AI » NLP(二), Storm
2018-01-21 :: 6742 WordsNLP
TorchNLP
代码:
https://github.com/kolloldas/torchnlp
参考:
https://mp.weixin.qq.com/s/xCHvB7gKCBxXk1_rAtG0sw
基于PyTorch/TorchText的自然语言处理库
fuzzywuzzy
fuzzywuzzy可以很容易地实现诸如字符串比较比率、token比率等操作。对于匹配不同数据库中的记录也很方便。
代码:
https://github.com/seatgeek/fuzzywuzzy
NLPchina
NLPchina(中国自然语言处理开源组织)旗下有许多好用的工具。
官网:
http://www.nlpcn.org/
Github:
https://github.com/NLPchina
Ansj
Ansj是一个NLPchina旗下的开源的Java中文分词工具,基于中科院的ictclas中文分词算法,比其他常用的开源分词工具(如mmseg4j)的分词准确率更高。
https://github.com/NLPchina/ansj_seg
Word2VEC_java
word2vec java版本的一个实现。
https://github.com/NLPchina/Word2VEC_java
doc2vec java版本的一个实现,基于Word2VEC_java。
https://github.com/yao8839836/doc2vec_java
ansj_fast_lda
LDA算法的Java包。
https://github.com/NLPchina/ansj_fast_lda
nlp-lang
这个项目是一个基本包.封装了大多数nlp项目中常用工具
https://github.com/NLPchina/nlp-lang
protege
protege软件是斯坦福大学医学院生物信息研究中心基于Java语言开发的本体编辑和知识获取软件,或者说是本体开发工具,也是基于知识的编辑器。这个软件主要用于语义网中本体的构建,是语义网中本体构建的核心开发工具。
官网:
https://protege.stanford.edu/products.php
Opendial
Opendial是一个基于Java的对话系统。可用于开发聊天机器人。
官网:
http://www.opendial-toolkit.net/
代码:
https://github.com/plison/opendial
参考:
https://github.com/zhangziliang04/OpendialEx
某牛的Opendial
https://github.com/dingdang-robot/dingdang-robot
叮当是一款可以工作在Raspberry Pi上的中文语音对话机器人/智能音箱项目。
TextInfoExp
TextInfoExp是某网友提供的自然语言处理相关实验(基于sougou数据集),包含文本特征提取(TF-IDF),文本分类,文本聚类,word2vec训练词向量及同义词词林中文词语相似度计算、文档自动摘要,信息抽取,情感分析与观点挖掘等。
网址:
https://github.com/Roshanson/TextInfoExp
NLP Architect
英特尔宣布推出开源库NLP Architect——这是一个用于自然语言处理(NLP)的库,帮助开发人员为聊天机器人和虚拟助手等会话应用提供所必需的功能,比如名称实体识别,意图提取和语义分析等,帮助智能体从对话中理解人类的行动。
官网:
http://nlp_architect.nervanasys.com/
代码:
https://github.com/NervanaSystems/nlp-architect
参考:
https://mp.weixin.qq.com/s/mKEFOTWyfF86ee8P-d2jJg
英特尔推出自然语言处理开源库,代号“NLP Architect”
Rasa
Rasa是一个基于机器学习实现多轮对话的开源机器人框架。
官网:
https://rasa.com/
Rasa NLU是自然语言理解模型集合,主要包括意图识别,实体识别,它会把用户的输入转换为结构化的数据。
Rasa Core是一个对话管理的平台,它的工作是决定接下来机器该返回什么内容给用户,即实现与用户的交互逻辑。
参考:
https://blog.csdn.net/qq_42189083/article/details/88310407
Rasa聊天机器人(一):简介及环境搭建
https://blog.csdn.net/qq_42189083/article/details/88076128
Rasa聊天机器人(二):训练及构建
其他工具
https://github.com/mozillazg/python-pinyin
python版的汉字转拼音软件
https://github.com/ysc/word
Java分布式中文分词组件-word分词
http://jena.apache.org/
jena是一个语义网络、知识图谱相关的软件。
http://www.statmt.org/moses/
moses是一个基于统计的机器翻译工具。
http://drools.org/
一个规则引擎软件。
https://mp.weixin.qq.com/s/0buG6HEFSrD7MPfKqVCzzg
构想:中文文本标注工具(附开源文本标注工具列表)。
https://mp.weixin.qq.com/s/kMQ7q4EyBQUH1DEEhQWdCQ
Familia:开源的中文主题模型应用工具包。
https://allegrograph.com/
一个现代、高性能、持久的图数据库。
http://blog.csdn.net/sinat_25551085/article/details/62896902
AllegroGraph
https://mp.weixin.qq.com/s/a2KyT929A0fn_bTFld62Cg
英文智能问答之OpenEphyra
https://github.com/rockyzhengwu/FoolNLTK
FoolNLTK:一个便捷的中文处理工具包(字向量+双向LSTM+CRF)
https://mp.weixin.qq.com/s/jjlXGaGSJO3KeJv9adLi2Q
Synonyms:一个开源的中文近义词工具包
https://mp.weixin.qq.com/s/JBu5ozGYkgBJHUyQCne0YQ
中文文本标注工具Chinese-Annotator
https://mp.weixin.qq.com/s/XZ8um7JG5IWpsDPXEHVVuw
十个经典Chatbot框架
https://github.com/RasaHQ/rasa_core
一个对话引擎
https://mp.weixin.qq.com/s/TtvsPYinL8t8PJxaj2L-2g
机器人意图识别和词槽抽取RasaNLU解析
https://mp.weixin.qq.com/s/hVjgEKD6WDct8SEAHaUCTQ
DeepPavlov:一个训练对话系统和聊天机器人的开源库
http://www.simsimi.com/
SimSimi是一款来自韩国的聊天机器人应用,以吉祥物“小鸡鸡”自居。
https://github.com/BYVoid/OpenCC
OpenCC:一个中文简繁转换的工具
https://mp.weixin.qq.com/s/-3A4eNAPa6DP-bX4x4HfQA
横向对比4大NLP Python工具包,总有一款适合你!
https://mp.weixin.qq.com/s/WYSvJLILT5u82MtgtvQkyQ
叫你一声“孙悟空”,敢答应么?(wukong-robot)
https://mp.weixin.qq.com/s/5o2X-HKgLnp0zKOxxhHPEw
DeepPavlov框架解析
https://github.com/shibing624/pycorrector
中文文本纠错工具
https://mp.weixin.qq.com/s/8tKbejWS7wnGrgOzMuEP6g
TextCluster:短文本聚类预处理模块Short text cluster
https://mp.weixin.qq.com/s/0QGfxsx1ZSNukSPDo_ae9w
45个小众而实用的NLP开源字典和工具
https://mp.weixin.qq.com/s/CcXFHul__qtu-6-iiEvmXw
如何更有效率的加载大型词嵌入模型?(Pymagnitude)
词性标注
http://jacoxu.com/ictpos3-0%E6%B1%89%E8%AF%AD%E8%AF%8D%E6%80%A7%E6%A0%87%E8%AE%B0%E9%9B%86/
ICTPOS3.0汉语词性标记集
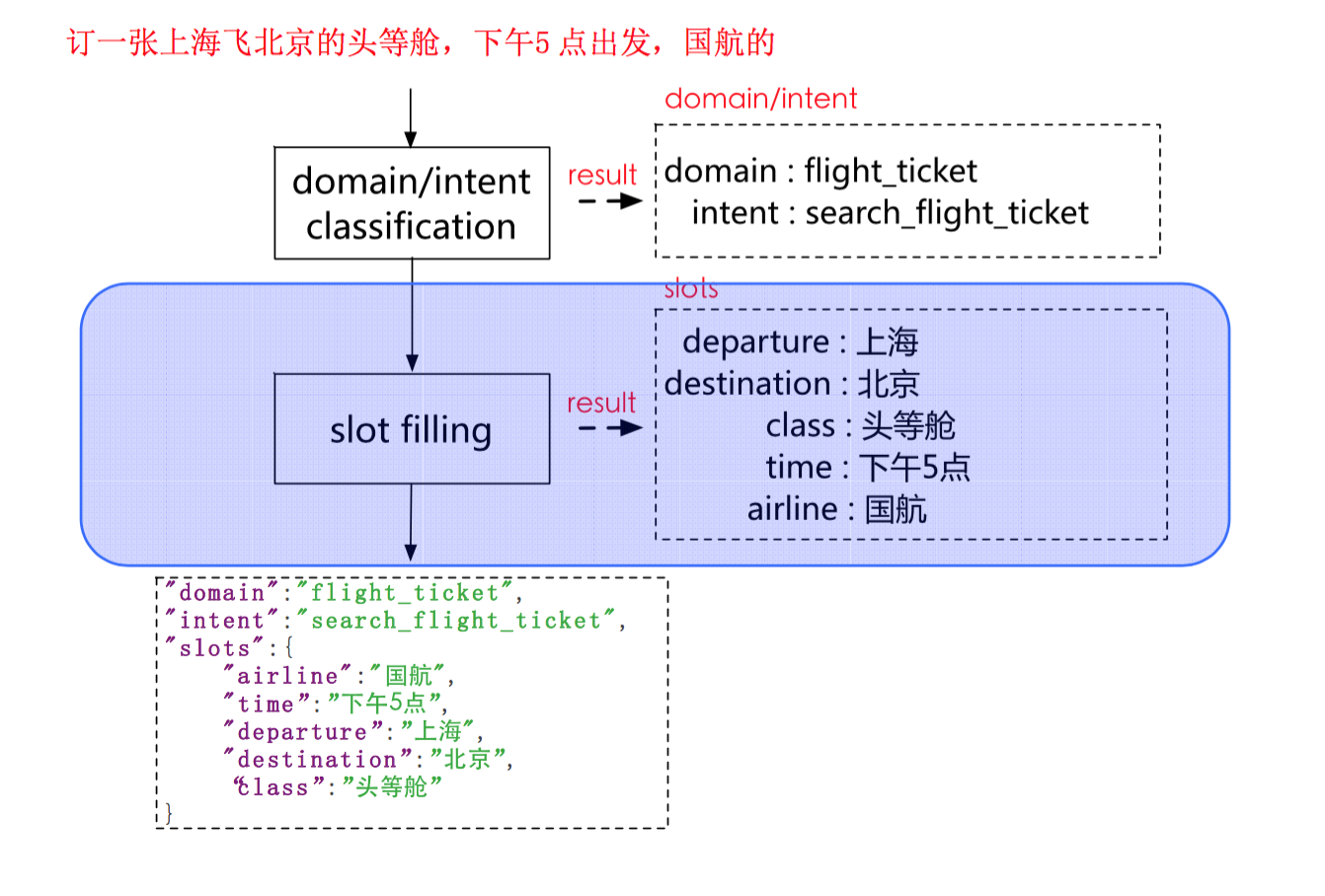
自然语言理解
Natural language understanding(NLU)属于NLP的一个分支,属于人工智能的一个部分,用来解决机器理解人类语言的问题,属于人工智能的核心难题。
上图是语义理解中,最有实用价值的框架语义表示(frame semantics representation)的原理简图。
参考:
http://www.shuang0420.com/2017/04/27/NLP%E7%AC%94%E8%AE%B0%20-%20NLU%E4%B9%8B%E6%84%8F%E5%9B%BE%E5%88%86%E7%B1%BB/
NLU之意图分类
词汇共现
词汇共现是指词汇在文档集中共同出现。以一个词为中心,可以找到一组经常与之搭配出现的词,作为它的共现词汇集。
词汇共现的其中一种用例:
有若干关键词,比如:水果、天气、风,有若干描述词,比如,很甜、晴朗、很大,然后现在要找出他们之间的搭配,在这个例子里,我们最终要找到:水果很甜、天气晴朗、风很大
http://sewm.pku.edu.cn/TianwangLiterature/SEWM/2005(5)/%5b%b3%c2%c1%88,%20et%20al.,2005%5d/050929.pdf
关键词提取
主要三种方法:
1.基于统计特征,如TF-IDF。
2.基于词图模型,如TextRank。
3.基于主题模型,如LDA。
https://mp.weixin.qq.com/s/yTLiw9am0wzeJ-O3m0xUoQ
如何做好文本关键词提取?从三种算法说起
https://mp.weixin.qq.com/s/xjSw7PbVrESo9u4otBOM1Q
白话TF-IDF应用(一):自动提取关键词
论文
《Distant Supervision for relation extraction without labeled data》
《Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding》
Semantic Role Labeling
模型导读
SGNS/cBoW、FastText、ELMo等(从词向量引出)
DSSM、DecAtt、ESIM等(从问答&匹配引出)
HAN、DPCNN等(从分类引出)
BiDAF、DrQA、QANet等(从MRC引出)
CoVe、InferSent等(从迁移引出)
MM、N-shortest等(从分词引出)
Bi-LSTM-CRF等(从NER引出)
LDA等主题模型(从文本表示引出)
Storm
Storm是一个大数据领域的实时计算框架。
官网:
http://storm.apache.org/
教程:
http://storm.apache.org/releases/current/Tutorial.html
参考:
http://blog.csdn.net/rzhzhz/article/details/8788137
Storm教程(翻译)
http://ifeve.com/getting-started-with-stom-index/
《Storm入门》中文版
http://blog.csdn.net/NB_vol_1/article/details/46287077
一个storm的完整例子——WordCount
http://www.open-open.com/lib/view/open1374979211233.html
storm简介及单机版安装指南
http://mp.weixin.qq.com/s/lDQLXuMBzZG-o-mGwBNcIA
美团点评基于Storm的实时数据处理实践
示例
这里使用源代码中自带的示例。
1.下载源代码。
2.mvn clean install -DskipTests=true
3.进入examples/storm-starter目录:
mvn compile exec:java -Dstorm.topology=org.apache.storm.starter.ExclamationTopology
Trident
Trident是在storm基础上,一个以realtime计算为目标的高度抽象。它在提供处理大吞吐量数据能力的同时,也提供了低延时分布式查询和有状态流式处理的能力。
教程:
http://storm.apache.org/releases/current/Trident-tutorial.html
http://blog.csdn.net/derekjiang/article/details/9126185
教程中文版
Storm vs Spark
http://blog.csdn.net/iefreer/article/details/32715153
两款高性能并行计算引擎Storm和Spark比较
问题汇总
http://blog.sina.com.cn/s/blog_8c243ea30101k0k1.html
Storm实战常见问题及解决方案
集群部署
Storm的本地模式,无须hadoop生态圈软件的支持,自己就能运行。但它的集群部署依赖Zookeeper和YARN。
1.配置YARN和Zookeeper,并启动相关服务进程。
2.配置Storm
https://storm.apache.org/releases/current/Setting-up-a-Storm-cluster.html
3.启动Nimbus和Supervisor
Nimbus和Supervisor都是Storm服务进程,前者运行在Master上,而后者运行在Node上。这里的Master和Node,可以和Zookeeper或YARN设置的不同。
Nimbus的作用是将运行的jar分发到各Node去执行。
虽然bin/storm nimbus可以启动nimbus,然而这种方法启动的是前台进程,一旦退出终端,进程就会被杀死。可用如下方法解决之:
start-stop-daemon --start --background --exec /root/apache-storm-1.0.2/bin/storm nimbus
JStorm
由于Storm部分是由Clojure语言写的,维护成本较高,阿里巴巴提出了完全由Java编写的JStorm。
官网:
http://jstorm.io/

您的打赏,是对我的鼓励
