Attention » Attention(五)——ERNIE, XLNet, 轻量化Transformer, Attention in CV & RS
2020-04-27 :: 8012 WordsGPT(续)
https://mp.weixin.qq.com/s/eJn379q9raDHY9FdWaXeKQ
AI界最危险武器GPT-2使用指南:从Finetune到部署
https://mp.weixin.qq.com/s/WDFwKqNynwPtXhM8rZnOsA
自动生成马斯克的推特几乎无破绽!MIT用GPT-2模型做了个名人发言模仿器
https://mp.weixin.qq.com/s/67Z_dslvwTyRl3OMrArhCg
完全图解GPT-2(一)
https://mp.weixin.qq.com/s/xk5fWrSBKErH8tvl-3pgtg
完全图解GPT-2(二)
https://zhuanlan.zhihu.com/p/80215294
GPT:第一个引入Transformer的预训练模型
https://mp.weixin.qq.com/s/dibf3bU4hQ7nXTPGMFsKbg
GPT-3王者来袭!1750亿参数少样本无需微调,网友:“调参侠”都没的当了
https://mp.weixin.qq.com/s/aPA0PEqVn509u3xbgmhIwQ
一天star量破千,300行代码,特斯拉AI总监Karpathy写了个GPT的Pytorch训练库
https://mp.weixin.qq.com/s/FOCR-9X5LVtjxVMWoAtw4g
GPT的野望
ERNIE
ERNIE是百度2019年提出的。
论文:
《ERNIE: Enhanced Representation through Knowledge Integration》
《ERNIE 2.0: A continual pre-training framework for language understanding》
代码:
https://github.com/PaddlePaddle/ERNIE/
除此之外,清华也有一篇叫ERNIE的论文:
《ERNIE: Enhanced Language Representation with Informative Entities》
这几篇论文主要讨论了,如何将语义信息融入BERT。篇幅原因,这里只关注百度的两篇论文的做法。
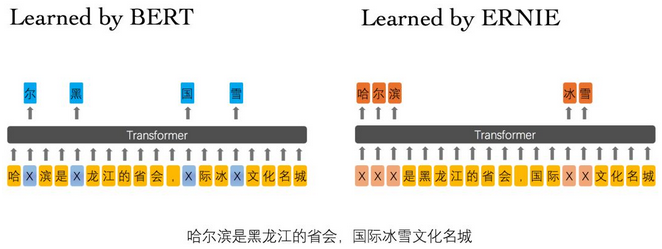
相较于BERT学习原始语言信号,ERNIE模型通过对词、实体等语义单元的掩码,使得模型学习完整概念的语义表示。上例中,BERT通过“哈”与“滨”的局部共现,即可判断出“尔”字,但它没有学习到与“哈尔滨”相关的知识。而ERNIE通过学习词与实体的表达,使模型能够建模出“哈尔滨”与“黑龙江”的关系,学到“哈尔滨”是“黑龙江”的省会以及“哈尔滨”是个冰雪城市。

为了学习相关语义,ERNIE提出了如上图所示的不同级别的mask方法。
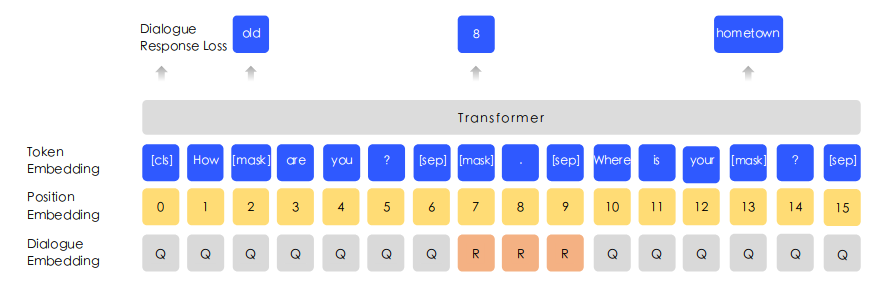
还有如上图所示的语义嵌入。
BERT已经证明了预训练模型对于多种NLP任务的有效性,因此使用多任务学习就成为一个很自然的想法。
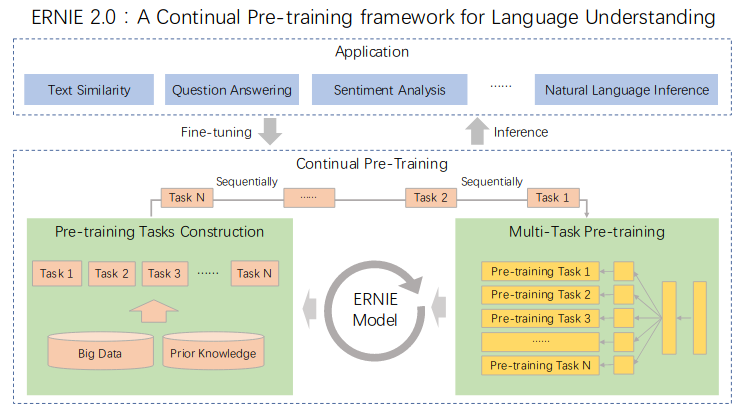
上图是ERNIE 2.0的多任务训练的结构图。可以认为ERNIE 2.0就是多任务版的ERNIE。
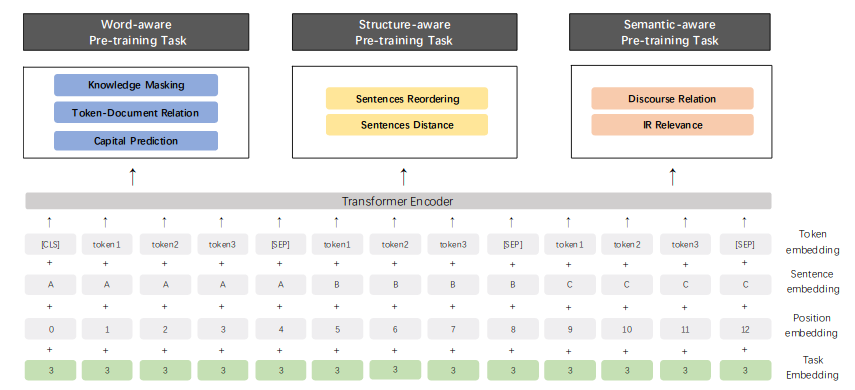
为了适应多任务版本的要求,ERNIE 2.0还提出了Task Embedding。
参考:
https://mp.weixin.qq.com/s/xoQhz6ljbsbzKRBJlTQQuQ
百度提出ERNIE,多项中文NLP任务表现出色
https://mp.weixin.qq.com/s/rQ8ISipvV3Irrjd3MI-Idw
百度ERNIE,中文任务全面超越BERT
https://mp.weixin.qq.com/s/_ZBvq7gXvbiP2IQve9tcKg
清华等提出ERNIE:知识图谱结合BERT才是“有文化”的语言模型
https://mp.weixin.qq.com/s/QVEYQfEQV0CsklI9S4vOiA
ERNIE真有官方说的那么好?亲测告诉你答案!
https://mp.weixin.qq.com/s/FoX2bXCJlFYjb9U6JcZCqg
超详细中文预训练模型ERNIE使用指南
https://mp.weixin.qq.com/s/EYQXM-1WSommj9mKJZVVzw
百度正式发布ERNIE 2.0,16项中英文任务超越BERT、XLNet,刷新SOTA
https://mp.weixin.qq.com/s/PwiVCgN8dDWXTGZsiqM-2g
最新NLP架构的直观解释:多任务学习–ERNIE 2.0
https://mp.weixin.qq.com/s/yZvKMaBZyodr8SLvcAn7Mg
深度剖析知识增强语义表示模型——ERNIE
https://mp.weixin.qq.com/s/mPPnPwAvPzvJtv0B8jjDbw
详解ERNIE-Baidu进化史及应用场景
https://mp.weixin.qq.com/s/r5Vk_hc5-jsZ69y0dfqIfg
登顶GLUE的百度ERNIE再突破:语言生成预训练模型ERNIE-GEN刷新SOTA
XLNet
杨植麟是Transformer-XL与XLNet的共同一作,清华本科(2015)+CMU博士(2019),月之暗面(Moonshot AI)创始人,清华大学助理教授。
https://mp.weixin.qq.com/s/29y2bg4KE-HNwsimD3aauw
20项任务全面碾压BERT,CMU全新XLNet预训练模型屠榜
https://mp.weixin.qq.com/s/wlV8UbOUYSmc-AdaGfQQMQ
XLNet详解
https://mp.weixin.qq.com/s/itNtDuQS4KF_sLnfiwdyNg
拆解XLNet模型设计,回顾语言表征学习的思想演进
https://mp.weixin.qq.com/s/2zuR0x-Cb1NTeRHYeTjrHQ
一文详解Google最新NLP模型XLNet
https://mp.weixin.qq.com/s/t8XDCPOYna8mZ1Iqk_g7Zw
最新语言表示方法XLNet
https://zhuanlan.zhihu.com/p/70257427
XLNet:运行机制及和Bert的异同比较
https://mp.weixin.qq.com/s/SAiIIa9_-16dqRMKASsuhw
追溯XLNet的前世今生:从Transformer到XLNet
https://mp.weixin.qq.com/s/qzAN6VlKcfqmpX9kQCJ7Gg
XLnet:GPT和BERT的合体,博采众长,所以更强
https://zhuanlan.zhihu.com/p/80216580
XLnet:集合了GPT和BERT的预训练模型
https://mp.weixin.qq.com/s/7ZTDJmsOxOwJ7fYUxK6eTw
XLNet详解
https://zhuanlan.zhihu.com/p/107350079
什么是XLNet,它为什么比BERT效果好?
https://mp.weixin.qq.com/s/EozsQNQ2YrczRg18hTZBhA
什么是XLNet中的双流自注意力
https://mp.weixin.qq.com/s/VfytCWa-h8CmUZW1RWAdnQ
从XLNet的多流机制看最新预训练模型的研究进展
https://mp.weixin.qq.com/s/LurjTAjq4bVxDxIefSxcwg
XLNET:换一个思路做预训练,效果杠杠滴
轻量化Transformer
| Paper | Prune | Factor | Distill | W. Sharing | Quant. | Pre-train | Downstream |
|---|---|---|---|---|---|---|---|
| Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning | Y | Y | Y | ||||
| Are Sixteen Heads Really Better than One? | Y | Y | |||||
| Pruning a BERT-based Question Answering Model | Y | Y | |||||
| Reducing Transformer Depth on Demand with Structured Dropout | Y | Y | |||||
| Reweighted Proximal Pruning for Large-Scale Language Representation | Y | Y | |||||
| Structured Pruning of Large Language Models | Y | Y | |||||
| ALBERT: A Lite BERT for Self-supervised Learning of Language Representations | Y | Y | Y | ||||
| Extreme Language Model Compression with Optimal Subwords and Shared Projections | Y | Y | |||||
| DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter | Y | Y | |||||
| Distilling Task-Specific Knowledge from BERT into Simple Neural Networks | Y | Y | |||||
| Distilling Transformers into Simple Neural Networks with Unlabeled Transfer Data | Y | Y | |||||
| Attentive Student Meets Multi-Task Teacher: Improved Knowledge Distillation for Pretrained Models | Y | Multi-task | Y | ||||
| Patient Knowledge Distillation for BERT Model Compression | Y | Y | |||||
| TinyBERT: Distilling BERT for Natural Language Understanding | Y | Y | Y | ||||
| MobileBERT: Task-Agnostic Compression of BERT by Progressive Knowledge Transfer | Y | Y | |||||
| Q8BERT: Quantized 8Bit BERT | Y | Y | |||||
| Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT | Y | Y |
https://www.zhihu.com/question/347898375
如何看待瘦身成功版BERT——ALBERT?
https://zhuanlan.zhihu.com/p/316865623
2020年9月谷歌研究给出的综述“Efficient Transformers: A Survey”
https://mp.weixin.qq.com/s/a0d0b1jSm5HxHso9Lz8MSQ
小版BERT也能出奇迹:最火的预训练语言库探索小巧之路
https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650771134&idx=2&sn=012082a897dbf125000e38b73520c51d
TinyBERT:模型小7倍,速度快8倍,华中科大、华为出品
https://mp.weixin.qq.com/s/rBiafIT8JUuSe_zib9yssw
TinyBert: 模型蒸馏的全方位应用
https://mp.weixin.qq.com/s/i82wGiSOlA4l4ozimrE2gg
加速BERT模型有多少种方法?从架构优化、模型压缩到模型蒸馏最新进展详解!
https://mp.weixin.qq.com/s/R2MW_5kskvXyuSOh7kfJaA
ALBERT:更轻更快的NLP预训练模型
https://mp.weixin.qq.com/s/dWzpqP_U8Y5DyfWHVTl5Vg
BERT瘦身之路:Distillation,Quantization,Pruning
https://mp.weixin.qq.com/s/DAsY9-Dl5T6peo_71ICOtw
基于ALBERT的文本相似度计算
http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
15篇论文全面概览BERT压缩方法
https://mp.weixin.qq.com/s/5tYuP09dtkmYYGX2R-mCPQ
从transformer到albert
https://zhuanlan.zhihu.com/p/110934513
关于BERT的模型压缩简介
https://mp.weixin.qq.com/s/CkAHKXWi24tDBz4HiWkhBw
模型小快好!微软预训练语言模型通用压缩方法MiniLM助你“事半功倍”
https://mp.weixin.qq.com/s/iLO1FOE-4z1p07RCfCJIaA
MiniLM:通用模型压缩方法
https://mp.weixin.qq.com/s/LF8TiVccYcm4B6krCOGVTQ
ALBERT论文图解介绍
https://mp.weixin.qq.com/s/QdrwlaFZi3VRGptw4cYJSQ
别再蒸馏3层BERT了!变矮又能变瘦的DynaBERT了解一下
https://mp.weixin.qq.com/s/1ZqLWCeyUeb8rsuwTJeZQw
如何修剪BERT达到加速目的?理论与实现
https://mp.weixin.qq.com/s/I_MbkbpyQWKCA8QQu5355A
MobileBERT:一个在资源有限设备上使用的BERT模型
https://mp.weixin.qq.com/s/jBJvrR71OIov2aOucFfd6Q
BERT模型压缩技术概览
https://mp.weixin.qq.com/s/LXp6otaW34r0v8yc4TJNog
LSRA: 轻量级Transformer,注意力长短搭配
https://zhuanlan.zhihu.com/p/343229835
Poor Man’s BERT: 更小更快的Transformer模型
https://mp.weixin.qq.com/s/u44jtXwNCzsZcrr9WrytLQ
EdgeBERT:极限压缩,比ALBERT再轻13倍!树莓派上跑BERT的日子要来了?
https://mp.weixin.qq.com/s/sNv9UirZJ6xT3zf8XhJaRg
FastFormers:实现Transformers在CPU上223倍的推理加速
https://mp.weixin.qq.com/s/6RUvMR-fjzB5PkZBQ4YFNQ
BERT模型压缩:量化、剪枝和蒸馏
https://zhuanlan.zhihu.com/p/576495529
Fast and Effective!一文速览轻量化Transformer各领域研究进展
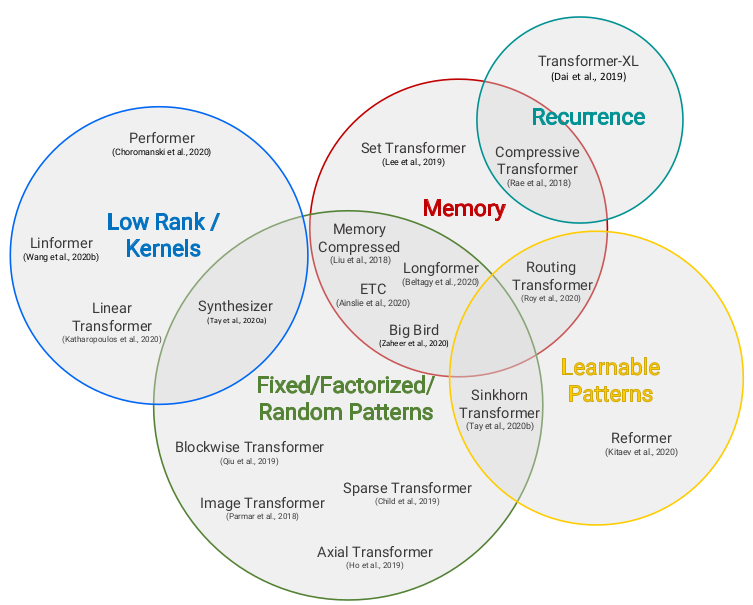
Linformer
https://mp.weixin.qq.com/s/IOc-gxOa6a415Hf1VBmiQw
“Linformer”拍了拍“被吊打Transformers的后浪们”
https://mp.weixin.qq.com/s/cDQW5992hTaeGoA7zL7Vzg
Linformer: 线性复杂度的Attention
Self-Attention 加速方法一览:ISSA、CCNet、CGNL、Linformer
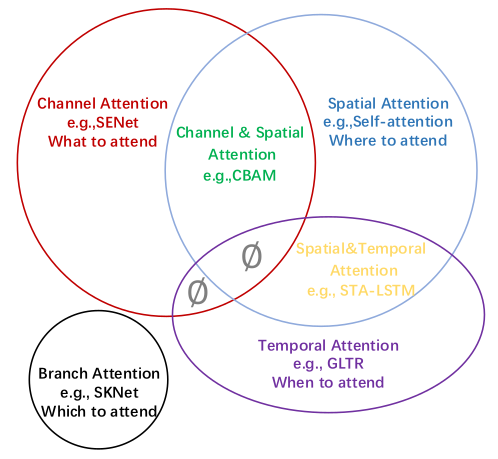
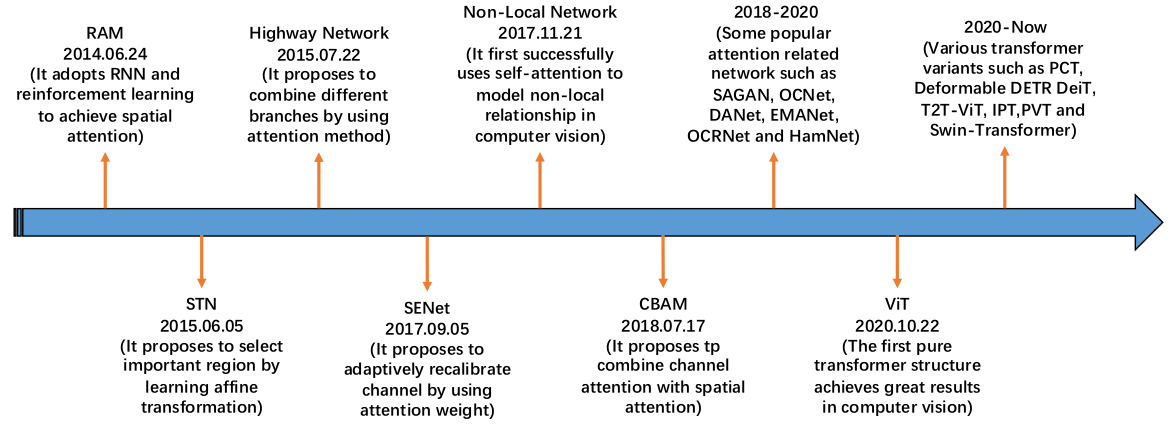
Attention in CV & RS
《Attention Mechanisms in Computer Vision: A Survey》
https://github.com/MenghaoGuo/Awesome-Vision-Attentions
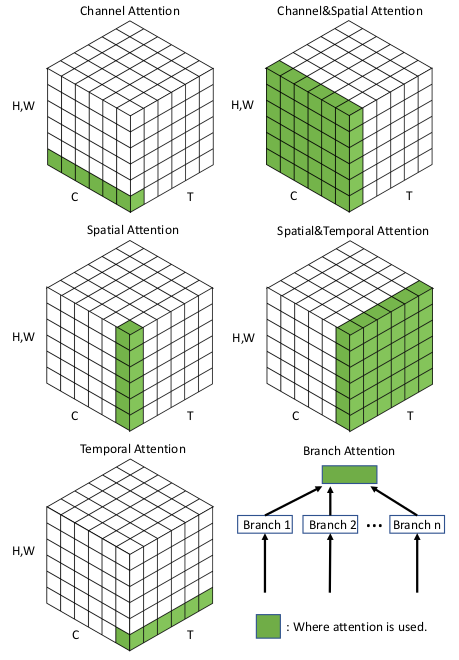
和Normalization一样,Attention应用于CV领域也有不同的花式。
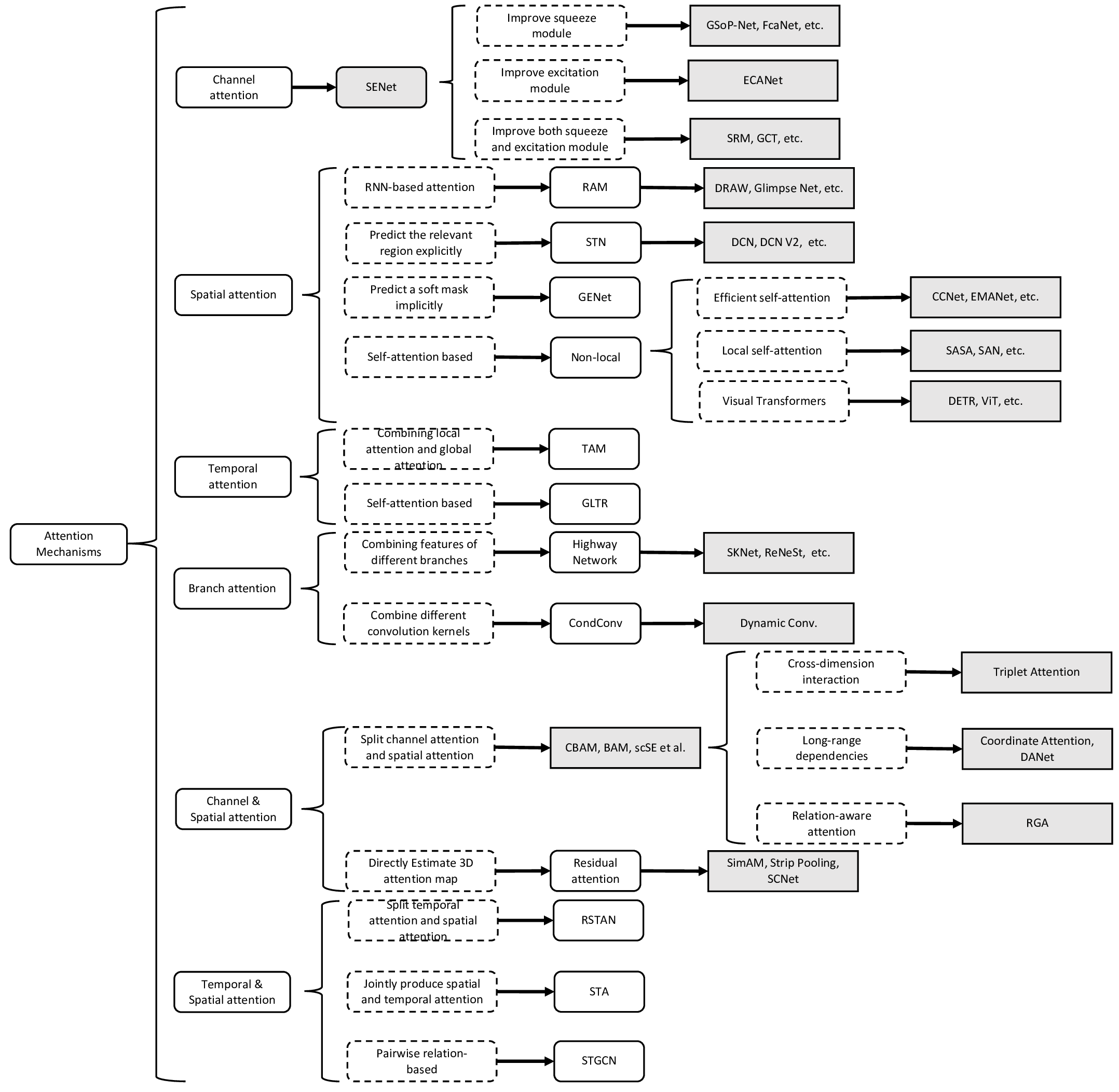
ViT
上面这些主要还局限于Layer级别的替换,在这里Attention无非是Conv的平替而已。
而下面的ViT则是从体系层面对CNN的一种颠覆了。
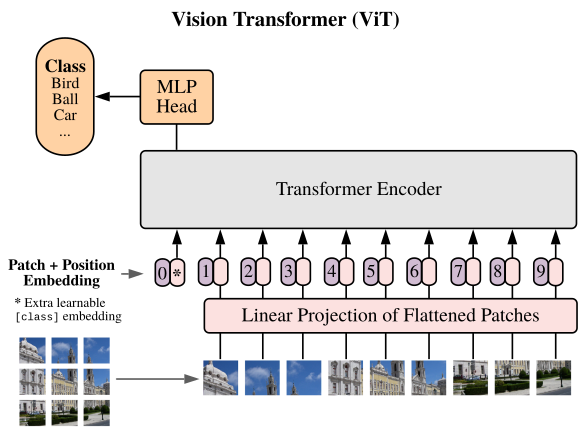
ViT借鉴了NLP的一些做法,将图片分成若干小块,每一块就是一个词向量。这样就把一个CV问题变成了NLP问题。
–
ViViT在ViT的基础上增加时间维度以处理视频。
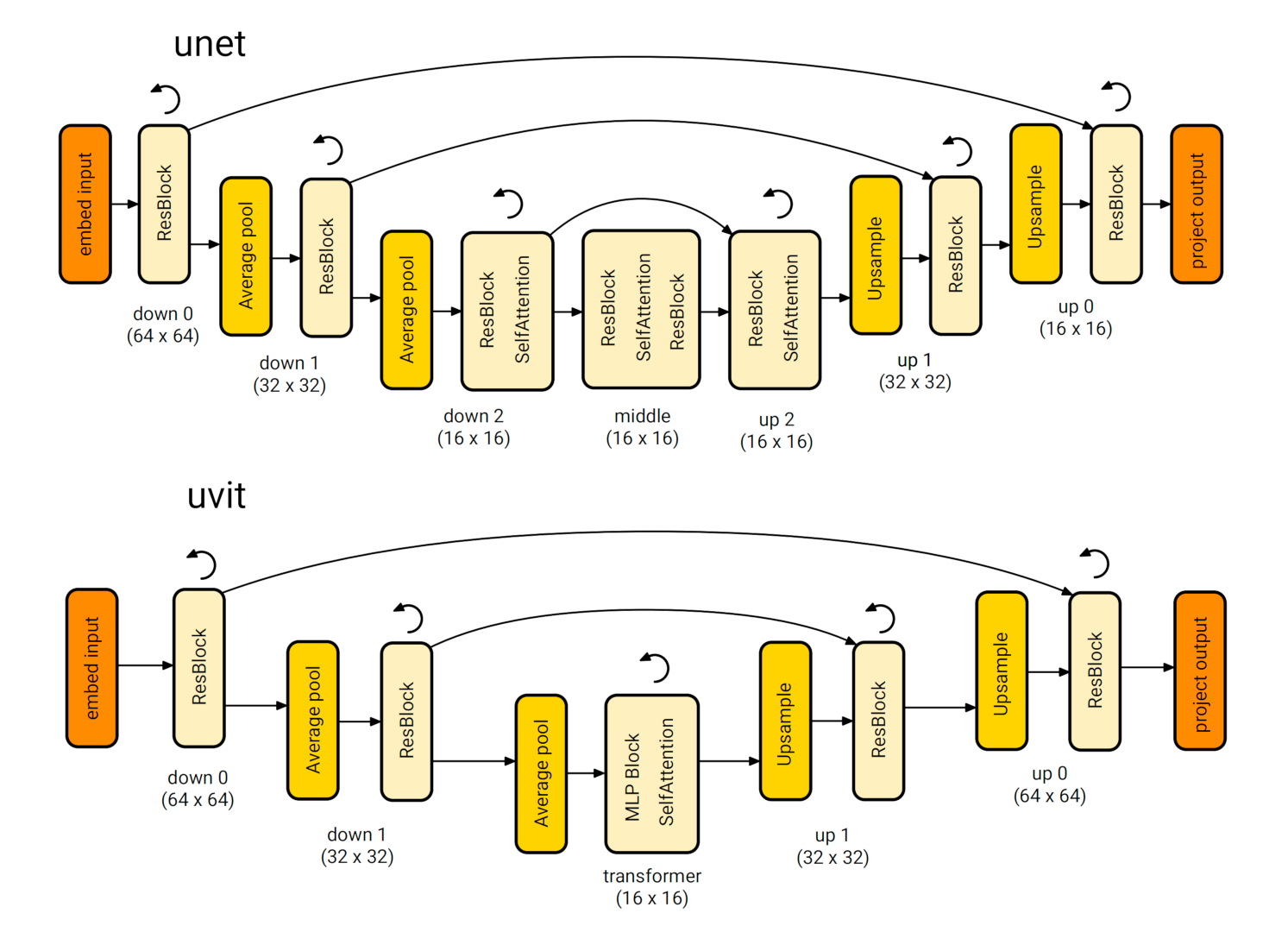
U-ViT = U-Net + ViT

您的打赏,是对我的鼓励
