Deep Object Detection » 深度目标检测(一)——概述
2018-11-15 :: 5633 Words概述
Object Detection是计算机视觉的一个重要的分支。类似的分支还有目标分割、目标识别和目标跟踪。
以下摘录自Sensetime CTO曹旭东的解读:
传统方法使用滑动窗口的框架,把一张图分解成几百万个不同位置不同尺度的子窗口,针对每一个窗口使用分类器判断是否包含目标物体。传统方法针对不同的类别的物体,一般会设计不同的特征和分类算法,比如人脸检测的经典算法是Harr特征+Adaboosting分类器;行人检测的经典算法是HOG(histogram of gradients)+Support Vector Machine;一般性物体的检测的话是HOG特征+DPM(deformable part model)的算法。
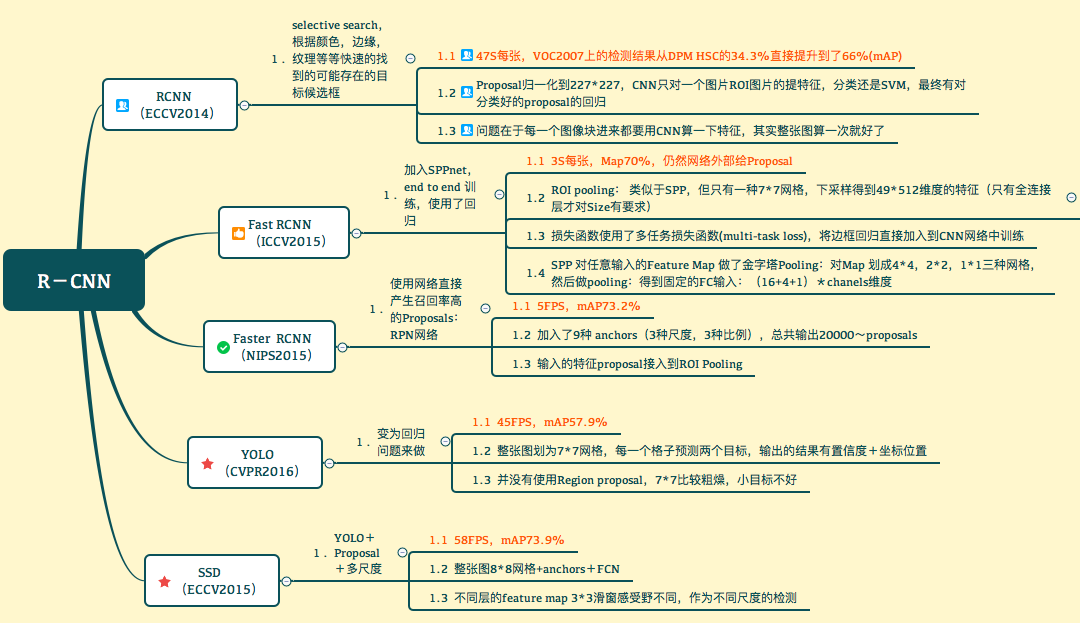
基于深度学习的物体检测的经典算法是RCNN系列:RCNN,fast RCNN(Ross Girshick),faster RCNN(少卿、凯明、孙剑、Ross)。这三个工作的核心思想是分别是:使用更好的CNN模型判断候选区域的类别;复用预计算的sharing feature map加快模型训练和物体检测的速度;进一步使用sharing feature map大幅提高计算候选区域的速度。其实基于深度学习的物体检测也可以看成对海量滑动窗口分类,只是用全卷积的方式。
RCNN系列算法还是将物体检测分为两个步骤。现在还有一些工作是端到端(end-to-end)的物体检测,比如说YOLO(You Only Look Once: Unified, Real-Time Object Detection)和SSD(SSD: Single Shot MultiBox Detector)这样的算法。这两个算法号称和faster RCNN精度相似但速度更快。物体检测正负样本极端非均衡,two-stage cascade可以更好的应对非均衡。端到端学习是否可以超越faster RCNN还需要更多研究实验。
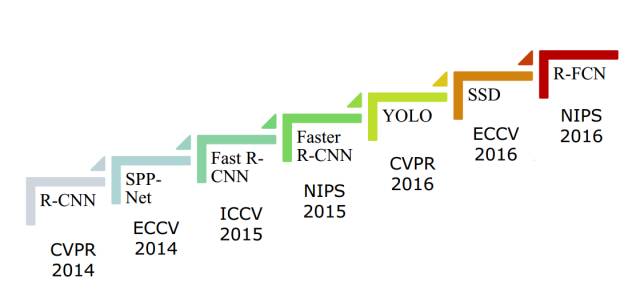
进化史
DPM(2007)->RCNN(2014)->Fast RCNN->Faster RCNN
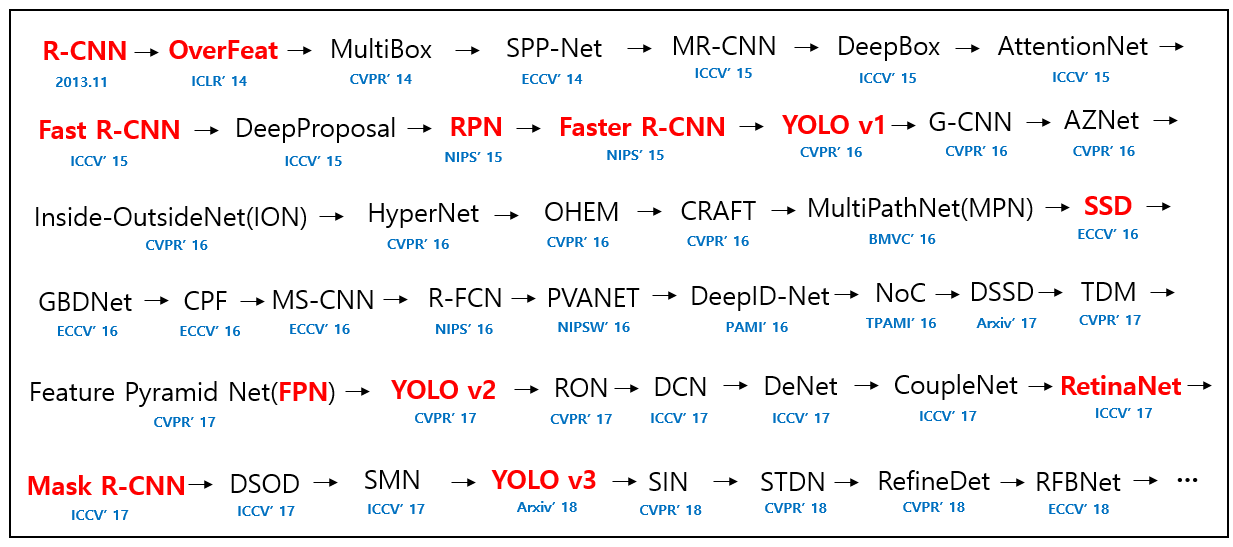
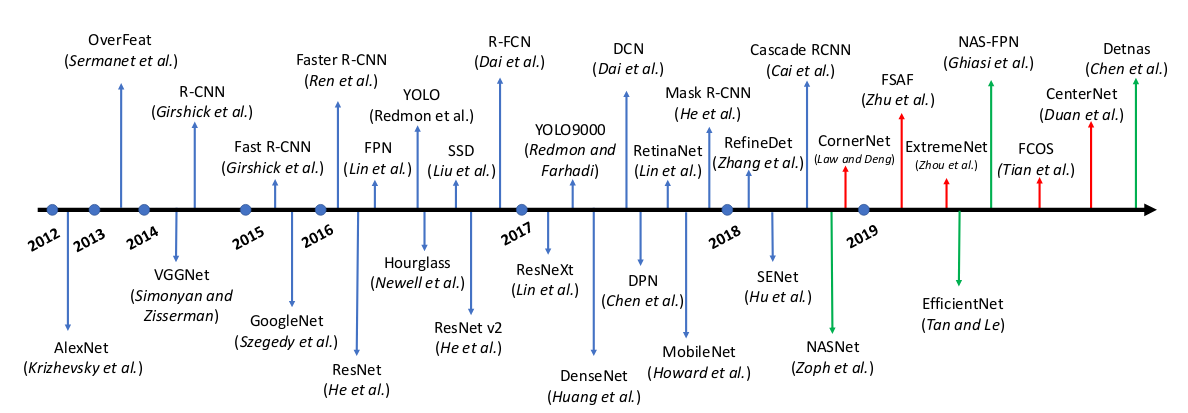
https://github.com/hoya012/deep_learning_object_detection
这个网页提供了相关的论文/模型的列表。
参考:
http://blog.csdn.net/ttransposition/article/details/12966521
DPM(Deformable Parts Model)–原理
https://mp.weixin.qq.com/s/BFL2PhAojZ5zHstgTrhlrw
悉尼大学欧阳万里等人30页最新目标检测综述
https://mp.weixin.qq.com/s/UoIhAcMRgMJ8rlA29_Nacg
深度学习目标检测近年进展
https://zhuanlan.zhihu.com/p/27546796
视觉目标检测和识别之过去,现在及可能
CV实践的难点
从理论上说,无论是传统CV,还是新近崛起的DL CV,其本质都是通过比对目标图片和训练图片的相似度,从而得到识别的结果。
CV的输入一般是由像素组成的矩阵。相比其他领域的数据挖掘而言,CV的实践难点主要包括:
1.视角的改变。照相机的移动会导致像素矩阵发生平移、旋转等变换。
2.光照影响。同一物体在不同光照条件下的影像有所不同。
3.形变。典型的例子是动物的运动,会导致外观的改变。
4.遮挡。待识别物体通常不是完全可见的。
5.背景。雪地、沙滩等不同场景,会影响物体的识别。
6.同类差异。比如各种猫都是猫,但它们的外观有细微的差异。

参考
https://github.com/amusi/awesome-object-detection
目标检测最全论文集锦
https://www.zhihu.com/question/34223049
从近两年的CVPR会议来看,目标检测的研究方向是怎么样的?
https://mp.weixin.qq.com/s/R2IIuGrPG5H2nQHw1kdaBQ
基于深度学习的目标检测算法综述:常见问题及解决方案
https://zhuanlan.zhihu.com/p/21533724
对话CVPR2016:目标检测新进展
https://zhuanlan.zhihu.com/p/36088972
基于深度学习的目标检测算法综述
https://mp.weixin.qq.com/s/r9tXvKIN-eqKW_65yFyOew
谷歌开源TensorFlow Object Detection API
https://mp.weixin.qq.com/s/_cOuhToH8KvZldNfraumSQ
什么促使了候选目标的有效检测?
https://mp.weixin.qq.com/s/c4eh4y8CNRAEllBbnP2Zhg
对象定位和检测
https://mp.weixin.qq.com/s/LAy1LKGj5HOh_e9jPgvfQw
视觉目标检测和识别之过去,现在及可能
https://mp.weixin.qq.com/s/ZHRP5xnQxex7lQJsCxwblA
深度学习目标检测的主要问题和挑战!
https://mp.weixin.qq.com/s/XbgmLmlt5X4TX5CP59gyoA
目标检测算法精彩集锦
https://mp.weixin.qq.com/s/BgTc1SE2IzNH27OC2P2CFg
CVPR-I
https://mp.weixin.qq.com/s/qMdnp9ZdlYIja2vNEKuRNQ
CVPR—II
https://mp.weixin.qq.com/s/tc1PsIoF1RN1sx_IFPmtWQ
CVPR—III
https://mp.weixin.qq.com/s/bpCn2nREHzazJYq6B9vMHg
目标识别算法的进展
https://mp.weixin.qq.com/s/YzxaS4KQmpbUSnyOwccn4A
基于深度学习的目标检测技术进展与展望
https://mp.weixin.qq.com/s/JPCQqyzR8xIUyAdk_RI5dA
RCNN, Fast-RCNN, Faster-RCNN那些你必须知道的事!
https://www.zhihu.com/question/35887527
如何评价rcnn、fast-rcnn和faster-rcnn这一系列方法?
http://blog.csdn.net/messiran10/article/details/49132053
Caffe matlab之基于Alex network的特征提取
https://mp.weixin.qq.com/s/YovhKYeGGLqSxxSqMNsbKg
基于深度学习的目标检测学习总结
https://mp.weixin.qq.com/s/nGSaQXm8AczYodtmHD1qNA
深度学习目标检测模型全面综述:Faster R-CNN、R-FCN和SSD
https://mp.weixin.qq.com/s/c2oMJfE95I1ciEtvdTlb4A
完全脱离预训练模型的目标检测方法
https://mp.weixin.qq.com/s/NV2hWofOCractLt45-wI1A
山世光:基于深度学习的目标检测技术进展与展望
https://mp.weixin.qq.com/s/zJ3EN175_9num2OknVvnyA
邬书哲:物体检测算法的革新与传承
https://mp.weixin.qq.com/s/6rSeJOqbKyrDj3FpS8J5eg
黄李超讲物体检测
https://mp.weixin.qq.com/s/JjsAnB_OxKS1Af9XAtw5sA
一文带你读懂深度学习框架下的目标检测
https://mp.weixin.qq.com/s/66yXsRIeZdHfoZkJkci24w
地平线黄李超开讲:深度学习和物体检测!
http://blog.csdn.net/zhang11wu4/article/details/53967688
目标检测最新方法介绍
https://mp.weixin.qq.com/s/ZrZtGBxVOZmexDMw_S_Orw
TensorFlow深度学习目标检测模型及源码架构解析
https://mp.weixin.qq.com/s/A9F3UsITUaNvR69roHa0mg
结合单阶段和两阶段目标检测的优势:基于单次精化神经网络的目标检测方法
https://mp.weixin.qq.com/s/xNIPdmIJiqDg_ruwHPLEDg
深度学习目标检测从入门到精通:第一篇
http://mp.weixin.qq.com/s/kDoogc5yIeX6D4_YWC5YQA
后RCNN时代的物体检测及实例分割进展
https://mp.weixin.qq.com/s/rUMAaIJ14eEXbRmssnUK4w
基于区域的目标检测——细粒度
https://mp.weixin.qq.com/s/Oy7YAp1NoVICQZqXRz0uVg
基于深度学习的目标检测综述(一)
https://mp.weixin.qq.com/s/5zE78EU_NdV5ZeW5t1yV7A
从RCNN到SSD,这应该是最全的一份目标检测算法盘点
https://mp.weixin.qq.com/s/a1GFDzcR98b7pyJR1Gn-TA
深度学习之目标检测网络学习总结(from RCNN to YOLO V3)
https://mp.weixin.qq.com/s/_kzPi1QgwqvT4glRI-FCzg
深度学习目标检测指南:如何过滤不感兴趣的分类及添加新分类?
RCNN
《深度学习(九)》中提到的AlexNet、VGG、GoogleNet主要用于图片分类。而这里介绍的RCNN(Regions with CNN)主要用于目标检测。
车牌识别的另一种思路
在介绍RCNN之前,我首先介绍一下2013年的一个车牌识别项目的解决思路。
车牌识别差不多是深度学习应用到CV领域之前,CV领域少数几个达到实用价值的应用之一。国内在2010~2015年前后,有许多公司都做过类似的项目。其产品更是随处可见,很多停车场已经利用该技术,自动识别车辆信息。
车牌识别的难度不高——无论是目标字符集,还是目标字体,都很有限。但也有它的技术难点:
1.计算资源有限。通常就是PC,甚至嵌入式设备,不可能用大规模集群来计算。
2.有实时性的要求,通常处理时间不超过3s。
因此,如何快速的在图片中找到车牌所在区域,就成为了关键问题。
常规的做法,通常是根据颜色、形状找到车牌所在区域,但鲁棒性不佳。后来,同事L提出了改进方法:
Step 1:在整个图片中,基于haar算子,寻找疑似数字的区域。
Step 2:将数字聚集的区域设定为疑似车牌所在区域。
Step 3:投入更大运算量,以识别车牌上的文字。(这一步是常规做法。)
RCNN的基本原理
RCNN是Ross Girshick于2014年提出的深度模型。
Ross Girshick(网名:rbg),芝加哥大学博士(2012),Facebook研究员。他和何恺明被誉为CV界深度学习的双子新星。
个人主页:
http://www.rossgirshick.info/
论文:
《Rich feature hierarchies for accurate object detection and semantic segmentation》
代码:
https://github.com/rbgirshick/rcnn
RCNN相对传统方法的改进:
速度:经典的目标检测算法使用滑动窗法依次判断所有可能的区域。RCNN则(采用Selective Search方法)预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上(采用CNN)提取特征,进行判断。
训练集:经典的目标检测算法在区域中提取人工设定的特征。RCNN则采用深度网络进行特征提取。
使用两个数据库:
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置,一万图像,20类。
RCNN使用识别库进行预训练得到CNN(有监督预训练),而后用检测库调优参数,最后在检测库上评测。
这实际上就是《深度学习(十五)》中提到的fine-tuning的思想。
RCNN算法的基本流程
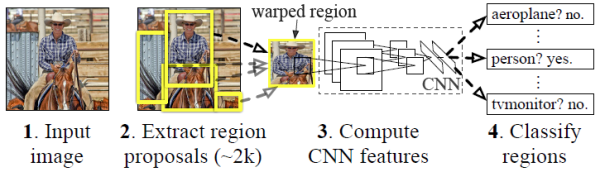
RCNN算法分为4个步骤:
Step 1:候选区域生成。一张图像生成1K~2K个候选区域(采用Selective Search方法)。
Step 2:特征提取。对每个候选区域,使用深度卷积网络提取特征(CNN)。
Step 3:类别判断。特征送入每一类的SVM分类器,判别是否属于该类。
Step 4:位置精修。使用回归器精细修正候选框位置。
Selective Search
论文:
《Selective Search for Object Recognition》
中文版:
http://blog.csdn.net/surgewong/article/details/39316931
http://blog.csdn.net/charwing/article/details/27180421

您的打赏,是对我的鼓励
