Chip » 算力 vs 带宽, NVLink
2023-11-09 :: 5414 Words算力 vs 带宽
在过去十年的竞争中,核心竞争指标是算力,现在变成了内存带宽和容量。
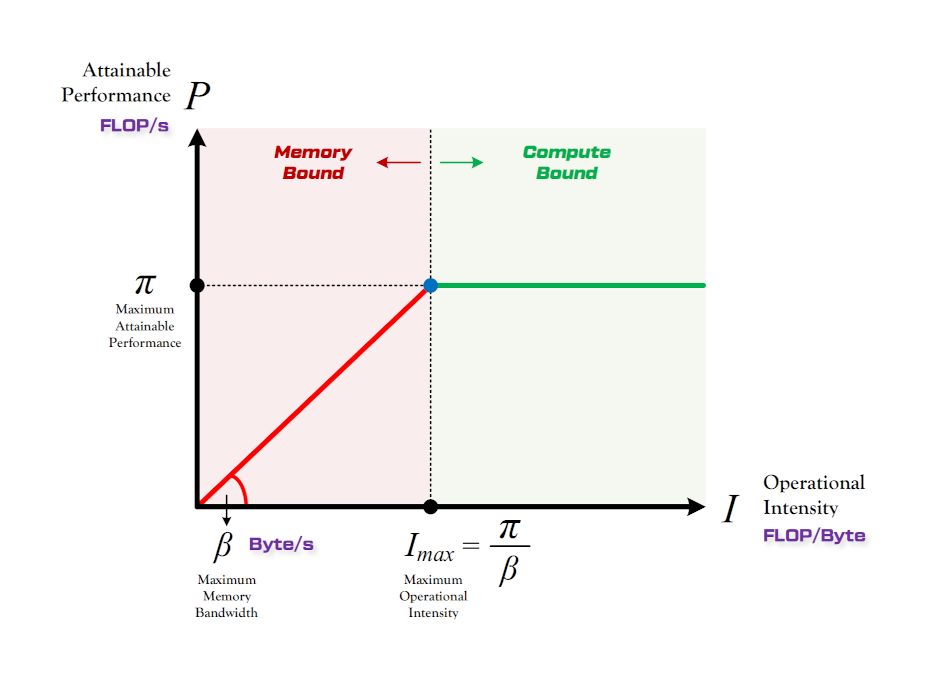
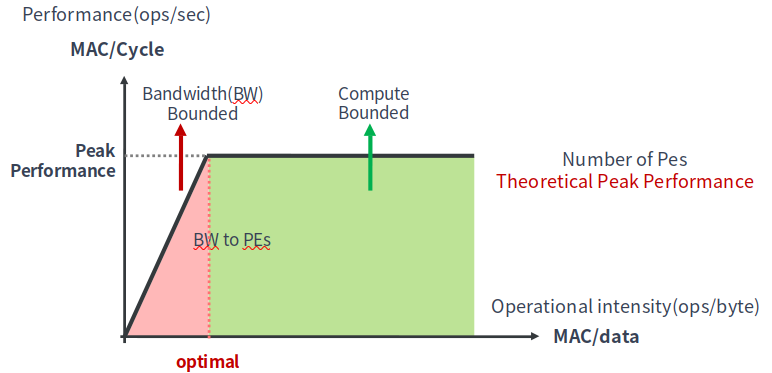
对于算力 vs 带宽的理论分析,一般使用如上图所示的Roofline Model。Roofline本意是“车顶线”。
https://zhuanlan.zhihu.com/p/34204282
Roofline Model与深度学习模型的性能分析
https://mp.weixin.qq.com/s/y9dVg9YtfWxu6NcW-fxi6Q
内存带宽与计算能力,谁才是决定深度学习执行性能的关键?
http://llm-viewer.com/
一个分析LLM Model的Roofline的可视化工具
一般来说,LLM的Prefill阶段是算力瓶颈,而decode阶段是带宽瓶颈。
反过来说,如果一个硬件平台在Prefill阶段,还是带宽瓶颈的话,那就带宽设计的过于小了。
NVLink
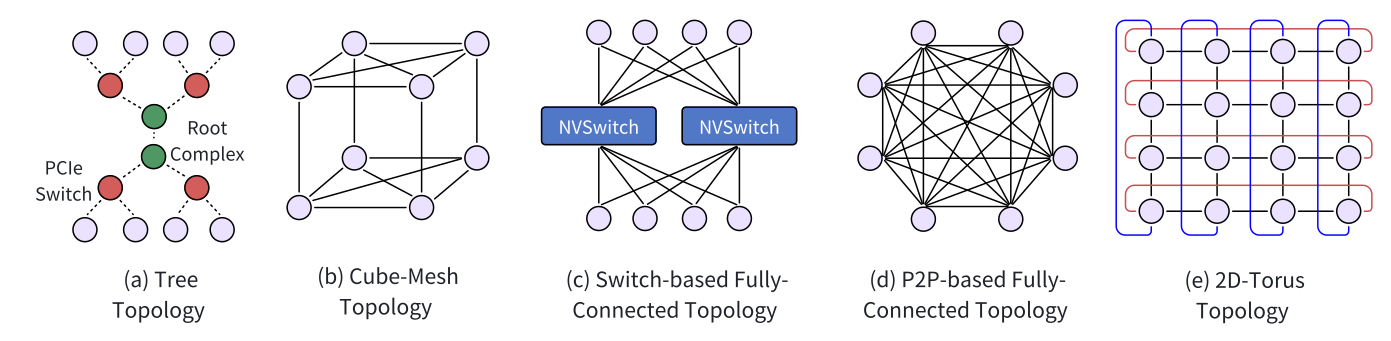
多核拓扑
拓扑关键指标:
-
网络直径(Network Diameter):指网络中任意两个节点间的最短路径长度,刻画了最坏情况下的通信延迟。Full Mesh拓扑中任意两个节点直接连接,因此网络直径为1。在Spine-leaf拓扑中,任意两个节点间的通信最多只需经过三跳(Leaf-Spine-Leaf),因此网络直径为3。
-
二分带宽(Bisection Bandwidth):指当网络被切成两半时,连接这两半部分的总通信能力。它反映了网络在最坏通信场景下的最大数据传输能力。在 Full Mesh 拓扑中,一半网络有\(\dfrac{N}{2}\)个节点,每个节点有\(\dfrac{N}{2}\)条链路连接到另一半网络,因此Full Mesh拓扑的二分带宽为\(\dfrac{N}{2} \times \dfrac{N}{2} \times B = \dfrac{N^2}{4} B\)。在Fat-Tree拓扑下,一半网络有\(\dfrac{N}{2}\)个节点,每个节点都能与另一半网络全速率通信,因此Fat-Tree拓扑的二分带宽为\(\dfrac{N}{2} B\)。
-
径向扩展度(Radix Scalability):指在给定交换芯片radix条件下的最大无阻塞集群规模\(N_{max}\) 。它衡量了在给定交换芯片端口数(\(R_{switch}\))和终端设备接口数(\(R_{dev}\))的条件下,一个拓扑理论上能构建的最大无阻塞集群规模。Full Mesh拓扑下,互联规模\(N_{max} = R_{dev} + 1\),Fat-Tree拓扑下,\(N_{max} = R_{switch}^3 / 4 R_{dev}\)。
-
平均最短路径长度(ASPL):反映网络延迟的整体水平。
Crossbar(XBAR)
各种拓扑结构:ring、torus、fat-tree、dragonfly。
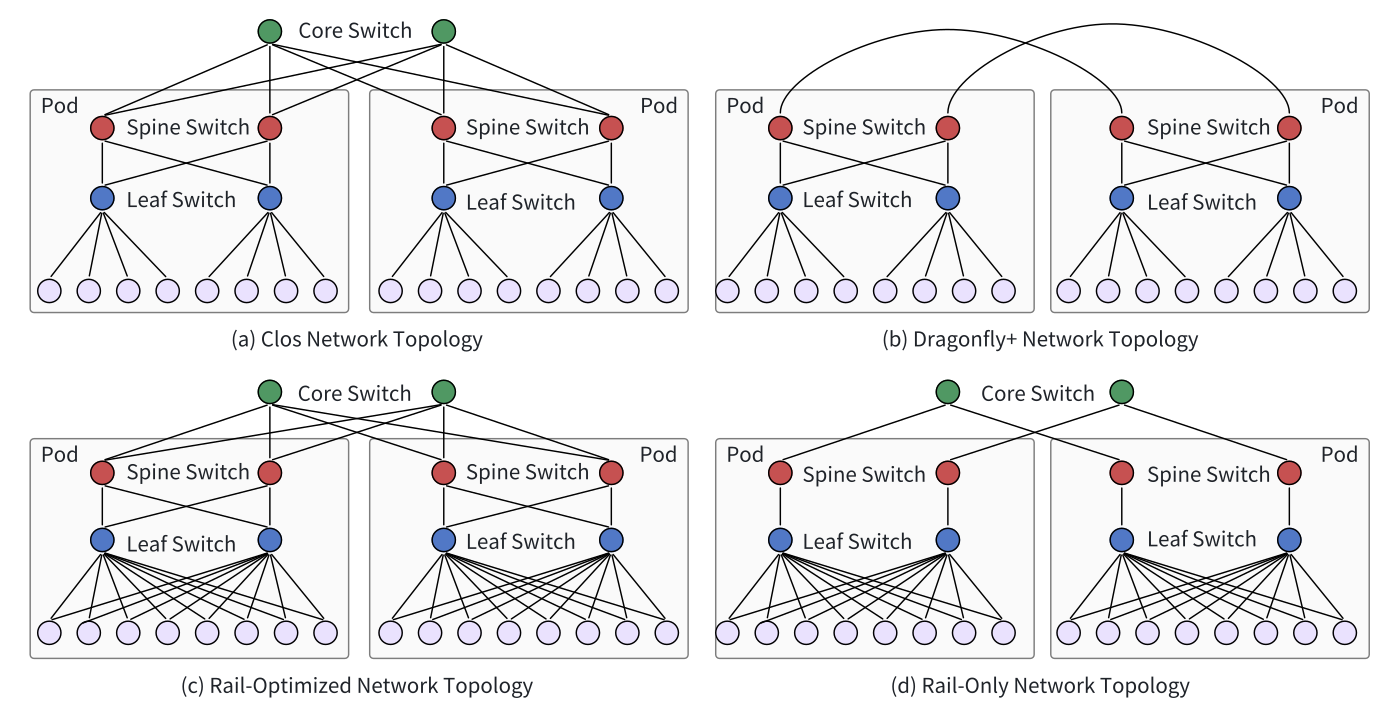
CLOS Networking:

Charles Clos曾经是贝尔实验室的研究员。他在1953年发表了一篇名为 “A Study of Non-blocking Switching Networks” 的文章。文章里介绍了一种用多级设备来实现无阻塞电话交换的方法,这是CLOS网络的起源。
将CLOS Networking对折一下,就得到了Spine+Leaf结构:

Fat-Tree(胖树)架构是另一种特殊的CLOS网络。这种网络拓扑由Charles Leiserson在1985年提出。
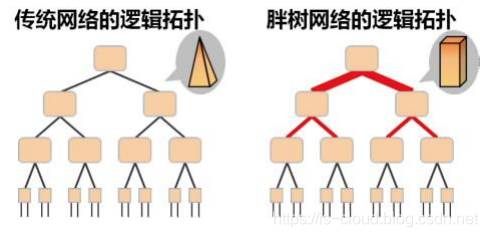
在向上连接到更高层级时“变粗”(使用更多的交换机),每一层之间的总带宽保持不变,从而避免瓶颈问题。
高层级无需使用更高成本的高性能交换机,使用更多数量的低端交换机,成本更低。
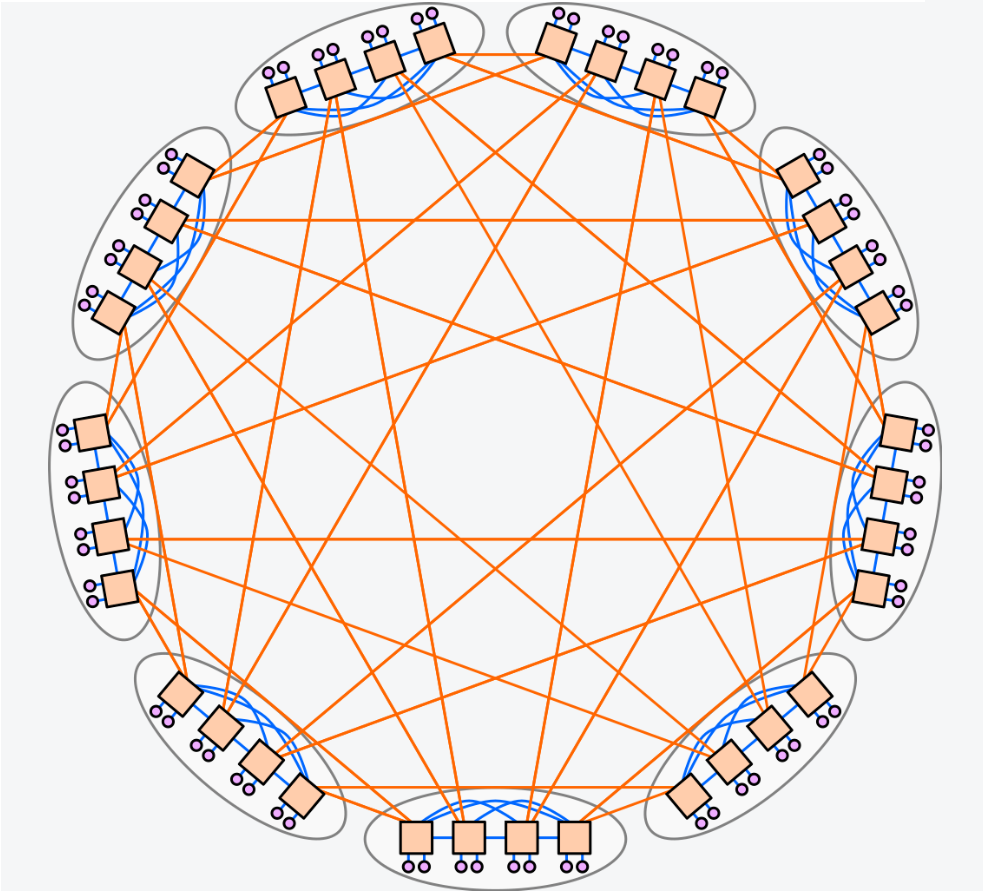
Dragonfly的拓扑结构分为三层:Switch层,Group层,System层。
- Switch层:包括一个交换机(橙色方块),及其相连的p个计算节点(粉色圆圈)。
- Group层(灰色椭圆):包含a个Switch层,这a个Switch层的a个交换机是全连接(All-to-all)的,换言之,每个交换机都有a-1条链路连接分别连接到其他的a-1台交换机。
- System层:包含g个Group层,这g个Group层也是全连接的。
https://zhuanlan.zhihu.com/p/32216294
破茧化蝶,从Ring Bus到Mesh网络,CPU片内总线的进化之路
https://blog.csdn.net/CodeSavior/article/details/114446140
Spine+Leaf叶脊网络架构
https://zhuanlan.zhihu.com/p/371827494
片内互联中常用的拓扑结构
https://www.modb.pro/db/650884
一文读懂Dragonfly网络拓扑
https://www.cnblogs.com/jmilkfan-fanguiju/p/11825042.html
数据中心网络架构的问题与演进 — CLOS网络与Fat-Tree、Spine-Leaf架构
https://arxiv.org/pdf/2503.20377
UB-Mesh(HW提出的互联方案)
NVLink
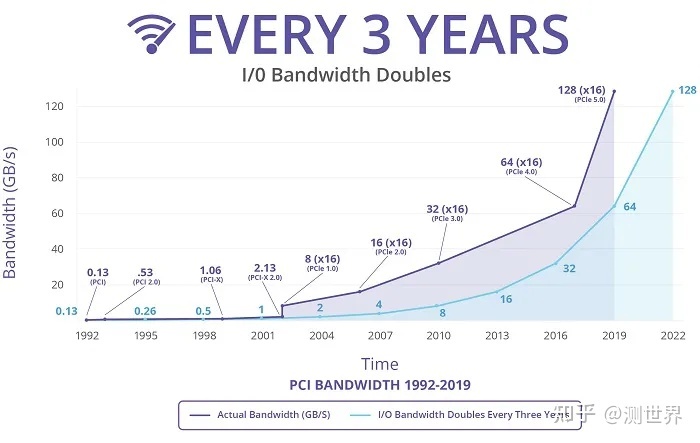
NVLink技术提供比PCIe 3更高的带宽与更多的链路,并可提升多GPU和多GPU/CPU系统配置的可扩展性。
SXM是Nvidia的双插槽卡设计,与PCIe卡不同,它不需要连接电源。
官网:
https://www.nvidia.cn/data-center/nvlink/
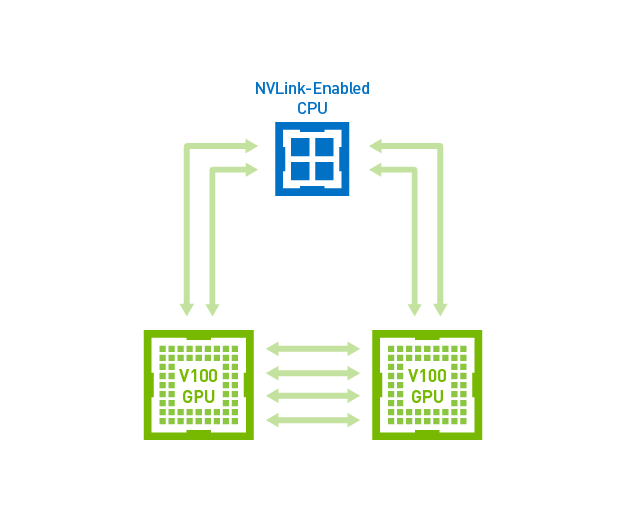
Tesla V100中以NVLink连接的GPU至GPU和GPU至CPU通信。
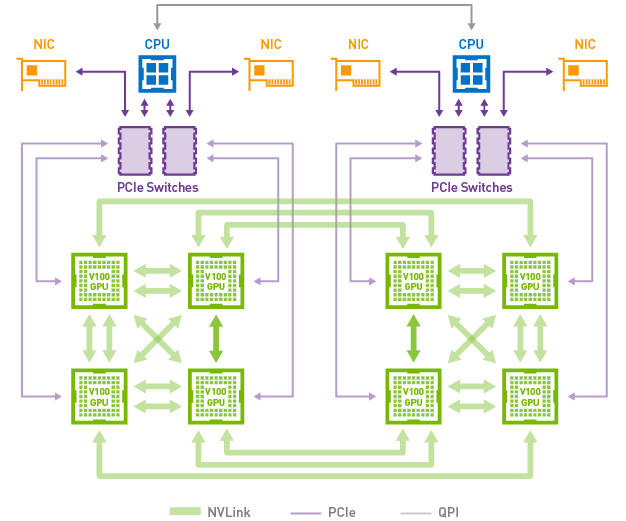
在DGX-1V服务器中,混合立体网络拓扑使用NVLink连接8个Tesla V100加速器。每个GPU有6条nvlink通道,总带宽高达300GB/s。
从上图可以看到,即使每个GPU拥有6条nvlink通道,仍然无法做到“全连接”(即任意两个GPU之间存在双向通道)。这就引出了下一个更加疯狂的技术:nvswitch。

NV Switch是首款节点交换架构,可支持单个服务器节点中16个全互联的GPU,并可使全部8个GPU对分别以300GB/s的惊人速度进行同时通信。这16个全互联的GPU还可作为单个大型加速器,拥有0.5 TB统一显存空间和2 PetaFLOPS计算性能。
https://zhuanlan.zhihu.com/p/35470532
全球最大GPU背后的秘密:NVSwitch如何实现NVIDIA DGX-2的超强功力?
https://mp.weixin.qq.com/s/3w2wbwaKb9nI2K13-gQXeg
NV Switch深度解析与性能剖析
NVLink和NV Switch的关系:
NVLink是一种协议。
NV Switch是NVLink协议的芯片化实现。
GPU core和NV Switch如果都实现了NVLink协议的话,则它们之间可以通过NVLink协议进行通信。
未来解决带宽问题的两大法宝,一个靠内存厂给提供的牙膏继续叠单GPU芯片的带宽,另一个就是目前这些形态更高密度的通过nvlink组合起来,从而创造一个大的“一个GPU”。
就这个搞一个大的“一个GPU”而言,又有很多种可能的扩展形态
- 双GPU卡
- 主板堆8卡
- 垂直堆8个刀片
- 网络组更多机柜
其实也就对应了nvlink的多种形态
- nvlink c2c
- nvlink switch
- nvlink bridge
- nvlink network
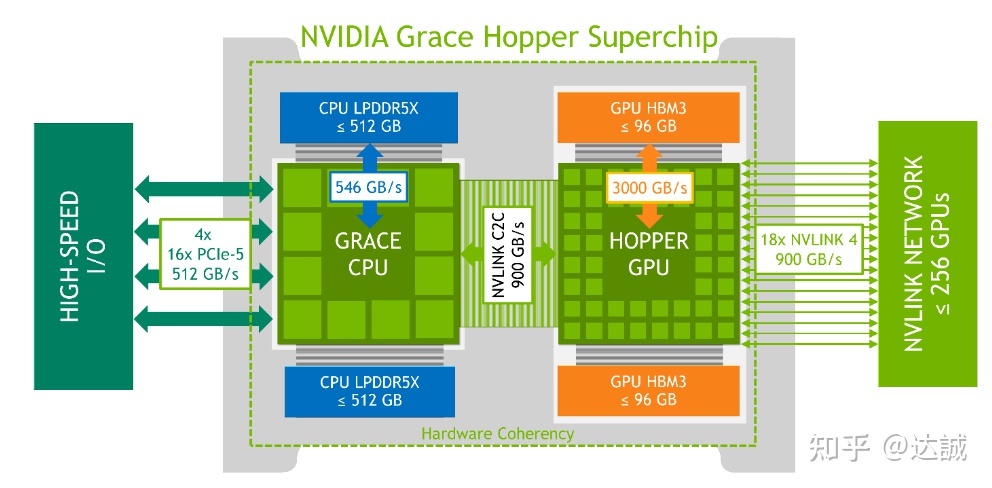
https://zhuanlan.zhihu.com/p/600638633
Nvidia Grace Hopper超级芯片架构解读(一)
https://zhuanlan.zhihu.com/p/601072219
Nvidia Grace Hopper超级芯片架构解读(二)

上图中每个NV switch提供一组单向的50GB/s(即双向100GB/s)的全连接拓扑的带宽,共有6个全连接,加起来就是600GB/s,而且是End to End的带宽。
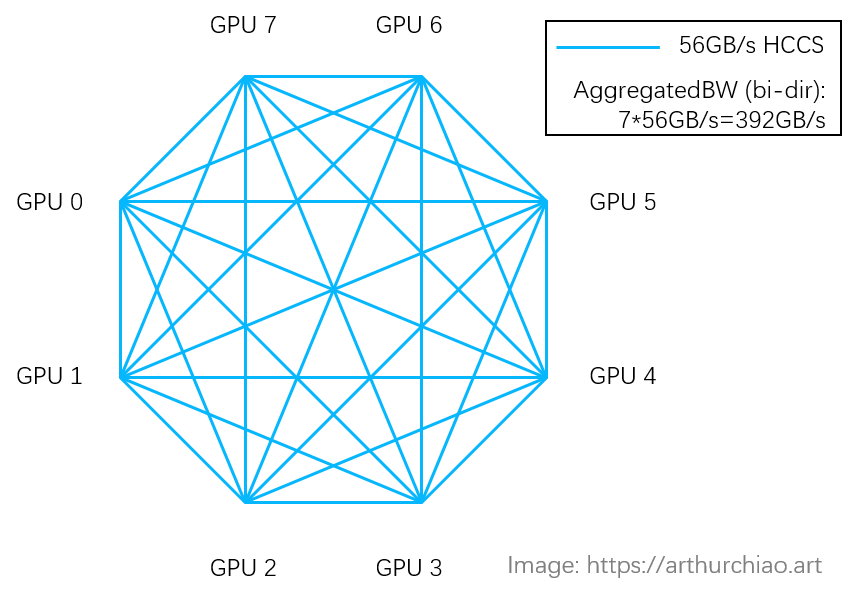
这是HW Ascend 910B的拓扑,由于没有NV switch,所以只有一组全连接,End to End的带宽双向只有56GB/s。所谓的392GB/s,实际上是总带宽。
NVLink4.0和PCIe Gen6都将由NRZ编码切换到支持PAM4,对应的波特率也相似,所以在PHY层面临相似的挑战,单个lane物理层速率几乎一致。
单单从信号线路数量来说,x16的PCIe和x2的NVLink是相同的,都是32对差分线。x2的NVLink 3.0双向带宽是100 GB/s,比PCIe 5.0 x16的126 GB/s要低。
这么高的带宽,数据传输功耗是一个不可忽略的重要因素,NV能做到x18的NVLink,不代表其它厂家可以轻松实现x144的PCIe。
大概在2017年的hotchips上,Intel给出的一份PPT上,PCB上每传输1bit数据的参考功耗是20 pJ(1e-12焦耳),按这个功耗计算,NVLink 3.0 x18的7200 Gbit/s意味着单单是信号传输就要消耗144W功耗,这显然是难以接受的。2019年NV发表过一份1.17 pJ/bit的论文,虽然因为应用环境不同,不能直接对比说NV的技术使得传输功耗不到6%,但还是可以从侧面猜测一下NV的技术水平。
https://www.zhihu.com/question/546809864
为什么NVlink能够实现比PCIe更高的传输带宽?
https://zhuanlan.zhihu.com/p/623060064
什么是NVLink?
https://zhuanlan.zhihu.com/p/672749098
Nvidia GPU互联技术全景图
https://en.wikichip.org/wiki/nvidia/nvlink
NVLink
https://zhuanlan.zhihu.com/p/13380746376
查看显卡之间的拓扑结构(GPU topology)
存储体系
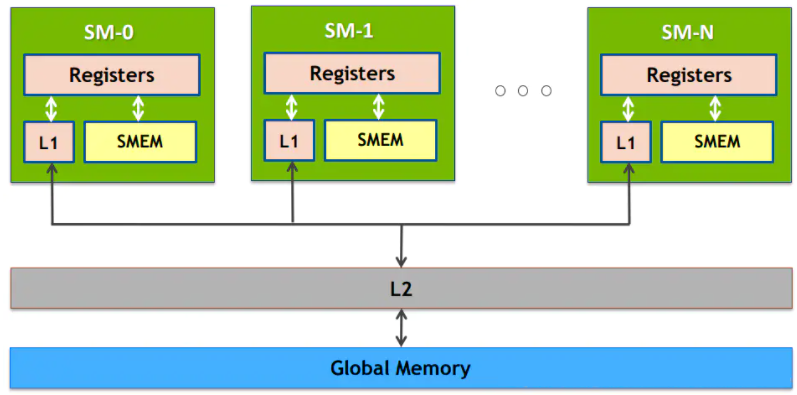

Registers -> Caches -> Shared Memory(Unified Buffer) -> Gloabl Memory(Local Memory)
https://blog.csdn.net/qq_41554005/article/details/119765334
GPU存储资源:寄存器,本地内存,共享内存,缓存,显存等存储器细节
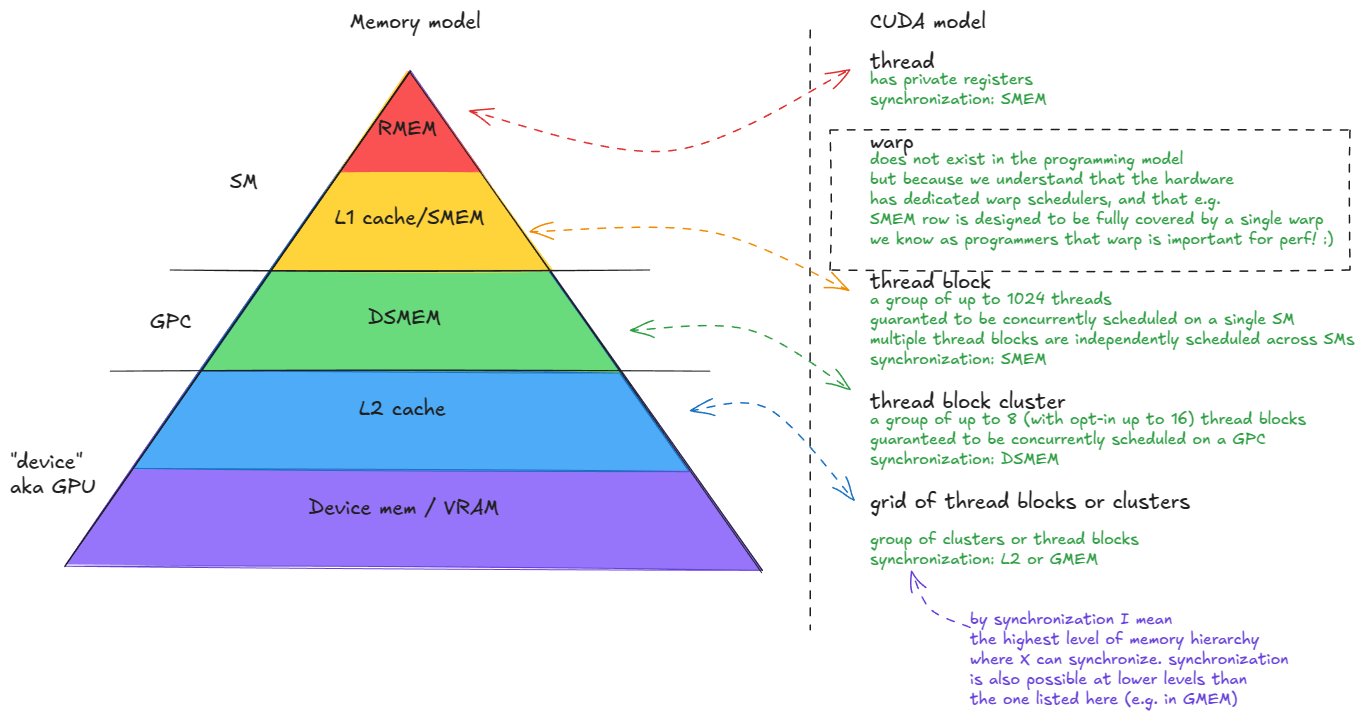
| Hardware Level | Parallel Agent | Data Locale | Capacity @ Bandwidth |
|---|---|---|---|
| Chip | Grid | Global memory | 80 GiB @ 3.35 TB/s |
| GPC | Threadblock Clusters | L2 | 50 MiB @ 12 TB/s |
| SM | Threadblock (CTA) | Shared Memory | 228 KiB per SM, 31TB/s per GPU |
| Thread | Thread | Registers Files | 256 KiB per SM |
通信问题的本质是数据的共享。因此,质不够量来凑,也是一个不错的方法。
由于没有NVLink这样的杀手锏,AMD的AI方案更倾向于增加单卡内存,来减少卡/机的数量。
比如AMD发布的Instinct MI300X GPU,单卡内存192GB,8卡服务器就是1.5TB HBM3内存。
当然,单纯堆料这种没有技术含量的活,对于老黄没有任何难度。老黄反手推出H200,单卡141GB HBM3e。
| 板卡 | 内存 |
|---|---|
| H100 | 80GB HBM2 |
| 昇腾910B | 94GB HBM2 |
| MI300X | 192GB HBM3 |
| H200 | 144GB(24GBx6) HBM3e |
| GB200 | 192GB(24GBx8) HBM3e |
| MI350X | 288GB HBM3e |
理解通信问题的本质是数据的共享,还可以解决另一个问题:通信带宽究竟多大合适?
一般的理论原则是:存储容量向下一级的大容量存储器看齐,读写速度向上一级的快速存储器看齐。因此NVLink的跨卡通信带宽只要能达到Gloabl Memory的水平就可以了,再快也没有意义了,因为系统的瓶颈就在Gloabl Memory的带宽上了。

您的打赏,是对我的鼓励
