Chip » GPU体系结构
2022-05-12 :: 5310 WordsGPU体系结构
从1984年到2004年,仅仅20年的时间,人类就把CPU单核性能提升了200倍以上,但从2004年到2024年,同样是20年的时间,CPU单核性能只提升了3倍,所以大家应该都看出来了,CPU单核性能的提升遇到了巨大的瓶颈。
Intel曾经用自己最强的CPU和NVIDIA的GPU做过性能对比。
两块Xeon 9282(五十六核处理器)的性能是与一块V100非常接近的,但是功率却是V100的两倍多。至于价格方面,据说9282的价格在2.5w-5w美元之间,两块的价格就是5w-10w美元了。
而V100的32GB版的价格约为1w美元(16GB版的大概7000美元),价格差距比能耗差距要大得多。
同等价格的CPU和GPU速度差可能在十倍以上;同等性能的CPU和GPU的价格可能也会接近十倍;
https://www.zhihu.com/question/273812506
CPU和GPU跑深度学习差别有多大?
1992年业界专门讨论过3D游戏的问题,大部分专家都认为3D图形只能由大型图形工作站离线渲染实现,即时演算3D需要的硬件10年内都开发不出来,结果1993年SEGA不仅造出了3D硬件,而且价格不到预测价格的零头,整个游戏市场大洗牌。
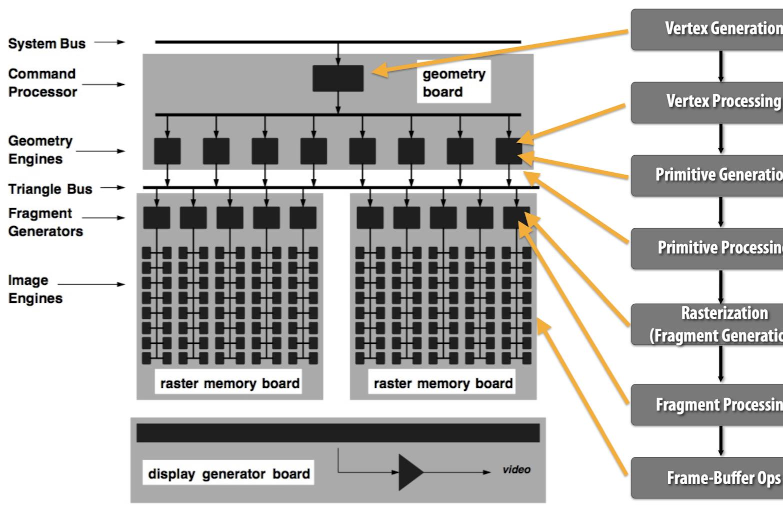
上图是SGI公司1993年的一款显卡的模块图。可以看出,早期的显卡是一个具有固定流水线的专用芯片,只能处理特定任务,没有多少可编程的能力。
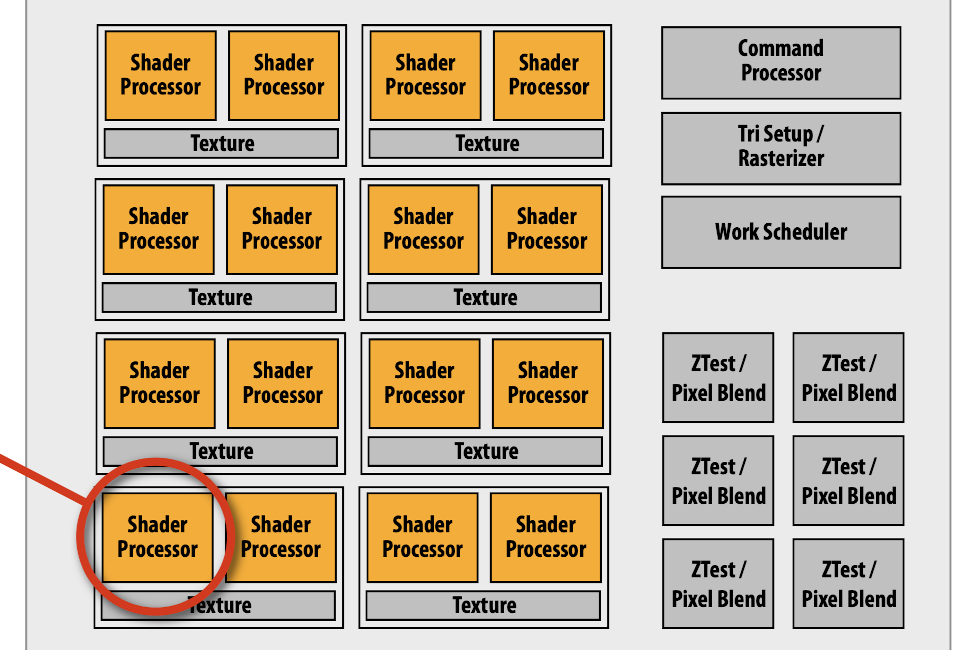
到了2005年左右,这些渲染流水线的功能被统一到一个叫做Shader Processor的可编程单元中。此后,显卡也被称为GPU(Graphics Processing Unit)。
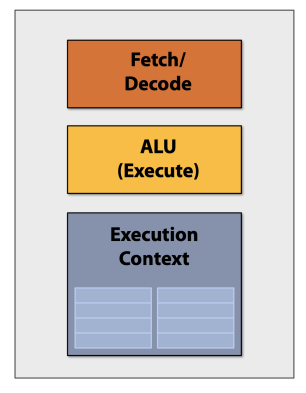
无论是CPU,还是GPU,或者是现在比较火的NPU,一个Processing Unit,一般都是由上图所示的三部分组成:
-
Fetch/Decode。数据的输入/输出单元。
-
ALU(arithmetic and logic unit)。运算单元。
-
Execution Context。寄存器单元。
CPU强调单core的极致性能,因此广泛使用了如下技术:
-
Out-of-order control logic
-
Fancy branch predictor
-
Memory pre-fetcher
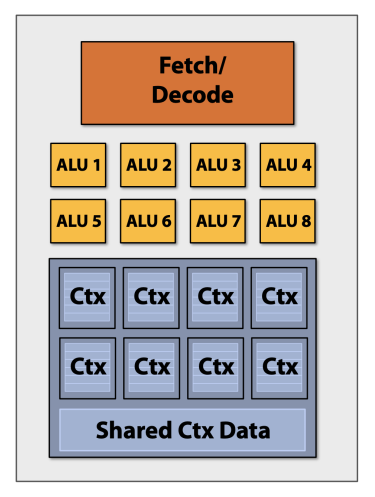
GPU不追求单core的性能,因此也没有那些复杂的控制逻辑。这样省下来的电路,可以变成更多的ALU。由于数据处理的局部性,通常可以若干ALU共享一套Fetch/Decode和Ctx。
当然,如果ALU非常多的话,就不能都共享一套了,这时可以采用下图所示的分组共享。
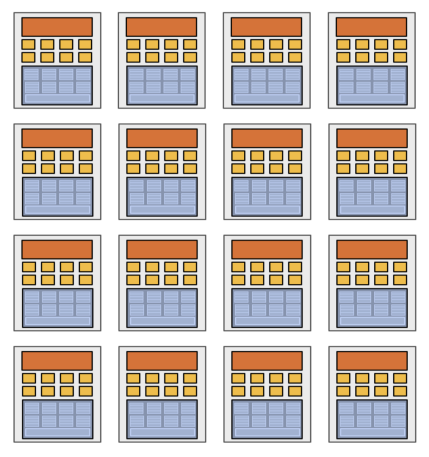
其中的每个组,被称为一个core。
有利就有弊,下面看看GPU是如何执行条件语句的。
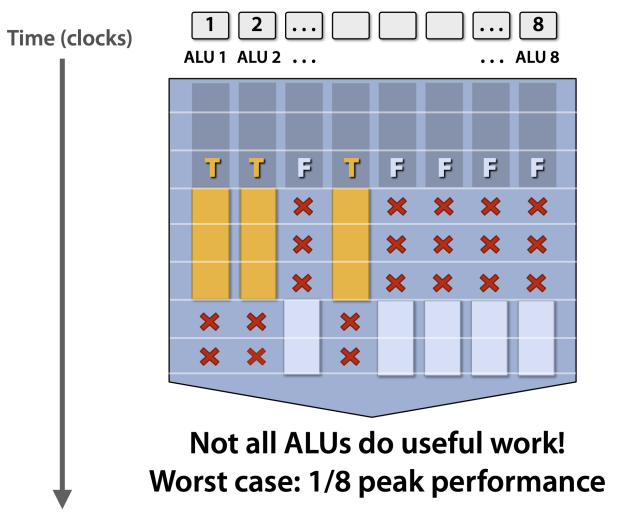
上图展示了8个ALU并行执行条件语句的过程:
-
计算每个数据的条件,生成对应的标志。
-
执行True分支。
-
执行False分支。
可以看出,GPU对于条件语句的执行时间=True分支执行时间+False分支执行时间。而CPU只需要根据条件,执行一个分支就可以了。显然,GPU对于程序的控制能力,相对CPU简直弱爆了。GPU并不擅长做这些东西。
CPU的SSE、AVX之类的指令集,也借鉴了GPU的设计思想,但是CPU的core数,相对于GPU而言,差了10~1000倍。
当线程束中的线程遇到分支语句(如if-else语句)时,如果不同线程的分支条件不同,就会出现线程束分化(Warp Divergence)。此时,线程束会串行地执行不同的分支代码。
反之,如果某个warp中的所有线程条件都为True,则只有True分支会被执行,False分支不会被执行。
Pascal及更早:一个warp共享1个PC,SIMT严格锁步;divergence时硬件把分支压成顺序块,用active mask屏蔽不参与的线程,离开分支点即自动恢复全warp同步。
Volta+:引入Independent Thread Scheduling(ITS),每线程独立PC+栈;调度器仍以warp为单位发射指令,但不同分支可“交错”执行,没有任何隐式汇合点。
VGPR:Vector general purpose register
SGPR:Scalar general purpose register
Two-Level Adaptive Branch Predictor
如今的亚马逊AI/ML总经理Kumar Chellapilla是最早吃到GPU螃蟹的学者。2006年,他使用英伟达的GeForce 7800显卡第一次实现了卷积神经网络(CNN),发现比使用CPU要快4倍。这是已知最早将GPU用于深度学习的尝试。
Programming Model vs Hardware Execution Model
- Programming Model: how the programmer expresses the code.
Sequential (von Neumann), Data Parallel (SIMD), Dataflow, Multi-threaded (MIMD, SPMD), …
- Execution Model: how the hardware executes the code underneath.
Out-of-order execution, Vector processor, Array processor, Dataflow processor, Multiprocessor, Multithreaded processor, …
- Execution Model can be very different from the Programming Model.
von Neumann model implemented by an OoO processor
SPMD model implemented by a SIMD processor (a GPU)
GPU虽然是一个SIMD机器,但是并没有采用SSE、AVX之类的SIMD编程模型,而是SPMD模型。
GPU的缓存策略和CPU不同,没有时间局部性,但有空间局部性:也就是上次操作的数据,后续可能完全没用,倒是本次操作的数据之间,物理上很大可能是连续的。
GPU的线程切换不同于CPU,在CPU上切换线程需要保存现场,将所有寄存器都存到主存中,而一个SM中有高达64k个4 bytes寄存器。而每个Thread最高使用的寄存器数量为255。
也就是说每个线程把寄存器用到爆,也才用了一半的寄存器,那多出来的这些寄存器是干啥的?
其实,GPU的线程切换只是切换了寄存器组,延迟超级低,几乎没有成本。考虑到通常线程并不会使用高达255个寄存器,实际上一个CUDA Core可以随时在八个线程之间反复横跳,那个线程数据准备好了就执行哪个。
移动GPU
移动GPU和桌面GPU最核心的差别在于渲染流程不同。目前主流的移动GPU,无论ARM、高通还是Imagination,其GPU都是TBR(Tile Based Rendering)。而桌面GPU,无论NVIDIA、AMD还是Intel,都是Immediate Rendering。
所谓的Immediate Rendering,就是将一个图元(最常见的是三角形),从头到尾走完整个Pipeline,中间没有停止。这种结构,控制简单,容易实现。问题是在做blending的时候需要从存储单元中不断读回之前render的结果,因此在绘制一个大的场景时这个带宽消耗是比较大的。而桌面GPU都是有自身显存的,它不需要通过系统总线从系统的DDR memory中读回数据。所以开销比较小,这是完全可以接受的。
TBR的精髓就是一个Tile一个Tile的渲染。这样只需要给GPU配上一块很小的片上cache(足够装下一两个Tile的内容就行),就能实现高效的blending。移动GPU中有Tiler模块,将整个场景的图元信息(最主要的是位置)都保存下来,并且能在做光栅化时快速的检索出属于这个Tile的图元。
https://www.zhihu.com/question/20720436
移动GPU和桌面GPU的差距有哪些?
https://zhuanlan.zhihu.com/p/654389634
GPU帧缓冲内存:了解瓦片渲染TBR(tile-based rendering)
GPGPU
通用图形处理器(General-purpose computing on graphics processing units,简称GPGPU),是一种利用处理图形任务的图形处理器来计算原本由中央处理器处理的通用计算任务。这些通用计算常常与图形处理没有任何关系。
从市场宣传的角度,如果某家公司的产品定位为GPGPU,那么也就意味着该GPU没有图形能力。
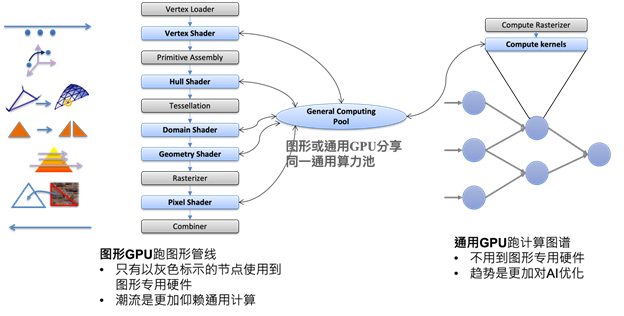
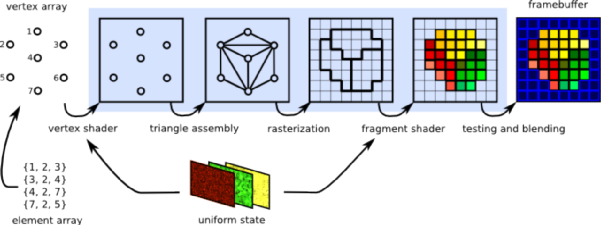
上图展现了GPU和GPGPU之间的差异。
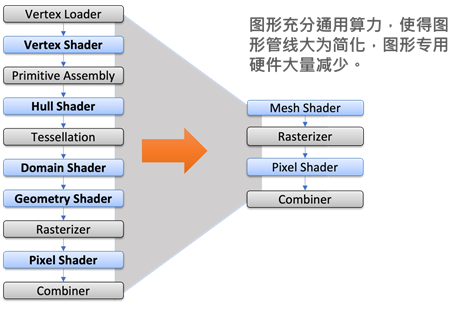
然而通用处理对于图形处理的侵蚀,或者说充分运用AI算力,简化图形专用硬件也是一大趋势。
如上图所示,先进图形标准中,崭新的、更加利用计算功能的mesh shader可以取代从vertex shader到geometry shader的着色器,从而在不减功能的前提下,将图形管线节点数大量减少,并移除一些连接节点的专用硬件。性能还可能因为mesh shader拥有的弹性,而有所提升。
参考
AMD:RDNA
Imagination:PowerVR
Qualcomm:Adreno
ARM:Mali

RDNA是GPU架构,Navi是使用它构建的图形处理器的代号。同样,GCN是架构,而Vega和Polaris是代号。
https://www.expreview.com/68888.html
AMD RDNA显卡架构简析
https://zhuanlan.zhihu.com/p/459812380
AMD RDNA与GCN GPU架构之间的差异:AMD如何赶上NVIDIA
UMD,User Mode Driver。GPU的用户态驱动程序,例如CUDA的UMD是libcuda.so。
KMD,Kernel Mode Driver。GPU的PCIe驱动,例如英伟达GPU的KMD是nvidia.ko。
http://tieba.baidu.com/p/2250616047
史上最全桌面显卡天梯图
https://zhuanlan.zhihu.com/p/365926059
2021超全的显卡挑选指南
https://mp.weixin.qq.com/s/8HIZRhb-KJOtPnQtQ3GQVg
第一代芯片是CPU,第二代是GPU,第三代是什么?
https://mp.weixin.qq.com/s/qkpbKN62YV2f0W5HLnr7Dg
GPU是如何工作的?与CPU、DSP有什么区别?
https://mp.weixin.qq.com/s/Jof-u8oUuLR4v7t3jjXEmA
GPU和线下训练
https://mp.weixin.qq.com/s/HeoVktVtvOK4VgocyxuCXg
摩尔定律已死?GPU会取代CPU的位置吗?
https://mp.weixin.qq.com/s/zTO4UZ3zDLZL0GOjv0YqrQ
GPU加速深度学习
https://mp.weixin.qq.com/s/VysqrYVXG1JiNG86viQ6Xg
学深度学习的你有GPU了吗
https://mp.weixin.qq.com/s/fUl-YjMlfZs9XXZ1W4DFBQ
GPU历史系列(一):故事从20世纪70年代讲起
https://mp.weixin.qq.com/s/QuvpUYNhmf3htl0ea9TT8Q
GPU历史系列(二):改变游戏规则的3Dfx Voodoo
https://mp.weixin.qq.com/s/BisVJ3VDxcUpSMyoGmQicw
GPU历史系列(三):Nvidia一统江湖
https://mp.weixin.qq.com/s/5ahh8EihTefzMmCGSwmwHw
GPU历史系列(四):通用GPU的来临
https://mp.weixin.qq.com/s/iBgTyDiNNTUuuCgWJCyKig
深度报告:GPU产业纵深及国产化替代
https://zhuanlan.zhihu.com/p/463629676
从AI系统角度回顾GPU架构变迁–从Fermi到Ampere
https://zhuanlan.zhihu.com/p/4610879668
Nvidia GPU架构精读系列——Ampere

您的打赏,是对我的鼓励
