speech » 语音识别(三)——声源定位
2018-04-23 :: 4660 WordsMicrophone
Microphone Array与语音交互技术架构(续)
2.以科胜讯为代表的纯前端技术架构。纯前端方案的优点就是容易集成到芯片上,缺点就是很难升级以及扩展,这恰好与人工智能不断迭代的趋势不太兼容,也是当前这种方案无法流行的主要原因。
这类方案能提供的功能有限,主要包括自适应回声抵消技术(AEC)、自动噪音抑制技术(ANS)和自动增益控制技术(AGC)。
3.以Amazon为代表的前端+云端方案。这种方案是把算法分别放置到前端和云端,根据具体场景可以调配优化,更容易优化性能并扩展功能。这种方案考虑了麦克风阵列与唤醒和识别技术一体化的问题,由于唤醒和识别严重依赖麦克风阵列的算法处理效果,实际上这三种技术是无法完全分割的,特别是麦克风阵列和唤醒技术更是浑然一体。
参考:
https://zhuanlan.zhihu.com/p/29809882
让机器听懂人类语言,主流麦克风阵列技术解读
https://zhuanlan.zhihu.com/p/23420891
麦克风阵列的语音信号处理技术
Microphone Array技术难点
传统的阵列信号处理技术直接应用到麦克风阵列处理系统中往往效果不理想,其原因在于麦克风阵列处理有不同的处理特点:
阵列模型的建立
麦克风主要应用处理语音信号,拾音范围有限,且多用于近场模型,使得常规的阵列处理方法如雷达,声呐等平面波远场模型不再适用,在近场模型中,需要更加精准的球面波,需要考虑传播路径不同引起的幅度衰减不同。
宽带信号处理
通常的阵列信号处理多为窄带,即不同阵元在接受时延与相位差主要体现在载波频率,而语音信号未经过调制也没有载波,且高低频之比较大,不同阵元的相位延时与声源本身的特性关系很大—频率密切相关,使得传统的阵列信号处理方法不再完全适用。
非平稳信号处理
传统阵列处理中,多为平稳信号,而麦克风阵列的处理信号多是非平稳信号,或者短时平稳信号,因此麦克风阵列一般对信号做短时频域处理,每个频域均对应一个相位差,将宽带信号在频域上分成多个子带,每个子带做窄带处理,再合并成宽带谱。
混响
声音传播受空间影响较大,由于空间反射,衍射,麦克风收到的信号除了直达信号以外,还有多径信号叠加,使得信号被干扰,即为混响。在室内环境中,受房间边界或者障碍物衍射,反射导致声音延续,极大程度的影响语音的可懂度。
声源定位
近场模型和远场模型
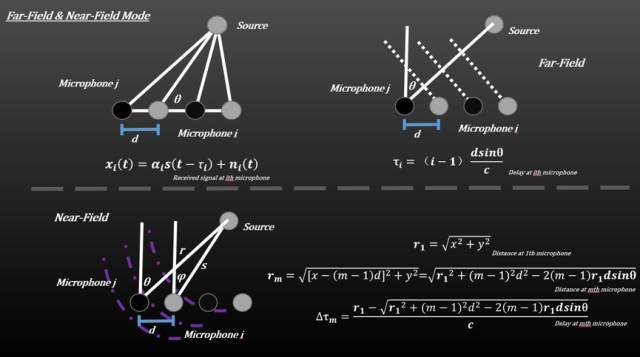
通常麦克风阵列的距离为1~3m,这属于近场模型,麦克风阵列接受的是球面波而不是平面波,声波在传播的过程中会发生衰减,而衰减因子与传播的距离成正比,因此声波从声源到达阵元时候的幅度也各不相同。而远场模型中,声源到阵元的距离差相对较小,可以忽略。通常,我们定义\(2L^2/\lambda\)为远近场临界值,L为阵列孔径,λ为声波波长,因此阵元接受信号不仅有相位延时还有幅度衰减。
参考:
https://www.zhihu.com/question/48537863
远场(far-field)语音识别的主流技术有哪些?
https://mp.weixin.qq.com/s/1GjBWW5gn2WQb1GWExtB5A
HOA声场重建原理
波束形成
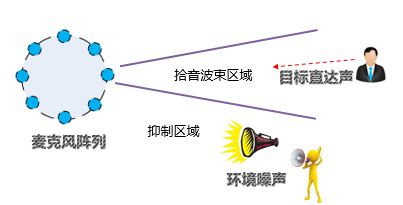
声源定位的方法包括波束形成,超分辨谱估计和TDOA,分别将声源和阵列之间的关系转变为空间波束,空间谱和到达时间差,并通过相应的信息进行定位。
波束形成是通用的信号处理方法,这里是指将一定几何结构排列的麦克风阵列的各麦克风输出信号经过处理(例如加权、时延、求和等)形成空间指向性的方法。波束形成主要是抑制主瓣以外的声音干扰,这里也包括人声,比如几个人围绕Echo谈话的时候,Echo只会识别其中一个人的声音。
波束形成可分为常规的波束形成CBF(Conventional Beam Forming)、CBF+Adaptive Filter和自适应波束形成ABF(Adaptive Beam Forming)。
超分辨谱估计
如MUSIC,ESPRIT等,对其协方差矩阵(相关矩阵)进行特征分解,构造空间谱,关于方向的频谱,谱峰对应的方向即为声源方向。适合多个声源的情况,且声源的分辨率与阵列尺寸无关,突破了物理限制,因此成为超分辨谱方案。这类方法可以拓展到宽带处理,但是对误差十分敏感,如麦克风单体误差,通道误差,适合远场模型,矩阵运算量巨大。
TDOA
TDOA(time difference of arrival)是先后估计声源到达不同麦克风的时延差,通过时延来计算距离差,再利用距离差和麦克风阵列的空间几何位置来确定声源的位置。分为TDOA估计和TDOA定位两步:
TDOA估计
常用的有广义互相关GCC(Generalized Cross Correlation)和LMS自适应滤波。
TDOA定位
TDOA估值进行声源定位,三颗麦克风阵列可以确定空间声源位置,增加麦克风会增高数据精度。定位的方法有MLE最大似然估计,最小方差,球形差值和线性相交等。
TDOA相对来讲应用广泛,定位精度高,且计算量最小,实时性好,可用于实时跟踪,在目前大部分的智能定位产品中均采用TDOA技术做为定位技术。
参考
https://wenku.baidu.com/view/903f907f31b765ce05081431.html
基于传声器阵列的声源定位
https://zhuanlan.zhihu.com/p/35590325
MIT提出像素级声源定位系统PixelPlayer:无监督地分离视频中的目标声源
https://zhuanlan.zhihu.com/p/27921878
揭秘武林绝学——“听声辨位”
其他前端问题
语音增强
语音增强是指当语音信号被各种各样的噪声(包括语音)干扰甚至淹没后,从含噪声的语音信号中提取出纯净语音的过程。
去混响(Dereverberation)
一般我们听音乐时,希望有混响的效果,这是听觉上的一种享受。合适的混响会使得声音圆润动听、富有感染力。混响(Reverberation)现象指的是声波在室内传播时,要被墙壁、天花板、地板等障碍物形成反射声,并和直达声形成叠加,这种现象称为混响。
但是,混响现象对于识别就没有什么好处了。由于混响则会使得不同步的语音相互叠加,带来了音素的交叠掩蔽效应(Phoneme Overlap Effect),从而严重影响语音识别效果。
影响语音识别的部分一般是晚期混响部分,所以去混响的主要工作重点是放在如何去除晚期混响上面,多年来,去混响技术抑制是业界研究的热点和难点。利用麦克风阵列去混响的主要方法有以下几种:
(1)基于盲语音增强的方法(Blind signal enhancement approach),即将混响信号作为普通的加性噪声信号,在这个上面应用语音增强算法。
(2)基于波束形成的方法(Beamforming based approach),通过将多麦克风对收集的信号进行加权相加,在目标信号的方向形成一个拾音波束,同时衰减来自其他方向的反射声。
(3)基于逆滤波的方法(An inverse filtering approach),通过麦克风阵列估计房间的房间冲击响应(Room Impulse Response, RIR),设计重构滤波器来补偿来消除混响。
声源信号提取
家里人说话太多,DingDong听谁的呢。这个时候就需要DingDong聪明的辨别出哪个声音才是指令。而麦克风阵列可以实现声源信号提取,声源信号的提取就是从多个声音信号中提取出目标信号,声源信号分离技术则是将需要将多个混合声音全部提取出来。
利用麦克风阵列做信号的提取和分离主要有以下几种方式:
(1)基于波束形成的方法,即通过向不同方向的声源分别形成拾音波束,并且抑制其他方向的声音,来进行语音提取或分离;
(2)基于传统的盲源信号分离(Blind Source Separation)的方法进行,主要包括主成分分析(Principal Component Analysis,PCA)和基于独立成分分析(Independent Component Analysis,ICA)的方法。
回声抵消
严格来说,这里不应该叫回声,应该叫“自噪声”。回声是混响的延伸概念,这两者的区别就是回声的时延更长。一般来说,超过100毫秒时延的混响,人类能够明显区分出,似乎一个声音同时出现了两次,我们就叫做回声,比如天坛著名的回声壁。
实际上,这里所指的是语音交互设备自己发出的声音,比如Echo音箱,当播放歌曲的时候若叫Alexa,这时候麦克风阵列实际上采集了正在播放的音乐和用户所叫的Alexa声音,显然语音识别无法识别这两类声音。回声抵消就是要去掉其中的音乐信息而只保留用户的人声,之所以叫回声抵消,只是延续大家的习惯而已,其实是不恰当的。
参考
https://zhuanlan.zhihu.com/p/27977550
极限元:智能语音前端处理中的几个关键问题
https://zhuanlan.zhihu.com/p/24139910
远场语音交互中的麦克风阵列技术解读
https://zhuanlan.zhihu.com/p/22512377
自然的语音交互——麦克风阵列
https://zhuanlan.zhihu.com/p/43279047
远场语音识别面临的瓶颈与挑战
https://mp.weixin.qq.com/s/Xc-OmRpDPgw2qIgswsCeSA
从嘈杂视频中提取超清人声,语音增强模型PHASEN已加入微软视频服务
https://mp.weixin.qq.com/s/NK5HWZT-I5-opGo_DQ7kCQ
华为提出新的在线视觉语音增强构架OVAnet,可通过视觉模态增强声学模型性能
语言模型
语言模型是针对某种语言建立的概率模型,目的是建立一个能够描述给定词序列在语言中的出现的概率的分布。
给定下边两句话:
定义机器人时代的大脑引擎,让生活更便捷、更有趣、更安全。
代时人机器定义引擎的大脑,生活让更便捷,有趣更,安更全。
语言模型会告诉你,第一句话的概率更高,更像一句”人话”。
语言模型技术广泛应用于语音识别、OCR、机器翻译、输入法等产品上。语言模型建模过程中,包括词典、语料、模型选择,对产品的性能有至关重要的影响。Ngram模型是最常用的建模技术,采用了马尔科夫假设,目前广泛地应用于工业界。
语言模型属于NLP的范畴,这里不再赘述。
参考:
https://zhuanlan.zhihu.com/p/23504402
语言模型技术

您的打赏,是对我的鼓励
