Chip » CPU(三)——芯片制造
2021-07-01 :: 5676 WordsCPU
芯片制造

https://mp.weixin.qq.com/s/jGzdfEJaulPRjt89eLST4Q
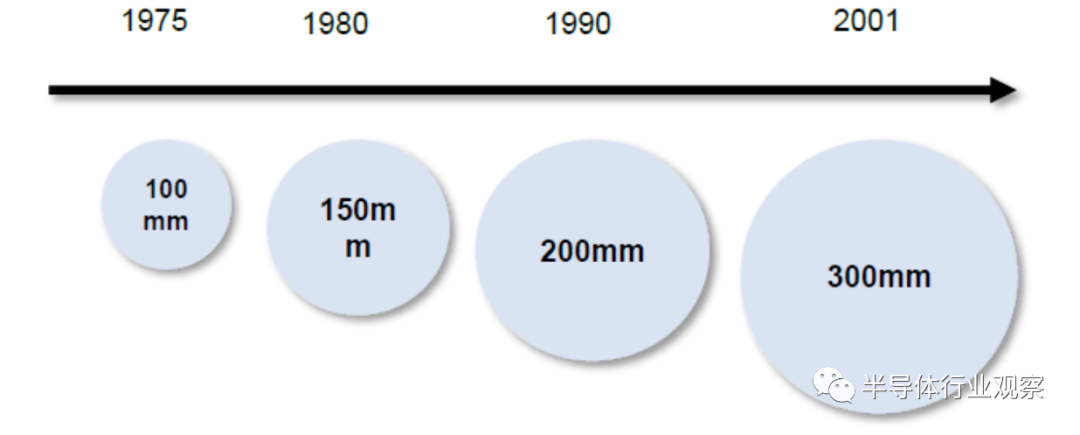
8英寸晶圆30年
半导体产业发展至今经历了三个阶段,第一代半导体材料以硅为代表;第二代半导体材料砷化镓也已经广泛应用;而以氮化镓和碳化硅、氧化锌、氧化铝、金刚石等宽禁带为代表的第三代半导体材料。
一个新节点多少良率才算是达到量产水平,这是最说不清的环节。按台积电的做法,有外部客户愿意在当前良率下单(因为良率不足的坏片,惯例是由客户承担),并顺利产出才称为量产,也就是所谓的商业量产。
三星每个节点的首发客户基本都是内部的三星电子,一般在低良率阶段开启风险试产,并同时对外宣称量产。
厂家有时候会透露自己良率已经到60%甚至80%,但这其中也有模糊地带,一般情况下80%的良率,只是对应矿机ASIC这种简单芯片,手机AP的良率则有可能不到50%,而如果是GPU这类面积大的芯片可能只有20%出头。
所有的制程技术数据,包括各站机台的运行参数,业内称为recipe,在台积电recipe是第一等的机密,专门有个recipe management system进行管理。
https://mp.weixin.qq.com/s/QF9Nsh_YyX9LZQ_D-4hP-A
芯片是怎么制造的?央视最强科普!
https://mp.weixin.qq.com/s/bKgYpZdXxAexlEtmPQ9oGw
科普:芯片是怎么从沙子中一步步炼成的!
https://mp.weixin.qq.com/s/9y5HFTQr2QP12iR858BFtg
图解intel芯片生产全过程!
https://mp.weixin.qq.com/s/aSCcdTHUoogP7TOK5MIsVw
一颗芯片的全球之旅
https://mp.weixin.qq.com/s/LcnyAhOofWyGHikYwfIlIA
芯片的诞生
https://mp.weixin.qq.com/s/lD2bkDIX6ey-VHchSdbW7g
漫画芯片
https://mp.weixin.qq.com/s/v3wauOfWw6TLlxTH4QKR6w
一文详解MOS管
https://mp.weixin.qq.com/s/kzQ-WqozBX-T8ZyS58MPnw
一张图了解芯片到底是如何设计的
参考
https://zhuanlan.zhihu.com/p/34003929
调试程序时,设置断点的原理是什么?
Visual Studio有个有趣的特性是debug编译后,会把0xcc(INT 3)填入代码的空隙,这样一旦程序越界就会被VS捕捉而容易发现错误。而0xCCCC在中国的GBK编码是“烫”。有中国程序员翻看内存到代码段会发现很多”烫烫烫”,不明所以,以为发生了什么神奇的事情。
https://mp.weixin.qq.com/s/k0u7pVzf7tjVF4UjZ3ai7A
忆阻器的前世今生
https://mp.weixin.qq.com/s/rSGRXfN4z3ElP7iQX1umjQ
基于新型忆阻器的存内计算原理、研究和挑战
是因为AMD做不出(或者说基于成本不愿意做)单个N核心(N>8)的Die,单个Die是由两个CCX组成的Zeppelin模块,12nm制程单个Die面积213mm^2,为了堆核心只能用胶水把4个Die封装在一起。Intel是一个Die就28核心,14nm制程的CSL(Cascade Lake)架构单个Die面积就694mm^2,Xeon 9282的胶水双核已经够大了。
https://www.zhihu.com/question/322451170
为什么amd能胶水做到8die,intel最多胶水2die?
带宽收敛是指数据报文的流量收敛,是指数据报文在网络转发过程中由于架构、设备等非故障原因而不能实现线速无丢包转发。在流量收敛时,网络设备会有部分端口拥塞,进而丢弃部分报文。
带宽收敛比:若4台服务器分别通过千兆链路连接接入交换机,接入交换机通过1条千兆链路连接核心交换机。即接入交换机的下行带宽为4Gbps,接入交换机的上行带宽为1Gbps,为非对称链路,下上行链路收敛比为下行带宽(4Gbps)÷上行带宽(1Gbps)=4:1。带宽收敛比实际上就是带宽超卖的比例。
Engineering Change Order
https://zhuanlan.zhihu.com/p/20914909
IC科普文:ECO的那些事
Register Transfer Level
https://blog.csdn.net/hqzl225411/article/details/117819843
RTL概念与常用RTL建模
同一片晶圆切下来的Die,体质卓越的,是13900KS。
体质优秀的,是13900K。
体质一般的,是13900。
CPU侧体质优秀,但GPU侧一塌糊涂的,是13900KF。
CPU侧体质一般的,GPU还一塌糊涂的,是13900F。
CPU侧体质都一塌糊涂的。剁去一对体质最差的大核和一簇体质最烂的小核,然后降频运行,叫做13700K。
https://zhuanlan.zhihu.com/p/29743431
CPU制造的那些事之一:i7和i5其实是孪生兄弟!?
https://zhuanlan.zhihu.com/p/29767262
CPU制造的那些事之二:Die的大小和良品率
缩肛是指处理器一开始可以标准电压跑高频,但是老化过快,很快就不得不降频使用的虚假标注现象。这里借用了汽车发动机故障的术语。
https://www.zhihu.com/question/662836115
13/14代 i7 i9 处理器大规模缩肛为什么没有在老化测试时发现?
现在游戏优化基本都是6核起步。E5单核还算够用,多核心+大三缓歪打正着地撞中了趋势。
板U守恒定律”——主板贵时CPU普遍就便宜,而E5主板即便寨板都不是很便宜,上限又有限,只能CPU狂跌价咯。
https://www.zhihu.com/question/7698341480
二手主机市场里的。处理器为英特尔e5 12核24线程的机特别多,为何?
https://mp.weixin.qq.com/s/Cij_95iLbAm0AEtrSb72_A
关于CPU科普,这篇说得最详细
https://zhuanlan.zhihu.com/p/31848803
为什么CPU越来越多地采用硅脂而不是焊锡散热?
https://zhuanlan.zhihu.com/p/27624654
CPU风扇停转后会发生什么?CPU凭什么烧不坏
https://zhuanlan.zhihu.com/p/30409360
为什么CPU的频率止步于4G?我们触到频率天花板了吗?
https://zhuanlan.zhihu.com/p/33145828
什么是Speculative Execution?为什么要有它?
http://mp.weixin.qq.com/s/sshhUppVPP6qM7LH1V3nSQ
四位计算机的原理及其实现
https://zhuanlan.zhihu.com/p/33579054
Reset重启后发生了什么?它和关机后再开机有什么区别?
https://zhuanlan.zhihu.com/p/34091597
ARM攒机指南-网络篇
https://zhuanlan.zhihu.com/p/34223088
如何进入BIOS?
https://www.zhihu.com/question/638180886
电脑启动时的BIOS程序,多核CPU是怎么决定将哪个核心分配给它的?
https://zhuanlan.zhihu.com/p/30565679
人工智能技术热潮中,是否存在破解苹果A11处理器的可能?
https://mp.weixin.qq.com/s/UWpp2r0_yDxNyJk-cldVyA
处理器高危漏洞无人幸免?树莓派:我们不受影响
最近的Meltdown和Spectre漏洞被炒的沸沸扬扬,然而能用python语言讲述复杂的CPU计算原理,这是该文的一大创见。
https://mp.weixin.qq.com/s/v_BsfSFp-LwiCOFKaMIS_g
后摩尔时代,如何给你的CPU减负?
https://mp.weixin.qq.com/s/gpfMOW7gzVa2HhYOlDy2nQ
从Intel和ARM争霸战,看看做芯片有多难
https://zhuanlan.zhihu.com/p/43626576
关于芯片,这篇说得最详细!
https://zhuanlan.zhihu.com/p/43768401
如何像搭积木一样构建CPU?Intel和AMD都是怎么做的?
https://zhuanlan.zhihu.com/p/48593932
CPU底部的小块是干什么用的?为什么CPU这么多电源引脚?
https://zhuanlan.zhihu.com/p/51145563
TDP是CPU的功耗吗?TDP是固定不变的吗?
https://mp.weixin.qq.com/s/gzE46SzANLaYaXdLVEBRaA
专家揭秘“低功耗芯片设计”真相
https://mp.weixin.qq.com/s/pFBhnjtXi8uNMGjYFeSfow
芯片行业都难在哪儿?这篇说得最详细!
https://mp.weixin.qq.com/s/nDWJS4rfWsqeVgJQbAYQ6w
一文看懂IGBT(绝缘栅双极型晶体管)
https://mp.weixin.qq.com/s/4_eGNtXULAdK9UzsP1mwKA
IGBT的现状与发展
https://mp.weixin.qq.com/s/TG6C4P-DvhRTJ2FoU8PFtw
IGBT基础与运用知识
https://zhuanlan.zhihu.com/p/56864499
CPU是怎么调节输入电压的?为什么要这么做?
https://mp.weixin.qq.com/s/JLg6sEwCxTMpo2nyCt50qg
指令集——CPU芯片江湖中的门派标志
https://mp.weixin.qq.com/s/7gXK6Qv9gLMkYtXw9oz9Sg
一文看懂指令集是什么
https://mp.weixin.qq.com/s/p7FKgx-sFGDJF0y4IGWvyg
CPU指令集架构科普
https://mp.weixin.qq.com/s/26se041cc9aBRw16kvPPjA
芯片制造新模式–像搭积木一样造芯片
https://mp.weixin.qq.com/s/lz6EoLiLtPtWFMG1FJCuQw
化合物半导体的机遇
https://mp.weixin.qq.com/s/tTtySk3u6m2BGUkDto5Ojw
可重构芯片的方法学原理
https://mp.weixin.qq.com/s/RkRZX_scr__Q_mLPhaaWAA
AMD Zen 2处理器架构为何要如此设计?
https://en.wikichip.org/wiki/amd/microarchitectures/zen_2
Zen 2 - Microarchitectures - AMD
https://mp.weixin.qq.com/s/dRv4xWV8laCYBaZ0DwOC3A
如何从零开始设计一颗芯片?
https://mp.weixin.qq.com/s/eAzdtKvfw7EVz5Ax3nXeZg
自己动手设计专用处理器
https://mp.weixin.qq.com/s/NfNJVoAC5aW1sgToAmYsGw
3nm芯片终结者
https://mp.weixin.qq.com/s/o8C6n-ZRw3vFS8E-hikXJQ
移动的王者:深入分析ARM最强处理器Cortex A77
https://www.cnblogs.com/f-ck-need-u/p/11141636.html
关于CPU的一些基本知识总结
https://mp.weixin.qq.com/s/vTOGmcahRxQBH8RgkTJ2GA
中文系同学都能听懂的集成电路设计流程
https://mp.weixin.qq.com/s/O-2ecxYVOgEfRuwEoS7gRA
Fab的那些事儿
Fab的全称叫Fabrication,也就是集成电路制造的工厂、车间。
https://mp.weixin.qq.com/s/_NcQ-PxNpEtpYdo450Uukg
半导体材料全球格局
https://mp.weixin.qq.com/s/QwE_VTEUS9kGDDrHlzPYmg
硅片为什么不是方的?
https://zhuanlan.zhihu.com/p/32378843
ARM攒机指南-汽车篇
https://mp.weixin.qq.com/s/Hq9hzkyfGcCQa_FfzSDoRg
5nm工艺节点以后,半导体器件的发展方向
https://zhuanlan.zhihu.com/p/66263349
为什么内存和闪存制程比CPU低?它们现在都在什么节点?
https://zhuanlan.zhihu.com/p/114448236
什么是Win10的“现代待机”?为什么它未来会越来越重要?这篇文章部分解释了我的第一个平板为什么那么耗电。
https://mp.weixin.qq.com/s/J7RlmvU7JY1J8rV-eqjQ2A
浅谈多核心CPU和SoC芯片及其工作原理
https://mp.weixin.qq.com/s/Lnrlv7JcrOSwbnDweYf1Yg
片上系统设计案例分析-Xbox主机

您的打赏,是对我的鼓励
