一般来说,16KHz相比8KHz的WER要小10%左右。
Voice Detection
长时间的silence会增加WER,因此我们需要判断当前是否在说话。
Voice Detection包括两个方面:
1.Beginning-Point Detection。也叫做Voice Activity Detection(VAD)或者Acoustic event detection (AED)。有些类似于唤醒检测,但并不局限于设备的开机时刻。
2.End-Point Detection。
参考:
https://zhuanlan.zhihu.com/p/24432663
Voice Active Detection(VAD)的过去时与现在时
https://blog.csdn.net/wxb1553725576/article/details/78069089
Kaldi特征提取之-VAD
https://blog.csdn.net/shichaog/article/details/78257068
VAD综述
https://mp.weixin.qq.com/s/cdhEAgXn76cYnxYk1d9lzQ
智能语音机器人中VAD语音端点检测算法优化实践
Feature normalization
有时候需要对Feature进行normalization。例如,对MFCC特征减去均值,可以有效提升在噪声环境下的识别率。
Tri-phone Models
英语一般包含43个音素,因此Tri-phone共有\(43^3\approx 80K\)种不同组合。
但是这些组合的概率是众寡悬殊的,有些组合很常见,而有些组合很罕见。因此我们需要合并相似的发音组合。这通常采用CART决策树来进行聚类。这样做还可以减少状态数量,提高计算效率。
发音词典
Pronunciation Dict用于将文本转换成对应的发音。比较常用的有CMU的发音词典,用于美国英语,包含了100K的单词。用法参见《LSTM Speech Recognition实战》。
然而,无论多大的词典都会有遇到Unknown Words的情况。一般可根据现有发音构建统计模型,来预测发音。这也是符合人们的认知规律的:人遇到一个陌生的新词,也会根据过往的经验,来预测词的发音。通常这样做,会有70%~85%的准确率。
语言模型进阶
语言理论
语言理论方面主要是Chomsky提出的Chomsky hierarchy。
Avram Noam Chomsky,1928年生,University of Pennsylvania本硕(1951)+Harvard University博士。MIT教授。美国艺术科学院、美国科学院院士。
他的《生成语法》被认为是20世纪理论语言学研究上最伟大的贡献,他也被誉为“现代语言学之父”。他对于形式语言的研究,在计算机科学的各领域产生了巨大的影响。这些领域包括:编译原理、AI等。
| 名称 | 概述 | 形式化 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| Finite State Machines | 正则化的语言,无嵌套 | \(a^*b^*\) | O(n) | O(1) |
| Context Free Grammars | 允许嵌套 | \(a^nb^n\) | O(n^3) | 取决于嵌套的层数 |
| Context Sensitive Grammars | 有特定的语法规则 | \(a^nb^nc^n\) | 多项式复杂度 | |
| Generalized Rewrite Rules/Turing machines | 无任何限制 | NP complete |
从中可以看出,编程语言最多也就到Context Sensitive Grammars的程度。
N-gram
可以用Entropy和Perplexity评价N-gram模型的效果。一般来说,Perplexity越低,识别效果越好。
Recognition Network
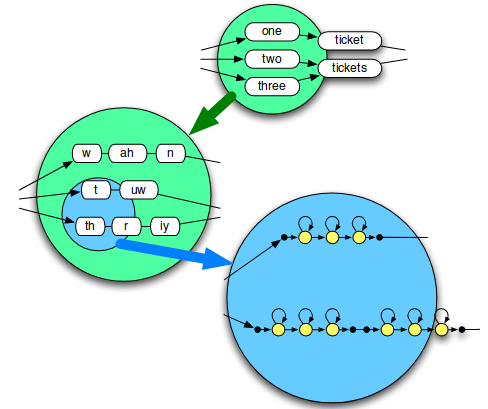
JSGF
JSpeech Grammar Format是一个用于描述ASR grammar的规范。
官网:
https://www.w3.org/TR/jsgf/
GMM-HMM
混合高斯模型是为了计算某个观察状态的mfcc分布和某个特定音子的mfcc之间的似然度的,但由于音子的mfcc分布并不是真的符合高斯分布,因此需要叠加多个高斯混合模型,来逼近某个特定音子的mfcc特征分布。我们叠加的模型数量越多,拟合的效果就越好。
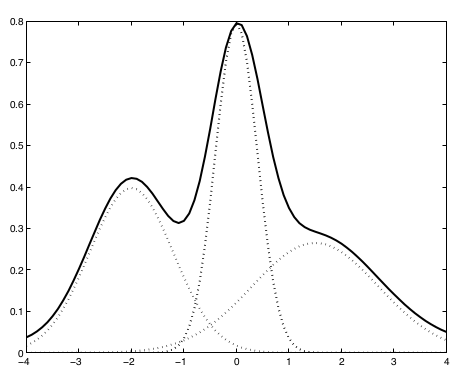
最简单的情况下,每个音子(例如ah这个音子)都需要至少一个39维的多维高斯模型进行建模,但是这样做的前提是,ah这个音的39维mfcc特征的分布符合高斯分布。
但事实上,ah并不完全符合高斯分布,于是我们就用一组(比如10个)高斯模型,混合在一起,去逼近这个音的mfcc特征分布。这样当有一帧通过计算得到一个39维的向量的时候,我们就可以把这个向量带入加权混合后的高斯模型中,计算这个向量属于ah这个音的概率。
以thchs为例,一共有3000个高斯核对音素进行建模,那是如何分配的呢?
如果是triphone模型,那么3000个高斯核每个都会分配一个三音子态。也就是说,每个核只用来建模一个三音子态。要确定这件事,只要看模型文件里有没有用来分配高斯混合模型权重的文件就可以了。
比如在sphinx这个库里面,模型文件中会有一个叫mixture_weight的文件,就是用来储存权重的,如果没有这个文件,意味着每个高斯核只用来建模一个音子态。
虽然音子只有60个,但是排列组合后的三音子态就多达几千个了。
综上,GMM-HMM的本质就是:用GMM提取特征,而用HMM进行分类。
所以,它的后续演化也就不难猜测了——GMM被RNN所取代,而HMM则被CTC loss所取代。
参考:
https://blog.csdn.net/abcjennifer/article/details/27346787
GMM-HMM语音识别模型 原理篇
https://zhuanlan.zhihu.com/p/22482625
无痛理解GMM-HMM语音识别算法
https://mp.weixin.qq.com/s/Sn4RPdghzzQhQc-r4z8Iuw
Kaldi单音素GMM学习笔记
https://mp.weixin.qq.com/s/u-oOQre6LTUfMBu2XlHknA
基于HMM-GMM的语音识别算法介绍
LDA-MLLT
Maximum Likelihood Linear Transform (MLLT),又名Global Semi-tied Covariance (STC)。因此,在科技文献中,常被称作STC/MLLT。
《Semi-tied Covariance Matrices for Hidden Markov Models》
《Improved feature processing for Deep Neural Networks》

https://blog.csdn.net/xmdxcsj/article/details/78512652
声学特征变换 STC/MLLT
WFST
概述
Weighted Finite State Transducer是目前解码器模块的关键技术。
论文:
《Speech Recognition with Weighted Finite-State Transducers》
Mehryar Mohri,法国人,Ecole Polytechnique本科+ENS Ulm硕士+University of Paris 7博士。New York University教授。Google研究顾问。
个人主页:
https://cs.nyu.edu/~mohri/
https://cs.nyu.edu/~mohri/courses.html
这是Mohri的课程主页。
https://cs.nyu.edu/~mohri/asr12/
作为WFST的发明人,Mohri的Speech Recognition课程在解码器方面有相当大的篇幅。
书籍:
《peech Recognition Algorithms Using Weighted Finite-State Transducers》,TakaakiHori AtsushiNakamura著
此外,OpenFst的官网也有一些教程:
http://openfst.org/twiki/bin/view/FST/FstBackground
OpenFst Background Material
其中,最重要的是两个tutorial:
http://openfst.org/twiki/bin/view/FST/FstHltTutorial
OpenFst: An Open-Source, Weighted Finite-State Transducer Library and its Applications to Speech and Language
http://openfst.org/twiki/bin/view/FST/FstSltTutorial
OpenFst: a General and Efficient Weighted Finite-State Transducer Library
blog:
https://blog.csdn.net/fengzhou_
一个WFST的专栏
以下内容主要参考下文:
http://vsooda.github.io/2016/08/28/wfst/
加权有限状态转换器

您的打赏,是对我的鼓励
