RL » 强化学习(十三)——Exploration & Exploitation, 模仿学习
2020-07-29 :: 5788 Words- Integrating Learning and Planning(续)
- Exploration & Exploitation
- Inverse Reinforcement Learning
- 模仿学习
- RL与神经科学
- RL参考资源
Integrating Learning and Planning(续)
Model-Based RL
优点:
-
比较强的泛化能力。因为当训练完成后,智能体便学到了一个比较好的描述系统的模型,当外界环境变化后,很多时候系统自身的模型是不变的,这样智能体其实是学到了一些通用的东西(即系统本身的模型),当泛化到新的环境时,智能体可以依靠学到的模型去做推理。
-
数据的利用效率高。
缺点:
- 不具有通用性。不同系统的Model是不一样的。
Exploration & Exploitation
几个基本的探索方法:
-
朴素探索(Naive Exploration): 在贪婪搜索的基础上增加一个\(\epsilon\)以实现朴素探索;
-
乐观初始估计(Optimistic Initialization): 优先选择当前被认为是最高价值的行为,除非新信息的获取推翻了该行为具有最高价值这一认知;
-
不确定优先(Optimism in the Face of Uncertainty): 优先尝试不确定价值的行为;
-
概率匹配(Probability Matching): 根据当前估计的概率分布采样行为;
-
信息状态搜索(Information State Search): 将已探索的信息作为状态的一部分联合个体的状态组成新的状态,以新状态为基础进行前向探索。
根据搜索过程中使用的数据结构,可以将搜索分为:
-
依据状态行为空间的探索(State-Action Exploration)。针对每一个当前的状态,以一定的算法尝试之前该状态下没有尝试过的行为。
-
参数化搜索(Parameter Exploration)。直接针对策略的函数近似,此时策略用各种形式的参数表达,探索即表现为尝试不同的参数设置。
Parameter Exploration的优点:得到基于某一策略的一段持续性的行为。
缺点:对个体曾经到过的状态空间毫无记忆,也就是个体也许会进入一个之前曾经进入过的状态而并不知道其曾到过该状态,不能利用已经到过这个状态这个信息。
参考:
https://mp.weixin.qq.com/s/FX-1IlIaFDLaQEVFN813jA
探索(Exploration)还是利用(Exploitation)?强化学习如何tradeoff?
https://mp.weixin.qq.com/s/o46wf1dqOqTxfsStA0HcCA
强化学习中的探索与利用,Matteo Pirotta讲解,137页ppt
UCB
\(\epsilon\)-greedy和softmax算法的缺陷:
只关心回报是多少,并不关心每个臂被拉下了多少次,这就意味着,这些算法不再会选中初始回报特别低的臂,即使这个臂的回报只测试了一次。
UCB(The Upper Confidence Bound Algorithm)算法将会不仅仅关注于回报,同样会关注每个臂被探索的次数。
为了进一步刻画每个臂被探索的次数和回报之间的关系,UCB引入了置信区间的概念:
- 每个item的回报均值都有个置信区间,随着试验次数增加,置信区间会变窄(逐渐确定了到底回报丰厚还是可怜)。
- 每次选择前,都根据已经试验的结果重新估计每个item的均值及置信区间。
- 选择置信区间上限最大的那个item。
显然:
- 如果item置信区间很宽(被选次数很少,还不确定),那么它会倾向于被多次选择,这个是算法冒风险的部分;
- 如果item置信区间很窄(备选次数很多,比较确定其好坏了),那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分;
UCB是一种乐观的算法,选择置信区间上界排序,如果是悲观保守的做法,是选择置信区间下界排序。
置信区间的度量有很多方式,由此产生了很多UCB的变种算法。最常用的UCB1算法,采用了如下度量方式:
\[I_i=\bar{x}_i+\sqrt{2\frac{\log t}{n_i}}\]其中\(x_i\)是第i个臂的奖励均值,\(n_i\)是臂i当前累积被选择的次数。
UCB还可以应用到MCTS中,这就是UCT(Upper Confidence Bound Apply to Tree)算法了。即UCT=MCTS+UCB。
参考:
https://www.cnblogs.com/Ryan0v0/p/11366578.html
多臂赌博机问题(MAB)的UCB算法介绍
https://blog.csdn.net/yw8355507/article/details/48579635
UCB算法
https://blog.csdn.net/LegenDavid/article/details/71082124
LinUCB算法
https://zhuanlan.zhihu.com/p/32356077
Multi-Armed Bandit: UCB (Upper Bound Confidence)
一些MAB变种
我们前面的讨论默认了环境是不会变化的。而一些MAB问题,这个假设可能不成立,这就好比如果一位玩家发现某个机器的\(p_i\)很高,一直摇之后赌场可能人为降低这台机器吐钱的概率。在这种情况下,MAB问题的环境就是随着时间/玩家的行为会发生变化。
如果概率事先设定好,并且在玩家开始有动作之后也无法更改,我们叫做oblivious adversary setting;如果这个对手在玩家有动作之后还能随时更改自己的设定,那就叫做adaptive adversary setting。
另外一类变种,叫做contextual MAB(cMAB)。几乎所有在线广告推送(dynamic ad display)都可以看成是cMAB问题。在这类问题中,每个arm的回报会和当前时段出现的顾客的特征(也就是这里说的context)有关。
参考:
https://mp.weixin.qq.com/s/8Ks1uayLw6nfKs4-boiMpA
多任务学习时转角遇到Bandit老虎机
Inverse Reinforcement Learning
逆强化学习问题定义:
- 已知:
智能体在变化的环境中的行为
(optional)智能体传感器的数据
(optional)环境的模型
- 求:
最优化的Reward function
逆强化学习研究意义:
-
对动物人类行为用强化学习建模(生物学、计量经济学…)模仿学习。
-
reward function在强化学习里面非常非常重要,是对行为的抽象精简的描述,因此IRL (Inverse Reinforcement Learning)可能是一种很高效的模仿学习范式。
通俗的说法就是:我们用优化控制或强化学习得到的策略能用来解释人类的行为吗?
比如让一个人去拿桌子上的一个橘子,那手的轨迹一定不是一条从起点到目标的直线,而是有一些弯曲的轨迹,也就是带有偏差的较优行为,但是这种偏差其实并不重要,只要最后拿到橘子就行了,也就是说:
1.有过程中一些偏差是不重要的,但另一些偏差就比较重要了(如最后没拿到)。
2.每次拿橘子的动作也是不一样的,因此人的动作带有一定的随机性。
3.我们可以认为人类行为轨迹分布是以最优策略为峰的随机分布。
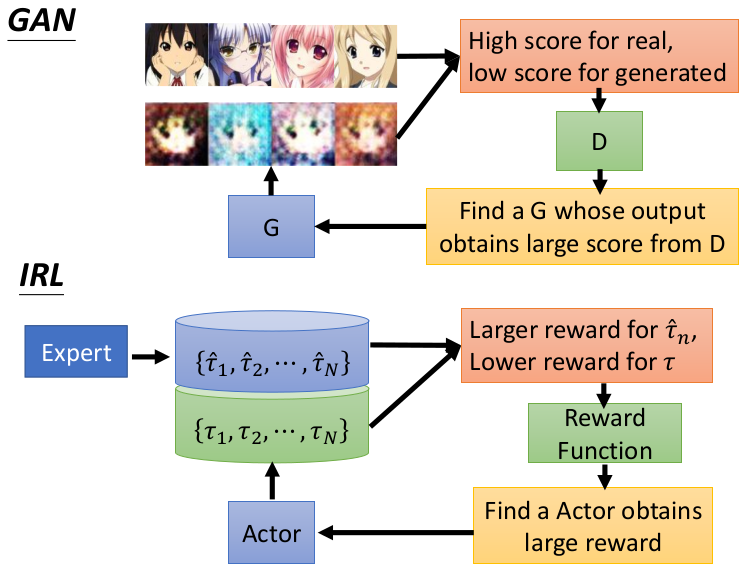
参考:
https://zhuanlan.zhihu.com/p/61674994
Algorithms for Inverse Reinforcement Learning
https://zhuanlan.zhihu.com/p/32502503
CS 294:IRL
模仿学习
虽然RL理论上虽不需要大量标注数据,但实际上它所需求的reward会存在缺陷:
比如游戏AI中,reward的制定非常困难,可能要制定成百上千条游戏规则,这并不比标注大量数据来得容易,又比如自动驾驶的多步决策(sequential decision)场景中,学习器很难频繁地获得reward,容易累计误差导致一些严重的事故.

https://zhuanlan.zhihu.com/p/27935902
机器人学习Robot Learning之模仿学习Imitation Learning的发展
https://zhuanlan.zhihu.com/p/25688750
模仿学习(Imitation Learning)完全介绍
https://mp.weixin.qq.com/s/naq73D27vsCOUBperKto8A
从监督式到DAgger,综述论文描绘模仿学习全貌
https://mp.weixin.qq.com/s/LNNqp2KsEAljG26hY43mUw
ICML2018 模仿学习教程
https://mp.weixin.qq.com/s/f9vSgH1HQwGXBDb0UGHQyQ
深度学习进阶之无人车行为克隆
https://mp.weixin.qq.com/s/To3pnx1hVq_4p7UnQVMw9A
斯坦福大学&DeepMind联合提出机器人控制新方法,RL+IL端到端地学习视觉运动策略
https://mp.weixin.qq.com/s/O0Q1XoTA-7Yshr1ZqOZ90w
加州理工:什么是模仿学习, 这62页ppt带你了解进展
https://mp.weixin.qq.com/s/b1hXMbDKP_QZcBlmY7VtKQ
最新《Imitation Learning》教程,63页ppt,微软Kamil Ciosek
https://mp.weixin.qq.com/s/5_UGxPYRXuuWkwchEUSc9w
最新“模仿学习Imitation Learning”综述论文,21页概述进展与分类
https://blog.csdn.net/v_JULY_v/article/details/135429156
模仿学习的集中爆发:从Dobb·E、Gello到斯坦福Mobile ALOHA、UMI、DexCap、伯克利FMB
RL与神经科学
Pavlov Model(1901)
Rescorla-Wagner Model(1972)
Thorndike’s Puzzle Box(1910)
参考:
https://zhuanlan.zhihu.com/p/24437724
学习理论之Rescorla-Wagner模型
https://zhuanlan.zhihu.com/p/104261195
生物,AI,心理:目前的大脑/认知/意识/AGI/DRL模型
RL参考资源
https://mp.weixin.qq.com/s/sIS9VvZ3yTtn6puJScuHig
强化学习70年演进:从精确动态规划到基于模型
https://mp.weixin.qq.com/s/Fn1s9Ia8L1ckgn6iP24FhQ
如何让神经网络具有好奇心
https://mp.weixin.qq.com/s/PBf-YrkhwhPYXuiOGyahxQ
强化学习遭遇瓶颈!分层RL将成为突破的希望
https://zhuanlan.zhihu.com/p/58815288
强化学习之值函数学习
https://mp.weixin.qq.com/s/8Cqknze_iosz6Z6cqnuK5w
谷歌提出强化学习新算法SimPLe,模拟策略学习效率提高2倍
https://mp.weixin.qq.com/s/hKGS4Ek5prwTRJoMCaxQLA
强化学习Exploration漫游
https://zhuanlan.zhihu.com/p/65116688
值分布强化学习(01)
https://zhuanlan.zhihu.com/p/65364484
值分布强化学习(02)
https://mp.weixin.qq.com/s/xHFIP-tcePb_gwMFqrFuzw
值分布强化学习
https://zhuanlan.zhihu.com/p/62363784
强化学习之策略搜索
https://mp.weixin.qq.com/s/j9Cs5M9gyITu2u_XDkKm-g
Policy Gradient——一种不以loss来反向传播的策略梯度方法
https://mp.weixin.qq.com/s/x6gKTuYIx8y25KX-fCc5bA
蒙特卡洛梯度估计方法(MCGE)简述
https://mp.weixin.qq.com/s/jUKTsJdlBLPWbiBa6TlPPA
基于模型的强化学习—LQR与iLQR
https://mp.weixin.qq.com/s/tv8Tq9hIsll9_aPGUKI8qQ
强化学习《奖励函数设计: Reward Shaping》详细解读
https://zhuanlan.zhihu.com/p/25319023
强化学习(Reinforcement Learning)知识整理
https://mp.weixin.qq.com/s/a3k45oJqzkcy6fpgrf65pA
决策算法,694页pdf阐述不确定性决策算法
https://mp.weixin.qq.com/s/k6llD4Ec9BS-ly04ZtsoJQ
使用GCP开发带有强化学习功能的Roguelike游戏
https://mp.weixin.qq.com/s/ptNDSuMOhbOKwqRrZVzV8Q
不确定性决策与强化学习
https://mp.weixin.qq.com/s/GYfePNhiTGqHUmTFE5hIPw
开局一头狼六只羊,这个狼吃羊的AI火了!傻狼拒绝内卷:抓羊可太累了,我只想自杀…

您的打赏,是对我的鼓励
