Deep Object Detection » 深度目标检测(五)——YOLOv3
2018-12-01 :: 5866 WordsYOLOv2(续)
High Resolution Classifier
所有state-of-the-art的检测方法基本上都会使用ImageNet预训练过的模型(classifier)来提取特征,例如AlexNet输入图片会被resize到不足256x256,这导致分辨率不够高,给检测带来困难。所以YOLO(v1)先以分辨率224x224训练分类网络,然后需要增加分辨率到448x448,这样做不仅将网络切换为检测网络,也改变了分辨率。所以作者想能不能在预训练的时候就把分辨率提高了,训练的时候只是由分类网络切换为检测网络。
YOLOv2首先修改预训练分类网络的分辨率为448x448,在ImageNet数据集上训练10轮(10 epochs)。这个过程让网络有足够的时间调整filter去适应高分辨率的输入。然后fine tune为检测网络。mAP获得了4%的提升。
Convolutional With Anchor Boxes
借鉴SSD的经验,使用Anchor方法替代全连接+reshape。
相应的,YOLOv2对于输出向量的编码方式进行了改进,如下图所示:
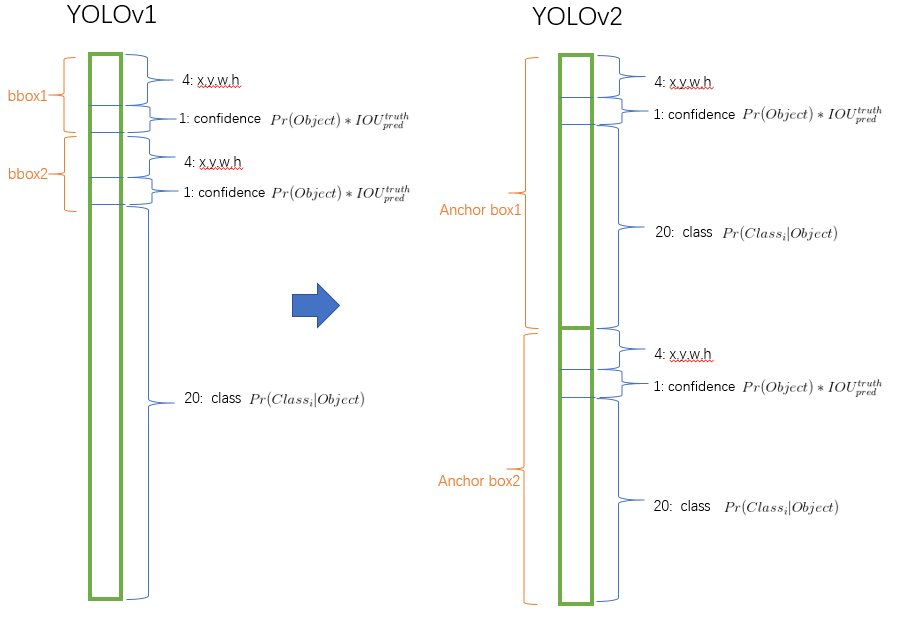
其主要思路是:将对类别的预测放到anchor box中。
同时,由于分辨率的提高,cell的数量由7x7改为13x13。这样一来就有13x13x9=1521个boxes了。(假设每个cell的Anchor Boxes的数量为9。)因此,YOLOv2比YOLO在检测小物体方面有一定的优势。
Dimension Clusters
使用anchor时,作者发现Faster-RCNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),设想能否一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就应该更容易学到准确的预测位置。
解决办法就是统计学习中的K-means聚类方法,通过对数据集中的ground true box做聚类,找到ground true box的统计规律。以聚类个数k为anchor boxs个数,以k个聚类中心box的宽高维度为anchor box的维度。
作者做了对比实验,5种boxes的Avg IOU(61.0)就和Faster R-CNN的9种Avg IOU(60.9)相当。说明K-means方法的生成的boxes更具有代表性,使得检测任务更好学习。
Direct location prediction
使用anchor boxes的另一个问题是模型不稳定,尤其是在早期迭代的时候。大部分的不稳定现象出现在预测box的(x,y)坐标时。
究其原因在于,虽然RPN会预测坐标的修正值\((\Delta x, \Delta y)\),然而却未对\(\Delta x, \Delta y\)的取值范围做限定。因此,可能会出现anchor检测很远的目标box的情况,效率比较低。
正确做法应该是每一个anchor只负责检测周围正负一个单位以内的目标box。
Fine-Grained Features
修改后的网络最终在13x13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,但如果用上细粒度特征的话可能对小尺度的物体检测有帮助。
Faser R-CNN和SSD都在不同层次的特征图上产生区域建议以获得多尺度的适应性。
YOLOv2使用了一种不同的方法,简单添加一个passthrough layer,把浅层特征图(分辨率为26x26)连接到深层特征图。
具体操作如下:
1.叠加相邻空间位置的特征到不同通道,将26x26x512的特征图叠加成13x13x2048的特征图。
2.将浅层特征图(13x13x2048)和深层特征图(13x13x1024)合并为一个(13x13x3072)tensor。
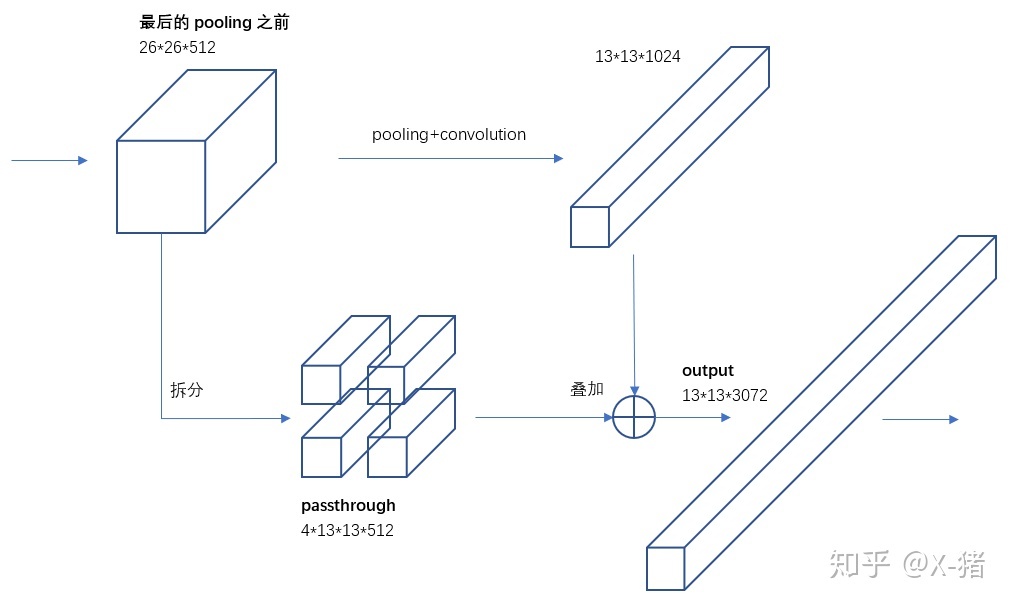
从实际的实现来看,这里passthrough layer,实际上就是tf.space_to_depth运算。
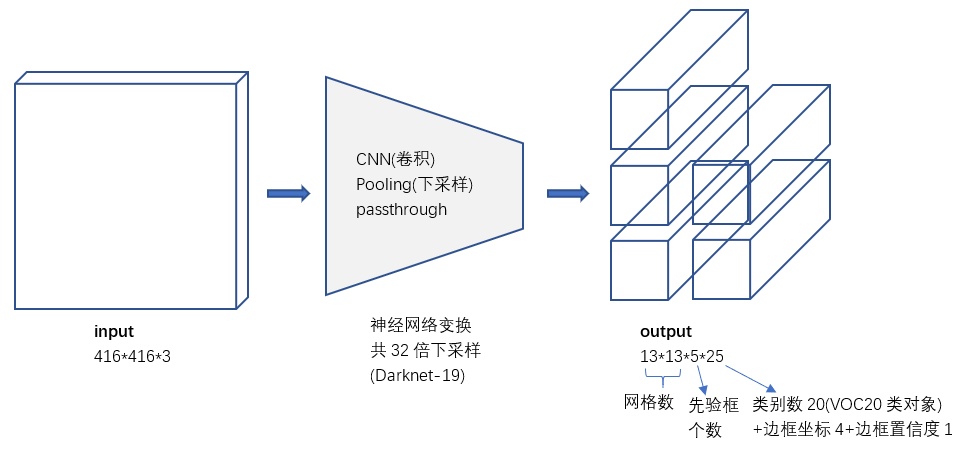
上图中每个cell的Anchor Boxes为5。
Multi-Scale Training
为了让YOLOv2对不同尺寸图片具有鲁棒性,在训练的时候就要考虑这一点。
每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320x320,最大的尺寸为608x608。调整网络到相应维度然后继续进行训练。
一般来说,神经网络各层的tensor尺寸在训练过程中是不能随意修改的,因为修改之后参数的个数会发生变化,那就不是同一个model了。然而,有些操作是例外的。比如pooling,这个操作只有规则没有参数,因此可以很方便适应不同的tensor尺寸。再比如卷积,不同尺寸的图片,实际上也可以用相同大小的kernel进行卷积操作,只要kernel的参数可以在训练过程中共享,这个训练过程就是合理的。而YOLOv2正好只有卷积和pooling两种操作。
Faster
Darknet-19
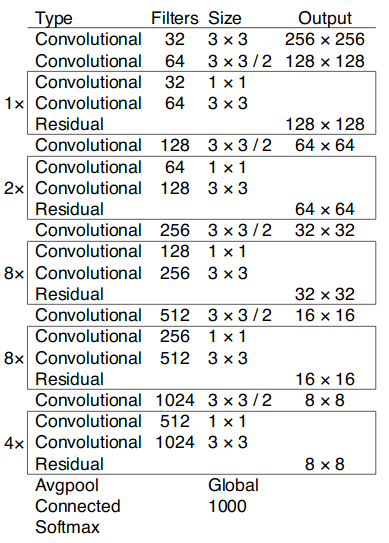
YOLOv2使用了一个新的分类网络作为特征提取部分,参考了前人的先进经验,比如类似于VGG,作者使用了较多的3x3卷积核,在每一次池化操作后把通道数翻倍。
借鉴了network in network的思想,网络使用了全局平均池化(global average pooling),把1x1的卷积核置于3x3的卷积核之间,用来压缩特征。也用了batch normalization(前面介绍过)稳定模型训练。
最终得出的基础模型就是Darknet-19,其包含19个卷积层、5个最大值池化层(maxpooling layers )。如下图:
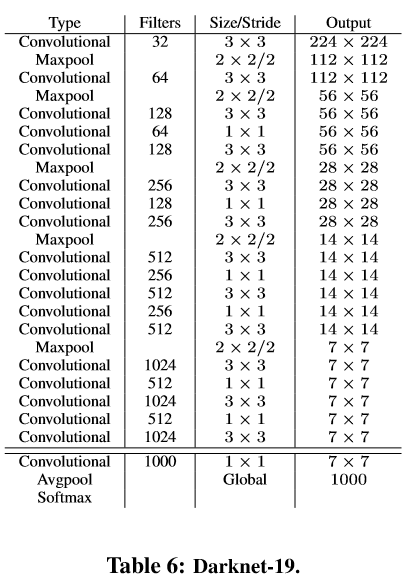
Darknet-19的运算量为55.8亿次浮点数运算。VGG-16为306.9亿次,而YOLO为85.2亿次。
Stronger
联合训练
作者提出了一种在分类数据集和检测数据集上联合训练的机制:
1.使用检测数据集的图片去学习检测相关的信息,例如bounding box坐标预测,是否包含物体以及属于各个物体的概率。
2.使用仅有类别标签的分类数据集图片去扩展可以检测的种类。
这种方法有一些难点需要解决。检测数据集只有常见物体和抽象标签(不具体),例如 “狗”,“船”。分类数据集拥有广而深的标签范围(例如ImageNet就有一百多类狗的品种,包括 “Norfolk terrier”, “Yorkshire terrier”, and “Bedlington terrier”等. )。必须按照某种一致的方式来整合两类标签。
大多数分类的方法采用softmax层,考虑所有可能的种类计算最终的概率分布。但是softmax假设类别之间互不包含,但是整合之后的数据是类别是有包含关系的,例如 “Norfolk terrier” 和 “dog”。所以整合数据集没法使用这种方式(softmax 模型),
作者最后采用一种不要求互不包含的多标签模型(multi-label model)来整合数据集。
Hierarchical classification(层次式分类)
ImageNet的标签参考WordNet(一种结构化概念及概念之间关系的语言数据库)。例如:
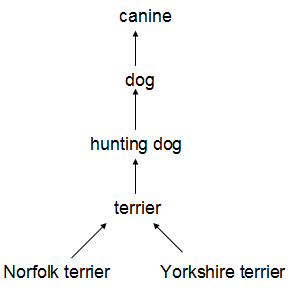
很多分类数据集采用扁平化的标签。而整合数据集则需要结构化标签。
WordNet是一个有向图结构(而非树结构),因为语言是复杂的(例如“dog”既是“canine”又是“domestic animal”),为了简化问题,作者从ImageNet的概念中构建了一个层次树结构(hierarchical tree)来代替图结构方案。这也就是作者论文中提到的WordTree。
WordTree的细节,更偏NLP一些,这里不再赘述。
参考
https://zhuanlan.zhihu.com/p/25167153
YOLO2
http://blog.csdn.net/jesse_mx/article/details/53925356
YOLOv2论文笔记
http://lanbing510.info/2017/09/04/YOLOV2.html
目标检测之YOLOv2
https://mp.weixin.qq.com/s/r2mfq0UkljKce8_dYrCNEw
YOLOv2原理与实现
https://zhuanlan.zhihu.com/p/47575929
YOLOv2/YOLO9000深入理解
YOLOv3
2018年4月,pjreddie提出了YOLOv3。
论文:
《YOLOv3: An Incremental Improvement》
代码:
https://github.com/YunYang1994/tensorflow-yolov3
TF版本
它的改进点在于:
- 骨干网络再次升级。
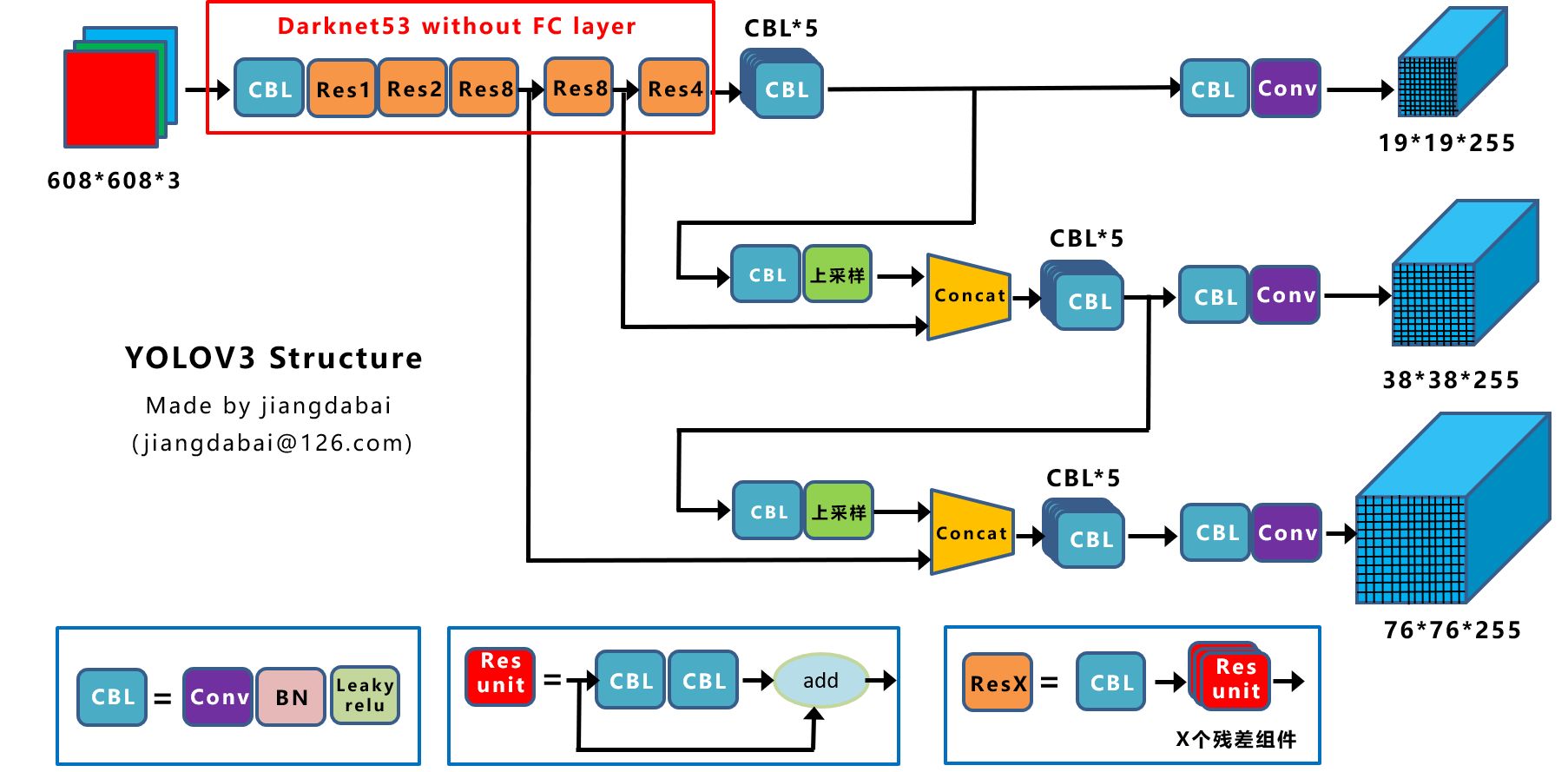
上图是YOLOv3的网络结构图。由于这个网络共有53层Conv,因此也被作者称作Darknet-53。
从结构来看,它明显借鉴了ResNet的残差结构。而3x3、1x1卷积核的使用,则显然是SqueezeNet的思路。
Yolov3的三个基本组件:
- CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
-
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
- 多尺度先验框。
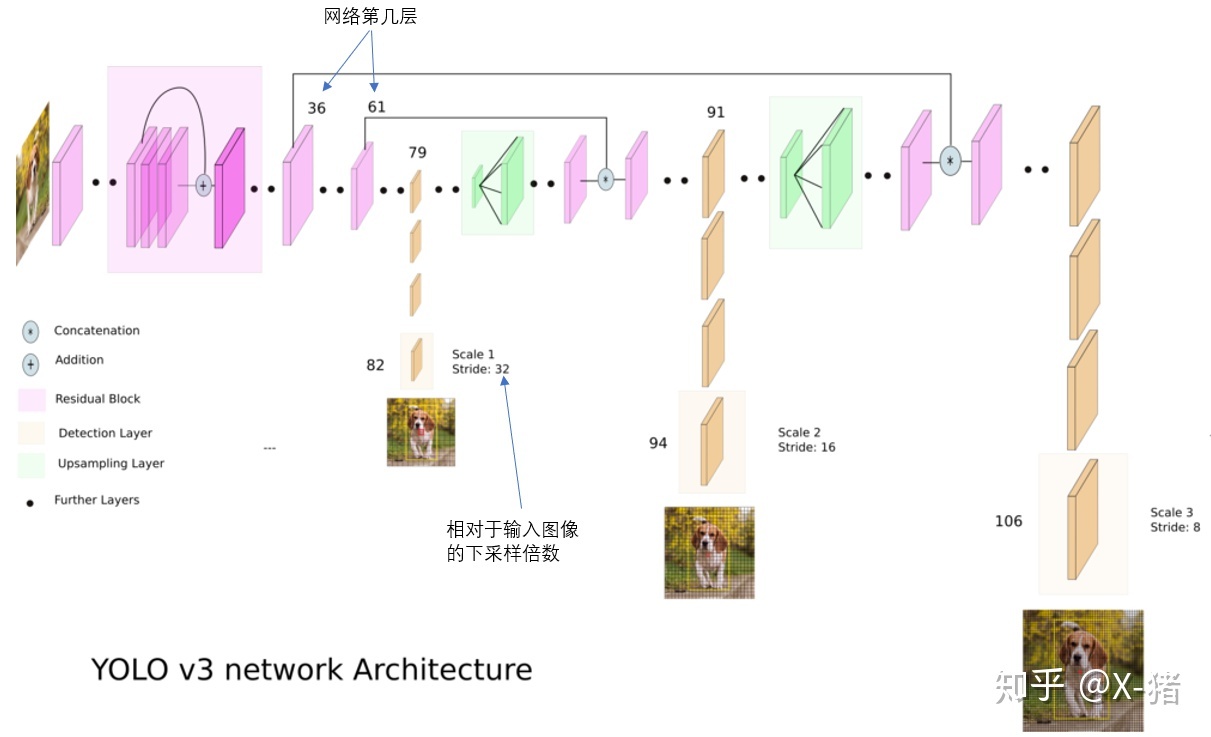
YOLOv2从两个不同尺度的conv层输出中提取bbox,而YOLOv3从3个不同尺度的conv层输出中提取bbox。多尺度特征提取在U-NET、DenseNet中,早就广泛使用了,用到这里也很自然。
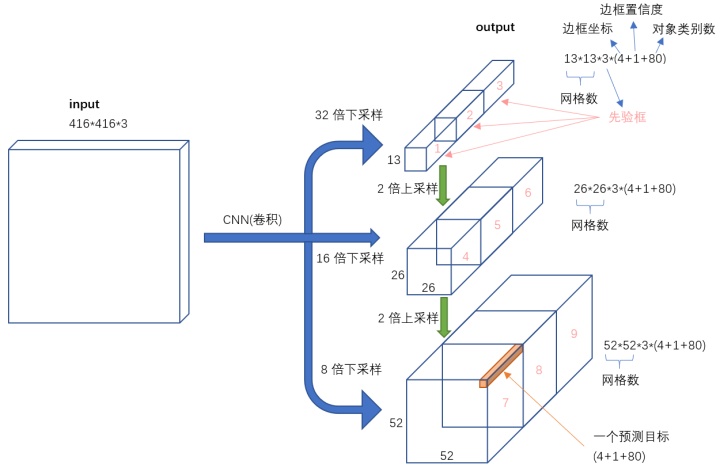
上图是YOLOv3网络输出的tensor的格式。
- 对象分类softmax改成logistic。
预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman和Person两个标签)。
实际上,就是把loss由tf.nn.softmax_cross_entropy_with_logits换成tf.nn.sigmoid_cross_entropy_with_logits。它的特点是每个类别给出一个二分类(是/否)的置信度,如果某个对象是多标签的话,则它可能有多个类别的置信度接近1。
参考:
https://zhuanlan.zhihu.com/p/34945787
YOLOv3:An Incremental Improvement全文翻译
https://mp.weixin.qq.com/s/UWuCiV6dBk9Z0XusEBS6-g
物体检测经典模型YOLO新升级,就看一眼,速度提升3倍!
https://mp.weixin.qq.com/s/BF7mj-_D303cLiD5e6oy6w
期待已久的—YOLO V3
https://mp.weixin.qq.com/s/-Ixqxx6QGJDTM4g50y6LyA
进击的YOLOv3,目标检测网络的巅峰之作
https://zhuanlan.zhihu.com/p/46691043
YOLO v1深入理解
https://zhuanlan.zhihu.com/p/47575929
YOLOv2 / YOLO9000深入理解
https://zhuanlan.zhihu.com/p/49556105
YOLO v3深入理解
https://mp.weixin.qq.com/s/0lyDv9b-mpvSFYXqyngT-w
实用教程!使用YOLOv3训练自己数据的目标检测
https://mp.weixin.qq.com/s/PkFtZ0Iqf7PBGyE5a_IJ4Q
YOLO v3的TensorFlow实现,GitHub完整源码解析
https://mp.weixin.qq.com/s/Vuuca3A7luCyCQ-jBKMIcw
YOLO v3目标检测的PyTorch实现,GitHub完整源码解析!
https://mp.weixin.qq.com/s/2aeBBjCbWdweYmNrTaWqqw
一文看尽目标检测:从YOLO v1到v3的进化之路
https://mp.weixin.qq.com/s/fDOskKqG-fsJmhT0-tdtTg
SlimYOLOv3:更窄、更快、更好的无人机目标检测算法
https://zhuanlan.zhihu.com/p/50595699
揭秘YOLOv3鲜为人知的关键细节
https://mp.weixin.qq.com/s/EElv2Tc73JKS8jpejEGB1w
YOLO v3实战之钢筋数量AI识别(一)
https://mp.weixin.qq.com/s/HEBO9uZMD2CZW_Y-8eBK1A
YOLOv1/v2/v3简述
https://mp.weixin.qq.com/s/5IfT9cWVbZq4cwHPLes5vA
你对YOLOV3损失函数真的理解正确了吗?
https://mp.weixin.qq.com/s/biPLPaunfkQtpywaHbBfLg
YOLOV3损失函数再思考
https://mp.weixin.qq.com/s/Cws-3Cni-_v3AED918eB4A
高斯YoloV3目标检测

您的打赏,是对我的鼓励
