Deep Object Detection » 深度目标检测(二)——RCNN, SPPNet
2018-11-16 :: 5297 WordsRCNN
Selective Search(续)
Selective Search的主要思想:
Step 1:使用一种过分割手段,将图像分割成小区域 (1k~2k个)。
这里的步骤实际上并不简单,可参考论文:
《Efficient Graph-Based Image Segmentation》
中文版:
http://blog.csdn.net/surgewong/article/details/39008861
Step 2:查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置。
Step 3:输出所有曾经存在过的区域,所谓候选区域。
其中合并规则如下:优先合并以下四种区域:
1.颜色(颜色直方图)相近的。
2.纹理(梯度直方图)相近的。
3.合并后总面积小的:保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域(例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
4.合并后,总面积在其bounding box中所占比例大的:保证合并后形状规则。
Selective Search的效果类似下图:


上图中的那些方框,就是bounding box。
一般使用IOU(Intersection over Union,交并比)指标,来衡量两个bounding box的重叠度:
\[IOU(A,B)=\frac{A \cap B}{A \cup B}\]参考:
https://mp.weixin.qq.com/s/dlP3bZoSdm3w3YSDD8DPVg
Selective Search算法与演示
https://mp.weixin.qq.com/s/DygWoZSEvbW_BBFVBOJNbg
新手也能彻底搞懂的目标检测Anchor是什么?怎么科学设置?
https://zhuanlan.zhihu.com/p/150332784
目标检测Anchor的What/Where/When/Why/How
非极大值抑制(NMS)
RCNN会从一张图片中找出n个可能是物体的矩形框,然后为每个矩形框为做类别分类概率(如上图所示)。我们需要判别哪些矩形框是没用的。
Non-Maximum Suppression顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。
下面举例说明NMS的做法:
假设有6个矩形框,根据分类器的类别和分类概率做排序,假设从小到大属于车辆的概率分别为A、B、C、D、E、F。
Step 1:从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值。(确定领域)
Step 2:假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。(抑制领域内的非极大值)
Step 3:从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。(确定下一个领域,并抑制该领域内的非极大值)
原始的NMS又被称为greedy-NMS,由于它简单的将重叠的候选框去除掉,不利于重叠物体的目标检测,所以后来学界又相继提出了Soft-NMS和Softer-NMS。
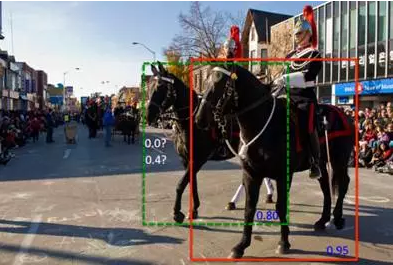
例如上图中的两匹马重叠度很高,使用greedy-NMS的话,就会有一匹马检测不到。
参考:
https://mp.weixin.qq.com/s/NPoB4_kpTIYAO34qZFRbQA
对象检测网络中的NMS算法详解
http://mp.weixin.qq.com/s/Cg9tHG1YgDCdI3NPYl5-vQ
如何用Soft-NMS实现目标检测并提升准确率
https://mp.weixin.qq.com/s/Pd1zA-xZS_xEALfMJ3aHNw
丧尸目标检测:和你分享Python非极大值抑制方法运行得飞快的秘诀
https://mp.weixin.qq.com/s/SewmtFCVpsthQ4dWUGmEsA
Softer-NMS:CMU&旷视最新论文提出定位更加精确的目标检测算法
NMS的快速算法
RCNN系列的NMS的一个经典取值是:从N=6000个排好序的矩形框中,选出M=300个独立的目标框。
如果采用上面列出的标准做法,实际上是很低效的。它的算法复杂度是\(N^2/2\)。
这时可以采用如下方法:
1.将第一个矩形框加入目标框集合。(这是很显然的,分最高的框必然在目标框集合中。)
2.开始顺序遍历矩形框,每个矩形框只与目标框集合中的元素进行对比。符合条件的,加入目标框集合。
3.目标框集合中的元素达到M,算法结束。
这个的算法复杂度只有\(N\times M\)。当\(M \ll N\)时,是非常高效的。究其原因在于:N个矩形框的后半部分,由于都是低分值的矩形框,几乎不可能进入目标框集合,也就没必要进行比较。
ground truth
在有监督学习中,数据是有标注的,以(x,t)的形式出现,其中x是输入数据,t是标注。正确的t标注是ground truth,错误的标记则不是。(也有人将所有标注数据都叫做ground truth)
在目标检测任务中,ground truth主要包括box和category两类信息。
正负样本问题
一张照片我们得到了2000个候选框。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。因此在CNN阶段我们需要用IOU为2000个bounding box打标签。
如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别(正样本),否则我们就把它当做背景类别(负样本)。
使用SVM的问题
CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,在训练的时候,最后一层softmax就是分类层。那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练SVM分类器?
这个是因为SVM训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用SVM精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而SVM训练的时候,因为SVM适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练SVM。
CNN base
目标检测任务不是一个独立的任务,而是在目标分类基础之上的进一步衍生。因此,无论何种目标检测框架都需要一个目标分类的CNN作为base(也被称为backbone),仅对其最上层的FC层做一定的修改。
VGG、AlexNet都是常见的CNN base。
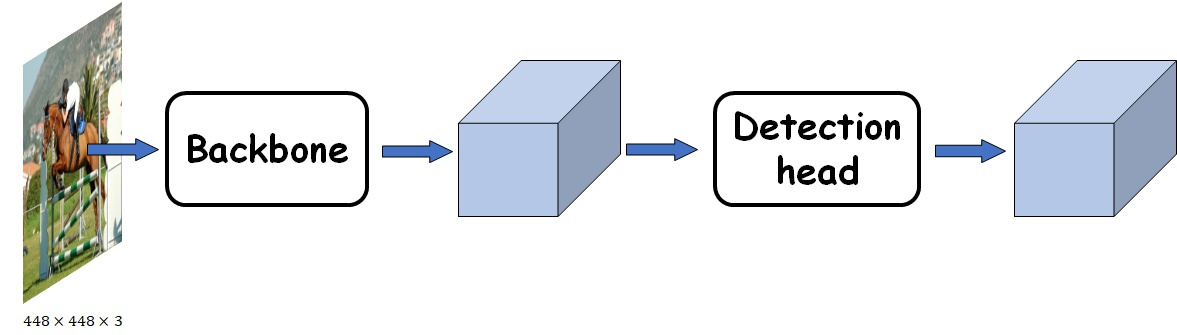
每一个不同的任务所对应的网络,被称为head,比如目标检测就是Detection Head。
随着技术的发展,除了backbone和head这两部分,更多的新奇的技术和模块被提了出来,最著名的,莫过于FPN了。除了FPN这种新颖的结构,还有诸如ASFF、RFB、SPP等好用的模块,都可以插在backbone和detection head之间。由于其插入的位置的微妙,故而将其称之为“neck”。
因此,现在一个完整的目标检测网络主要由三部分构成:
detector=backbone+neck+head
或者还可以把流程更细分一下:
https://zhuanlan.zhihu.com/p/93451942
Backbone与Detection head
评价标准
目标检测一般采用mAP(mean Average Precision)作为评价标准。AP的含义参见《机器学习(二十二)》。
对于多分类任务来说,每个分类都有一个AP,将这些AP平均(或加权平均)之后,就得到了mAP。
目前,目标检测领域的mAP,一般以PASCAL VOC 2012的标准为准。文档参见:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/devkit_doc.pdf
对于目标检测任务来说,除了分类之外,还有box准确度的问题。一般IOU大于0.5的被认为是正样本,反之则是负样本。
PASCAL VOC还对P-R曲线的采样做出规定。2012之前的标准中,P-R曲线只需要对recall值进行10等分采样即可。而2012标准规定,对每个recall值都要进行采样。
参考:
http://blog.sina.com.cn/s/blog_9db078090102whzw.html
多标签图像分类任务的评价方法-mAP
https://www.zhihu.com/question/41540197
mean average precision(MAP)在计算机视觉中是如何计算和应用的?
https://mp.weixin.qq.com/s/XTuemvxIR4PGpqJprUYuFw
什么是MAP?理解目标检测模型中的性能评估
https://mp.weixin.qq.com/s/e4Bi4LRY8SCZcXTq4Zd3OQ
最完整的检测模型评估指标mAP计算指南
https://mp.weixin.qq.com/s/5kzWL6rCKZGX1xfQ71-gfQ
详解对象检测网络性能评价指标mAP计算
https://zhuanlan.zhihu.com/p/55575423
浅析经典目标检测评价指标–mmAP(一)
https://zhuanlan.zhihu.com/p/56899189
浅析经典目标检测评价指标–mmAP(二)
总结
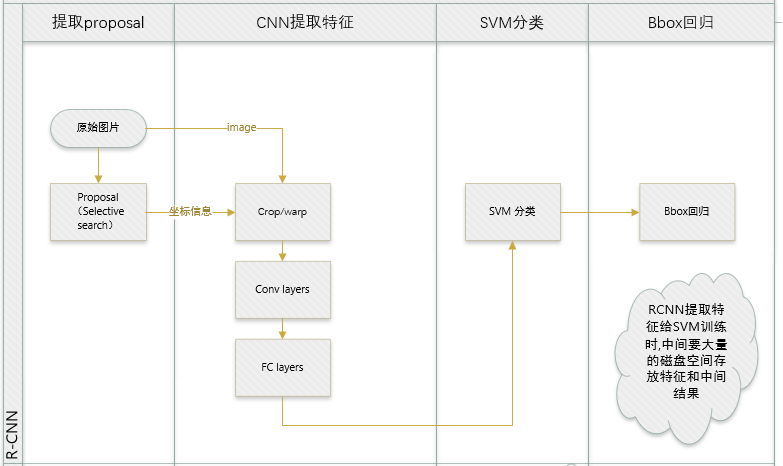
参考
https://zhuanlan.zhihu.com/p/23006190
RCNN-将CNN引入目标检测的开山之作
http://www.cnblogs.com/edwardbi/p/5647522.html
Tensorflow tflearn编写RCNN
http://blog.csdn.net/u011534057/article/category/6178027
RCNN系列blog
http://blog.csdn.net/shenxiaolu1984/article/details/51066975
RCNN算法详解
http://mp.weixin.qq.com/s/_U6EJBP_qmx68ih00IhGjQ
Object Detection R-CNN
SPPNet
SPPNet是何恺明2014年的作品。
论文:
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
在RCNN算法中,一张图片会有1~2k个候选框,每一个都要单独输入CNN做卷积等操作很费时。而且这些候选框可能很多都是重合的,重复的CNN操作从信息论的角度,也是相当冗余的。
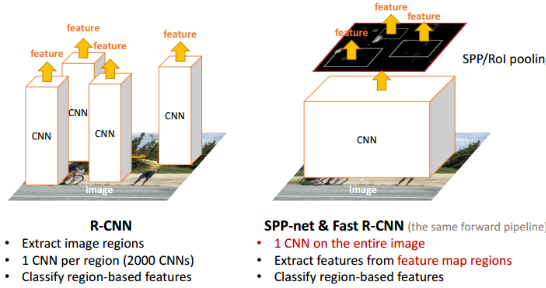
SPPNet的核心思想如上图所示:在feature map上提取ROI特征,这样就只需要在整幅图像上做一次卷积。
这个想法说起来简单,但落到实地,还有如下问题需要解决:
Problem 1:原始图像的ROI如何映射到特征图(一系列卷积层的最后输出)。
这里的计算比较复杂,要点在于:选择原始图像ROI的左上角和右下角,将之映射到feature map上的两个对应点,从而得到feature map上的ROI。
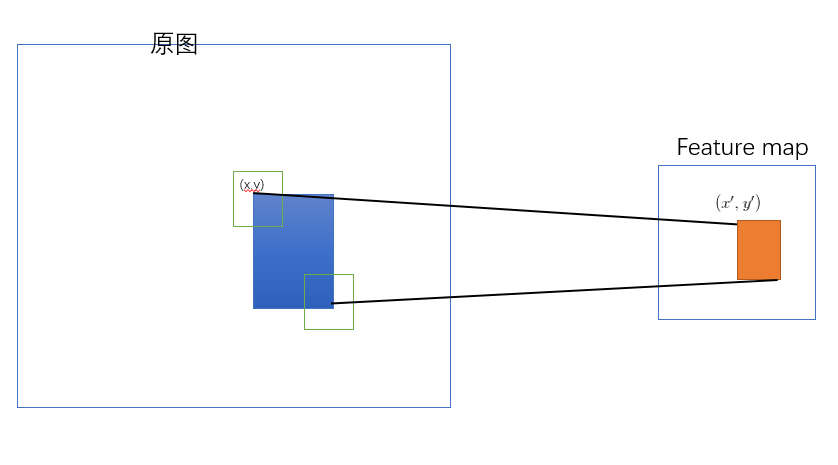
参见:
https://zhuanlan.zhihu.com/p/24780433
原始图片中的ROI如何映射到到feature map?
http://www.cnblogs.com/objectDetect/p/5947169.html
卷积神经网络物体检测之感受野大小计算

您的打赏,是对我的鼓励
