ML » 机器学习(二十七)——Stacking, 数据清洗, LSA
2017-08-31 :: 5585 WordsLatent Dirichlet Allocation
LDA(续)
使用模型:对于新来的一篇文档\(doc_{new}\),我们能够计算这篇文档的topic分布\(\overrightarrow{\theta}_{new}\)。
从最终给出的算法可以看出,虽然LDA用到了MCMC和Gibbs Sampling算法,但最终目的并不是生成符合相应分布的随机数,而是求出模型参数\(\overrightarrow{\varphi}\)的值,并用于预测。
这一步实际上是一个分类的过程。可见,LDA不仅可用于聚类,也可用于分类,是一种无监督的学习算法。
如何确定LDA的topic个数
这个问题上,业界最常用的指标包括Perplexity,MPI-score等。简单的说就是Perplexity越小,且topic个数越少越好。
从模型的角度解决主题个数的话,可以在LDA的基础上融入嵌套中餐馆过程(nested Chinese Restaurant Process),印度自助餐厅过程(Indian Buffet Process)等。因此就诞生了这样一些主题模型:
1.hierarchical Latent Dirichlet Allocation (hLDA) (2003_NIPS_Hierarchical topic models and the nested Chinese restaurant process)
2.hierarchical Dirichlet process (HDP) (2006_NIPS_Hierarchical dirichlet processes)/Nested Hierarchical Dirichlet Processes (nHDP)
3.Indian Buffet Process Compound Dirichlet Process (ICD) (2010_ICML_The IBP compound Dirichlet process and its application to focused topic modeling)
4.Non-parametric Topic Over Time (npTOT) (2013_SDM_A nonparametric mixture model for topic modeling over time)
5.collapsed Gibbs Samplingalgorithm for the Dirichlet Multinomial Mixture Model (GSDMM) (2014_SIGKDD_A Dirichlet Multinomial Mixture Model-based Approach for Short Text Clustering)
这些主题模型都被叫做非参数主题模型(Non-parametric Topic Model),最初可追溯到David M. Blei于2003年提出hLDA那篇文章(2003_NIPS_Hierarchical topic models and the nested Chinese restaurant process)。非参数主题模型是基于贝叶斯概率的与参数无关的主题模型。这里的参数无关主要是指模型本身可以“随着观测数据的增长而相应调整”,即主题模型的主题个数能够随着文档数目的变化而相应调整,无需事先人为指定。
参考:
https://www.zhihu.com/question/32286630
怎么确定LDA的topic个数?
http://blog.sina.com.cn/s/blog_4c9dc2a10102vua9.html
Perplexity(困惑度)详解
https://mp.weixin.qq.com/s/VwSmjv03LyqFFseQHJpgdQ
主题模型的主题数确定和可视化
LDA漫游指南
除了rickjin的《LDA数学八卦》之外,马晨写的《LDA漫游指南》也是这方面的中文新作。
该书的数学推导部分主要沿用rickjin的内容,但加入了Blei提出的变分贝叶斯方法。此外,还对LDA的代码实现、并行计算和大数据处理进行了深入的讨论。
参考
http://www.arbylon.net/publications/text-est.pdf
《Parameter estimation for text analysis》,Gregor Heinrich著
http://www.inference.phy.cam.ac.uk/itprnn/book.pdf
《Information Theory, Inference, and Learning Algorithms》,David J.C. MacKay著
关于MCMC和Gibbs Sampling的更多的内容,可参考《Neural Networks and Learning Machines》,Simon Haykin著。该书有中文版。
Sir David John Cameron MacKay,1967~2016,加州理工学院博士,导师John Hopfield,剑桥大学教授。英国能源与气候变化部首席科学顾问,英国皇家学会会员。在机器学习领域和可持续能源领域有重大贡献。
Simon Haykin,英国伯明翰大学博士,加拿大McMaster University教授。初为雷达和信号处理专家。自适应信号处理领域的权威。80年代中后期,转而从事神经计算方面的工作。加拿大皇家学会会员。
http://www.cs.cmu.edu/~epxing/Class/10708-14/lectures/lecture17-MCMC.pdf
http://max.book118.com/html/2015/0513/16864294.shtm
基于LDA分析的词聚类算法
http://www.doc88.com/p-9159009103987.html
基于LDA的博客分类算法
http://blog.csdn.net/sinat_26917383/article/details/52095013
基于LDA的Topic Model变形+一些NLP开源项目
https://mp.weixin.qq.com/s/74lXwDg9H_dyOubfXVn2Bw
一文详解LDA主题模型
https://mp.weixin.qq.com/s/_bAiiJqPjPPMzJ0hiuCkOg
通过Python实现马尔科夫链蒙特卡罗方法的入门级应用
https://mp.weixin.qq.com/s/BJaRUnpcPe8iybSz14gabw
一文读懂如何用LSA、PSLA、LDA和lda2vec进行主题建模
https://zhuanlan.zhihu.com/p/57996219
短文本主题模型
https://mp.weixin.qq.com/s/FalGcZwnL5_Jgt650JtUag
NLP关键字提取技术之LDA算法原理与实践
https://www.zhihu.com/question/298517764
目前有比Topic Model更先进的聚类方式么?比如针对短文本的、加入情感分析的?
Stacking
模型融合的方法除了Bagging和Boosting,还有Stacking。
参考:
https://mp.weixin.qq.com/s/lYj-GVNSDp26czRXbf0iNw
如果你会模型融合!那么,我要和你做朋友!!
https://mp.weixin.qq.com/s/-MbiSkgkF11gt5t9W0ExTw
模型融合方法最全总结
GBDT+LR
论文:
《Practical Lessons from Predicting Clicks on Ads at Facebook》
GBDT除了单独使用之外,也可以和其他模型Stack使用。
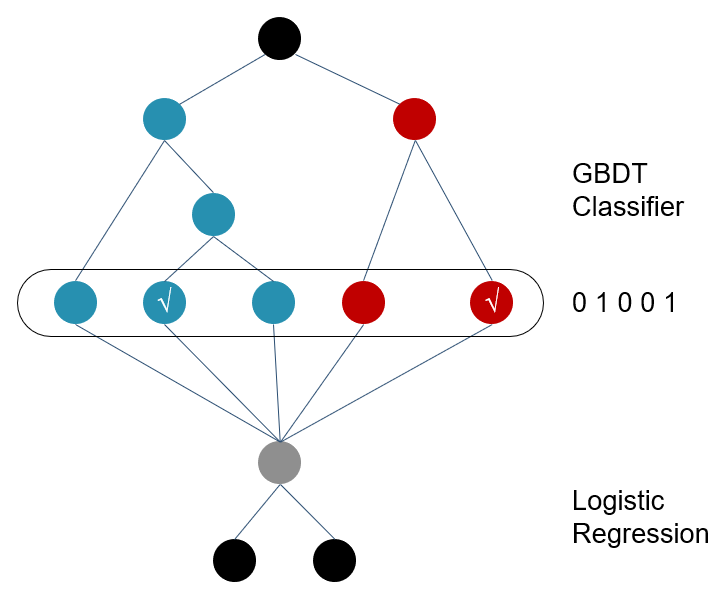
上图就是GBDT+LR的示意图。上图中,GBDT有红蓝两个子树。黑色样本经子树分类后,落在子树打勾的分支中。将分类结果进行编码,然后交给LR进行进一步的分类。
当然了,把GBDT换成其他决策树,如XGBoost,把LR换成SVM,显然也是可行的。相对于LR之类的模型,决策树在特征提取方面,还是很有优势的。
参考:
https://www.cnblogs.com/wkang/p/9657032.html
GBDT+LR算法解析及Python实现
https://blog.csdn.net/losteng/article/details/78378958
学习GBDT+LR
数据清洗
https://mp.weixin.qq.com/s/YrCC8CmP6UKuCmSdF2K_3g
数据挖掘中的数据清洗方法大全
https://mp.weixin.qq.com/s/FHdo2DTapoTryA-hOM-y_w
还在为数据清洗抓狂?这里有一个简单实用的清洗代码集
https://mp.weixin.qq.com/s/r7ngZOM9tO-_OSfvs2aDJw
数据清洗&预处理入门完整指南
https://mp.weixin.qq.com/s/r4ycLnjOl5hSPBMwKpnmsQ
如何打造高质量的NLP数据集
LSA
基本原理
Latent Semantic Analysis(隐式语义分析),也叫Latent Semantic Indexing。它是PCA算法在NLP领域的一个应用。
在TF-IDF模型中,所有词构成一个高维的语义空间,每个文档在这个空间中被映射为一个点,这种方法维数一般比较高而且每个词作为一维割裂了词与词之间的关系。
为了解决这个问题,我们要把词和文档同等对待,构造一个维数不高的语义空间,每个词和每个文档都是被映射到这个空间中的一个点。
LSA的思想就是说,我们考察的概率既包括文档的概率,也包括词的概率,以及他们的联合概率。
为了加入语义方面的信息,我们设计一个假想的隐含类包括在文档和词之间,具体思路是这样的:
1.选择一个文档的概率是\(p(d)\)
2.找到一个隐含类的概率是\(p(z\mid d)\)
3.生成一个词w的概率为\(p(w\mid z)\)
实现方法

上图中,行表示单词,列表示文档,单元格的值表示单词在文档中的权重,一般可由TF-IDF生成。
聪明的读者看到这里应该已经反应过来了,这不就是《机器学习(十四)》中提到的协同过滤的商品打分矩阵吗?
没错!LSA的实现方法的确与之类似。多数的blog讲解LSA算法原理时,由于单词-文档矩阵较小,直接采用了矩阵的SVD分解,少数给出了EM算法实现,实际上就是ALS或其变种。
参考:
http://www.cnblogs.com/kemaswill/archive/2013/04/17/3022100.html
Latent Semantic Analysis(LSA/LSI)算法简介
http://blog.csdn.net/u013802188/article/details/40903471
隐含语义索引(Latent Semantic Indexing)
http://www.shareditor.com/blogshow/?blogId=90
比TF-IDF更好的隐含语义索引模型是个什么鬼
http://shiyanjun.cn/archives/548.html
使用libsvm+tfidf实现文本分类
https://mp.weixin.qq.com/s/iZOVUYKWP-fN8BwAuVwAUw
TF-IDF不容小觑
两弹一星=
1994年10月我军举行代号“神圣94”海空军联合军事演习,美帝小鹰号航母仅派出一两架EA-6B电子战飞机,破解我军防空雷达信号后,从雷达束旁瓣注入密集信号,造成山东、江苏、上海等多地雷达显示近百架战机大举入侵我演习区域。
https://mp.weixin.qq.com/s/to4Z7Cl8pnp7m7GuzJCLcQ
电子对抗就是一场电磁波的数学竞赛,论降维打击之电子战
https://www.zhihu.com/question/442860858
为什么每次美军舰队出现在南海都会被发现?
这种物物交换的前提,是双方能各取所需,因此当一方拿出的物资不是对方所需求的,则经常要辗转腾挪数次才能完成交易。比如江苏省武进县化轻公司曾经想用电石到海南岛协作橡胶,但对方需要的是硬脂酸,不要电石。这个单位只好拿电石到处串换,先是用电石从内蒙换到生铁,再用生铁到上海换来汽车,然后又用汽车去武汉换来硬脂酸,最后才用硬脂酸从海南岛换回了橡胶。
这种现象的广泛存在,是因为中国计划经济水平远逊色于苏联。同时期的苏联虽然也是黑市猖獗,但交易的多是生活消费品和农产品,鲜有大规模交易生产物资的现象。但这种“落后”倒也并非坏事,由于中国始终保有着市场交易的行为,这使得中国能更顺利地从计划经济转向市场经济,而不至于发生像俄罗斯这样的经济灾难。
https://www.zhihu.com/question/1921304020225619753
我国计划经济时期真的一点市场都没有吗?只是分配?

您的打赏,是对我的鼓励
