speech » 语音识别(一)——概述
2018-04-16 :: 6727 Words概述
虽然现在的语音识别中,DL已经应用的非常广泛了,但是语音识别终究还是有一些领域知识的,将之归类为DL或者ML,似乎都不妥当。特形成本系列文章,用以描述automatic speech recognition的领域知识和传统方法。
说起来还是要感谢DL,不然按照传统的行业划分,几乎不会有人同时研究CV和ASR。DL的出现,实际上大大降低了算法的领域迁移成本,领域知识的重要性相对下降了。
历史
早在电子计算机出现之前,人们就有了让机器识别语音的梦想。1920年生产的“Radio Rex”玩具狗可能是世界上最早的语音识别器,当有人喊“Rex”的时候,这只狗能够从底座上弹出来。

但实际上它所用到的技术并不是真正的语音识别,而是通过一个弹簧,这个弹簧在接收到500赫兹的声音时会自动释放,而500赫兹恰好是人们喊出“Rex”中元音的第一个共振峰。
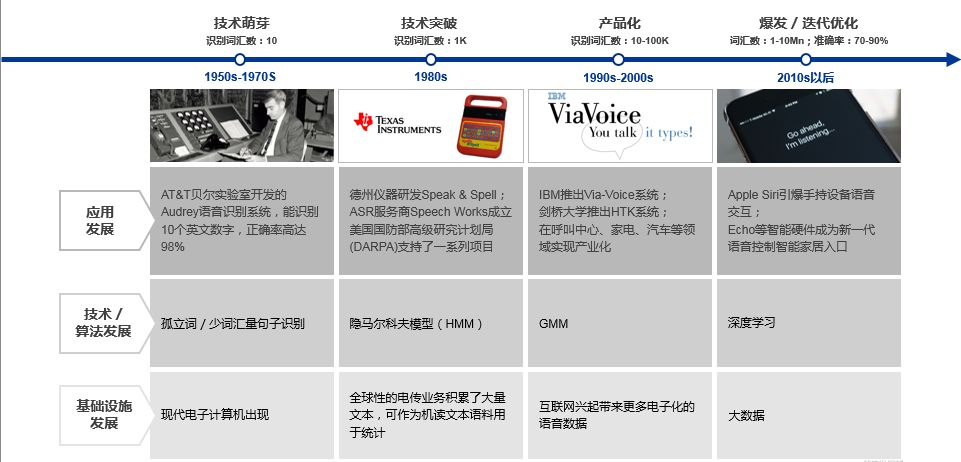
参考:
https://zhuanlan.zhihu.com/p/82872145
语音识别技术简史
https://mp.weixin.qq.com/s/0yZ_8uGDXyxZKAEEdmkebA
完整声学极简史
相关任务
语音相关的任务主要有:
-
Automatic speech recognition(ASR):将一个speech序列映射为一个character序列。
-
Speech to text translation (ST):将source语言上的一个speech序列映射为target语言上的一个character序列。
-
Text to speech (TTS):将一个character序列映射为一个speech序列。
-
Speech enhancement (SE):将一个noisy的speech序列映射为一个clean的speech序列。
-
Speech separation (SS):分离不同说话人的speech,或者分离人声和背景声音。
-
Speech-to-speech translation (S2ST)
学校
ASR领域最牛的高校主要是美国的CMU、Johns Hopkins University、英国的Cambridge University和日本的东京大学。
书籍
《Speech and Language Processing: An introduction to natural language processing, computational linguistics, and speech recognition》,Daniel Jurafsky & James H. Martin著。
Daniel Jurafsky,1962年生,UCB本科(1983)+博士(1992)。斯坦福大学教授。
个人主页:
https://web.stanford.edu/~jurafsky/
James H. Martin,哥伦比亚大学本科+UCB博士。University of Colorado Boulder教授。
个人主页:
http://www.cs.colorado.edu/~martin/
这本书比较老了(1999年),但毕竟是本1000页左右的书,传统方法该说的基本都说了。主要问题在于NLP和语义学的内容较多,相对来说ASR的内容就少了些。
这本书在2008年出了第2版(改动较小),如今第3版也在酝酿中,草稿可在如下网页获得:
https://web.stanford.edu/~jurafsky/slp3/
新版大幅增加了深度学习的内容。
《Spoken Language Processing-A Guide to Theory, Algorithm and System Development》,黄学东等著。
这本书基本上是ASR传统方法的大全了,无论理论还是工程实践都有相当大的篇幅,但也有些老了(2001年)。
《解析深度学习:语音识别实践》,俞栋、邓力著。
这本书算是中文写的比较好的教程了,而且DL的篇幅很大,内容非常新。(2016年)
教程
http://tts.speech.cs.cmu.edu/courses/11492/schedule.html
Speech Processing。CMU的这个教程主要包含ASR(Automatic Speech Recognition)、TTS(Text To Speech)和SDS(Spoken Dialog Systems)等三方面的内容。
Alan W Black,苏格兰计算机科学家。Coventry University本科(1984)+University of Edinburgh硕博(1984,1993)。CMU教授。语音处理专家。
个人主页:
http://www.cs.cmu.edu/~awb/
他的主页上有好多Speech、NLP方面的教程。他本人长得太像Java之父James Gosling了。
http://web.stanford.edu/class/cs224s/index.html
CS224S / LINGUIST285 - Spoken Language Processing。Stanford的教程相对比较新,DL涉及的比较多。
http://www.inf.ed.ac.uk/teaching/courses/asr/index.html
Automatic Speech Recognition。这个课程至少从2012年就开始了,每年都有更新。
http://speech.ee.ntu.edu.tw/DSP2018Spring/
国立台湾大学李琳山教授的课程。
李琳山,国立台湾大学本科(1974)+Stanford博士(1977)。国立台湾大学教授。
http://www.cs.cmu.edu/afs/cs/user/bhiksha/WWW/courses/11-756.asr/spring2014/
Theory and practice of speech recognition systems。CMU的Bhiksha Raj教授的课程,只有ASR的内容。
顺便说一句,Bhiksha Raj的主页上还有好多其他课程。
https://cs.nyu.edu/~eugenew/asr13/
这是MIT博士Eugene Weinstein在NYU当助教的时候(2013年)开的课程。
http://berlin.csie.ntnu.edu.tw/Courses/Speech%20Processing/Speech%20Processing_Main_2016S.htm
Speech Processing。国立台湾师范大学的陈柏琳教授的课程。陈教授教学多年,主页上还有好多其他课程。
https://www.isip.piconepress.com/courses/msstate/ece_8463/lectures/current/index.html
Mississippi State University:ECE 8463: fundamentals of speech recognition
https://www.isip.piconepress.com/courses/msstate/ece_7000_speech/index.html
ECE 8000: special topics in speech recognition
https://www.isip.piconepress.com/courses/msstate/ece_8990_info/index.html
ECE 8990: Information Theory。这门课偏重数学理论,包括Entropy、Markov Processes、Kolmogorov Complexity等内容,适合用于补数学基础。
http://courses.cs.tamu.edu/rgutier/csce630_f14/
CSCE 630: Speech Processing
http://courses.cs.tamu.edu/rgutier/cpsc689_s07/
CPSC 689-604: Special topics in Speech and Face Recognition
https://mp.weixin.qq.com/s/oaOkla9gnUKr2C6PSjE2BA
语音识别中的End-to-End模型教程(附178页PDF全文下载)
https://mp.weixin.qq.com/s/i7JaDoU2L7uRYsw8FTR3jA
语音研究进阶指南
blog
http://www.cnblogs.com/welen/
https://blog.csdn.net/weiqiwu1986
上面两个都是welen的blog,而且内容貌似还不重复。。。
http://blog.csdn.net/xmdxcsj
一个语音识别的blog
https://blog.csdn.net/shichaog
一个语音识别+Kaldi的blog
https://blog.csdn.net/quhediegooo/
一个语音识别的blog
https://blog.csdn.net/dearwind153/article/category/6506891
这哥们的blog很杂,这是语音相关的专栏
http://www.cnblogs.com/JarvanWang/
一个语音识别+Kaldi的blog
https://www.zhihu.com/question/65516424
语音识别kaldi该如何学习?
http://vsooda.github.io/archive/
一个语音识别+DL的blog
https://zhuanlan.zhihu.com/codingmath
一个语音识别的blog
https://blog.csdn.net/jojozhangju
一个Kaldi+声源定位的blog
项目
https://en.wikipedia.org/wiki/List_of_speech_recognition_software
List of speech recognition software
https://mp.weixin.qq.com/s/LsVhMaHrh8JgfpDra6KSPw
横向对比5大开源语音识别工具包
https://github.com/lingochamp/kaldi-ctc
英语流利说开源的kaldi-ctc
https://zhuanlan.zhihu.com/p/23177950
kaldi-ctc: CTC End-to-End ASR
https://mp.weixin.qq.com/s/VkKFQ0fOOHJw0p7Z4EDugQ
绝佳的ASR学习方案:这是一套开源的中文语音识别系统
HTK
Hidden Markov Model Toolkit是Cambridge University开发的语音识别的工具包。它是GMM-HMM时代最为流行的语音识别工具,但近来流行度不如Kaldi。
官网:
http://htk.eng.cam.ac.uk/
HTK Book不仅是使用手册,也是一本介绍原理的书。
http://speech.ee.ntu.edu.tw/homework/DSP_HW2-1/htkbook.pdf
CMU Sphinx
CMU Sphinx是李开复的博士课题项目,后来成为了CMU的长期项目。洪小文、黄学东也先后参与过。该项目比较早的将HMM应用于语音识别,这在当时算是一个重大创新。
李开复,1961年生,Columbia University本科(1983)+CMU博士(1988)。先后供职于Apple、SGI、Microsoft、Google。现为创新工场董事长。
洪小文,1963年生,台湾大学本科+CMU博士。先后供职于Apple、Microsoft,现为微软亚洲研究院院长。
黄学东,1962年生,湖南大学本科(1982)+清华大学硕士(1984)+University of Edinburgh博士(1989)。现为微软首席语音科学家。
Raj Reddy,1937年生,印度裔美国计算机科学家。印度University of Madras本科(1958)+澳大利亚University of New South Wales硕士(1960)+Stanford University博士。CMU教授,首位亚裔图灵奖得主(1994)。
他还是印度Rajiv Gandhi University of Knowledge Technologies创始人和International Institute of Information Technology, Hyderabad主席。
他是李开复、洪小文的博士导师,黄学东的博士后导师。
官网:
https://cmusphinx.github.io/
注意:还有一个类似Elasticsearch的文本搜索引擎也叫Sphinx。它的官网是:
http://sphinxsearch.com/
SPTK
The Speech Signal Processing Toolkit是日本的几个科学家开发的语音识别工具库。
官网:
http://sp-tk.sourceforge.net/
Julius
Julius是另一个日本人开发的语音识别工具库。
官网:
http://julius.osdn.jp/en_index.php
HTS
HMM/DNN-based Speech Synthesis System也是日本人开发的工具库,主要用于语音合成。
官网:
http://hts.sp.nitech.ac.jp
Praat
Praat是一款跨平台的多功能语音学专业软件,由University of Amsterdam的Paul Boersma和David Weenink开发。主要用于对数字化的语音信号进行分析、标注、处理及合成等实验,同时生成各种语图和文字报表。
官网:
http://www.fon.hum.uva.nl/praat/
公司
http://www.aispeech.com/
思必驰
http://www.soundai.com/
声智科技。偏重于语音信号处理。
https://zhuanlan.zhihu.com/chenxl
声智科技创始人陈孝良的专栏
数据集
http://www.speech.cs.cmu.edu/databases/an4/
The CMU Audio Databases。这个数据集非常老了(1991年),只有64M。
http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz
TensorFlow提供的Speech Commands Datasets
还有相关的工具:
https://github.com/petewarden/extract_loudest_section
抽取一段wav文件中声音最大的那部分
https://www.kaggle.com/davids1992/speech-representation-and-data-exploration/notebook
包含对Speech Commands Datasets的数据处理过程的blog
Google的声音理解团队发布了由200万个人标记的10秒YouTube视频音轨组成的数据集,标签来自600多个音频事件类,数据集命名为Audioset。
https://zhuanlan.zhihu.com/p/157842463
深入解读VGGish
https://mp.weixin.qq.com/s/6D3y-cNT_rJUesCbSW0snw
基于VGGish的声音类别分类在语音机器人的应用实践

您的打赏,是对我的鼓励
