speech » 语音识别(二)——基本框架, Microphone Array
2018-04-17 :: 5007 Words概述
数据集(续)
http://pan.baidu.com/s/1dEhUghz
清华大学语音和语言技术研究中心(CSLT)公开的数据集。这个数据集除了包含thchs30之外,还包含了其他几个小语种的数据集。
http://cn-mirror.openslr.org/18/
单独的thchs30数据集
http://blog.csdn.net/sut_wj/article/details/70662181
THCHS-30:一个免费的中文语料库
http://cn-mirror.openslr.org/33/
AISHELL数据库是THCHS-30之后,目前中文语音数据开源最大的数据库。
它是由北京希尔贝壳科技有限公司(http://www.aishelltech.com)录制的中文普通话数据。由400名来自不同方言区的发音人录制,男女比例均衡。按照设计好的文本,在相对安静环境中使用手机(Android和IOS系统)录制格式为16kHz、16bit单声道数据和高保真麦克风录制格式为44.1kHz、16bit单声道数据同时采集。
http://www.aishelltech.com/aishell_2
AISHELL-2的数据规模达到1000小时和更优秀的系统级recipe。数据目前以硬盘和网盘形式免费开放给高校科研教育机构。商用似乎还是要钱的。
https://keithito.com/LJ-Speech-Dataset/
The LJ Speech Dataset
这是由LibriVox项目的Linda Johnson制作的数据集。
LibriVox项目是一个公益性质的有声电子书项目。
官网:
https://librivox.org/
https://mp.weixin.qq.com/s/f_oFRDuSAuqwbOAby07a5Q
CN-Celeb:中国明星声纹数据集发布
https://catalog.ldc.upenn.edu/LDC93S1
TIMIT数据集(收费)
https://mp.weixin.qq.com/s/w9_D1_VVhk9md4RANaipDg
Mozilla开源语音识别模型和世界第二大语音数据集
http://www.voxforge.org/
VoxForge是一个非常活跃的众包语音识别数据库和经过训练的模型库
https://mp.weixin.qq.com/s/jvxUkwfPf3kqqdnvTQLlkA
CoVoST:Facebook发布的多语种语音-文本翻译语料库
https://mp.weixin.qq.com/s/opP5-gPGAKJT16nXaoOAWg
Google发布的语音分离数据集与深度学习模型
https://mp.weixin.qq.com/s/eogV9SPfXGgLOJYnsVFzsQ
世界最大的多语言语音数据集现已开源(VoxPopuli)
基本框架
语音识别系统主要有四部分组成:信号处理和特征提取、声学模型、语言模型(Language Model, LM)和解码器(Decoder)。
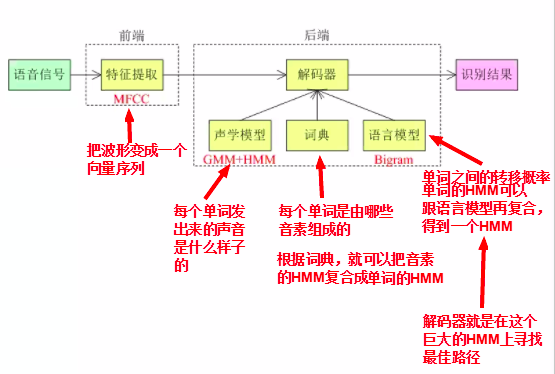
信号处理和特征提取部分以音频信号为输入,通过消除噪音、信道失真等对语音进行增强,将语音信号从时域转化到频域,并为后面的声学模型提取合适的特征。
声学模型将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入,生成声学模型得分。
语言模型估计通过重训练语料学习词之间的相互概率,来估计假设词序列的可能性,也即语言模型得分。如果了解领域或者任务相关的先验知识,语言模型得分通常可以估计得更准确。
解码器对给定的特征向量序列和若干假设词序列计算声学模型得分和语言模型得分,将总体输出分数最高的词序列作为识别结果。
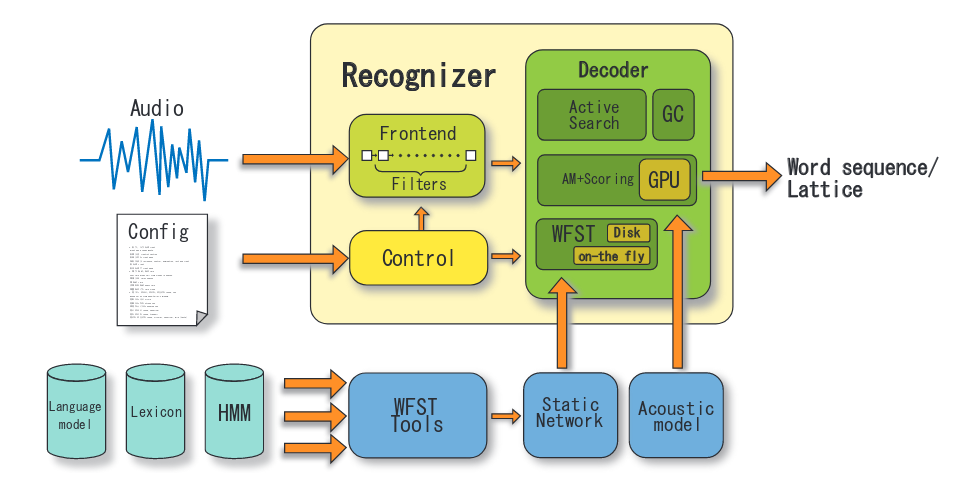
上图是一个实际的recognition engine的结构图。其原文地址:
https://eprints.lib.hokudai.ac.jp/dspace/bitstream/2115/39654/1/MP-SS1-4.pdf
王赟写的《语音识别技术的前世今生》,写的非常好,下载地址:
https://zhihu-live.zhimg.com/0af15bfda98f5885ffb509acd470b0fa
王赟,清华本科(2010)+CMU在读博士。
个人主页:
http://www.cs.cmu.edu/~yunwang/
下面是网友写的注解版本:
http://www.cnblogs.com/lyu0709/p/6929659.html
《语音识别的前世今生:GMM+HMM & 深度学习》讲座笔记
http://www.cnblogs.com/lyu0709/p/6929692.html
《语音识别的前世今生》Q&A
参考:
https://blog.csdn.net/by21010/article/details/51506292
语音识别系统结构——鸟瞰
http://www.cnblogs.com/welen/p/7489504.html
语音识别概述
https://www.zhihu.com/question/20398418
语音识别的技术原理是什么?
https://mp.weixin.qq.com/s/_jK4eTdboU9A-E785FUBJg
语音识别基础:(一)语音是什么
https://mp.weixin.qq.com/s/XRTCCcEdmQTk4XitVo8U2Q
语音识别基础:(二)语音识别方法
https://mp.weixin.qq.com/s/e4bO-koOmIrAfqC-zwOvwg
语音识别基础:(三)完整的语音识别实验
https://mp.weixin.qq.com/s/wowvIK5sspVR7ogF-3keYA
语音识别基础:(四)前端处理
https://mp.weixin.qq.com/s/uUCIm4YBQ0pTfzWnF_YaLQ
语音识别基础:(五)训练与解码
https://mp.weixin.qq.com/s/jOACb1YelVHovpe-r-fkZA
语音识别概论
Microphone
麦克风作为业界通俗的一种叫法,是英文Microphone的音译名称,国内的称呼乱一些,有时候也简单称作话筒,香港和台湾地区也会称作微音器、拾音器。麦克风的中文学术名称是传声器,这是一种将声音转换成电子信号的换能器,即把声信号转成电信号,这其实和光电转换的原理是完全一致的。
消费级市场的麦克风基本都是标量麦克风,也就说只能采集单一的物理量信息——声压。声压是指声波通过媒质时,由振动所产生的压强改变量,也可以理解为声音的幅度或者强度。声压常用字母”p”表示,单位是帕斯卡(符号Pa)。声压的帕斯卡单位由于不方便记忆(比如\(20\times 10^{-6}\)Pa~20Pa),一般就以对数尺衡量有效声压相对于一个基准值的大小来表示,即声压级,其单位是分贝(符号dB)。
人类对于1KHz的声音的听阈为\(20\times 10^{-6}\)Pa,通常以此作为声压级的基准值。这样讲可能晦涩难懂,我们来简单的类比一下:人类的呼吸声压是\(60\times 10^{-6}\)左右,声压级大约10dB,火箭发射的声压是4000Pa左右,声压级大约165dB,闪光弹的声压超过1万Pa,声压级大约175dB。
为了描述麦克风的性能,有几个性能指标是非常关键的,这包括了灵敏度、指向性、频率响应、阻抗、动态范围、信噪比、最大声压级(或AOP,声学过载点)、一致性等。
现在麦克风阵列主要使用的是数字MEMS麦克风,其最长尺寸仅有3.76MM。MEMS麦克风也是手机中大量使用的传感器件,一般手机至少有2个以上这类麦克风。MEMS麦克风实际上只是工艺上的改进,其原理依然属于电容式麦克风。
与MEMS麦克风直接PK的,就是驻极体麦克风。它的性能更优秀,但一致性不如MEMS麦克风,因此主要用在单麦上。而麦克风阵列一般都是MEMS麦克风。
驻极体和MEMS原理差不多,都是空气压强变化引起振膜的振动,带动电容值发生了变化,最后产生了电压变化。这种电压变化和空气压强的变化之间有接近线性的相对关系。这样就完成了声能到电能的转换。区别在于驻极体在生产的时候就注入了一定的永久电荷,形成固定的电势,而MEMS需要电源给予电压来保证电势的恒定。
被淘汰的技术:带式麦克风、碳精麦克风(老式电话)。
先进技术:压电麦克风、光纤麦克风、激光麦克风、矢量麦克风。
Microphone的主要厂商:
1.Knowles 美国
2.瑞声(AAC) 中国
3.歌尔(Goertek) 中国
4.BSE 韩国
5.ST 欧洲
参考:
https://zhuanlan.zhihu.com/p/27610503
盘点麦克风技术及市场,远场语音交互如何选型麦克风
https://mp.weixin.qq.com/s/6PI8t8uRGPk_Zy0d3uwzGw
语音交互设备对麦克风选型和结构设计的要求
https://mp.weixin.qq.com/s/itCYxYgQqDLjISRuXZbE_g
MEMS麦克风产业现状及发展趋势
Microphone Array
麦克风阵列(Microphone Array),从字面上,指的是麦克风的排列。也就是说由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统。

上图是Amazon Echo所采用的6+1麦克风阵列。
根据声波传导理论,利用多个麦克风收集到的信号可以将某一方向传来的声音增强或抑制。利用这种方法,麦克风阵列可以将噪声环境中特定声音信号有效的增强。由于麦克风阵列技术具有很好的抑制噪声和语音增强的能力,又不需要麦克风时刻指向声源方向,因此在语音处理领域具有非常好的前景,可以用在非常广的应用领域。
Microphone Array形状
麦克风阵列一般来说有线形、环形和球形之分,严谨的应该说成一字、十字、双L、平面、螺旋、球形等。
至于麦克风阵列的阵元数量,也就是麦克风数量,可以从2个到上千个不等。由于成本限制,消费级麦克风阵列的阵元数量一般不超过8个,所以市面上最常见的就是6麦和4麦的阵型。
智能音箱一般都是放置桌面,需要360度响应指令,所以环形阵列比较适合,而智能中控一般贴墙固定,仅照顾180度范围即可,这时候线形阵列就能满足。
双麦克风阵列:结构简单、成本低、容易实施、功耗低。
像空调、电视这类家电产品,它永远都是贴墙放,八个麦克风在实际应用上是多余的。而双麦克技术在任何产品上均可自然适配。
在机器人领域里,对声源定位的要求比较高,所以一般都会使用环形多麦克方案。这两年国内比较火的Rokid机器人就采用了8麦克的阵列。
参考:
https://www.leiphone.com/news/201610/5Ye8zxxwtlLGiW1y.html
技术解读:从亚马逊Echo到谷歌Home,双麦克风阵列更有优势?
Microphone Array vs 人耳
偶尔会听到行业人士做的一个类比,人类有两只耳朵,所以两个麦克风就能达到同样性能。这实际上是一个误解,以现在技术来看,即便用100个麦克风,也未必能达到人耳的效果。人耳是极其复杂的一个结构,至今为止实际上科学也没搞清楚所有原理,更谈不上用简单的麦克风进行模拟了。现在的麦克风,实际上都是标量麦克风,所获取的仅仅是声压变化转成的电信号,而且还没有耳廓,更无法根据场景变化随动调整。
Microphone Array与语音交互技术架构
前端主要解决了产品是否听得准的问题,这其中有五个核心指标:远场语音唤醒率、复杂环境 误唤醒率、远场语音识别率、总体延迟时间和总体稳定性。这五个核心指标决定了用户的第一体验。
1.以Google为代表的纯云端技术架构。麦克风阵列的阵元较多,产生的数据容量太大,而当前的网络上传带宽严重不足,所以只能权衡选择更少的麦克风。

您的打赏,是对我的鼓励
