深度加速(六)——模型压缩与加速, 知识蒸馏
2019-07-27模型压缩与加速
Network Pruning(续)
Weight Pruning需要相关硬件支持跳零操作才能真正加速运算,而Filter/Layer Pruning则无需特殊硬件支持。
虽然这些参数、结点和层相对不重要,但是去掉之后,仍然会对准确度有所影响。这时可以对精简之后的模型,用训练样本进行re-train,通过残差对模型进行一定程度的修正,以提高准确度。
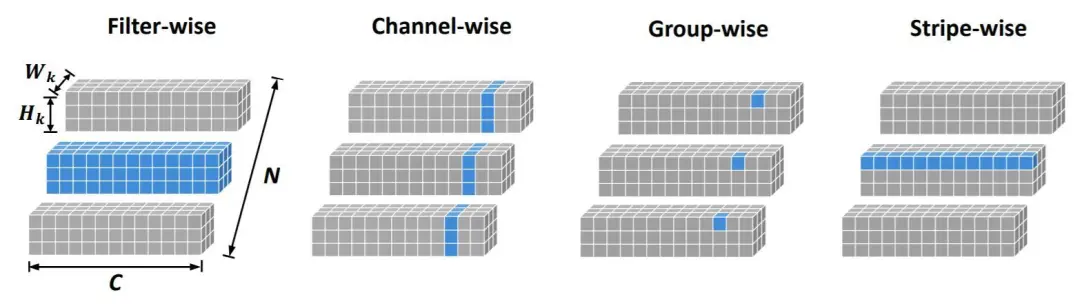
此外还有Stripe-Wise Pruning:
https://mp.weixin.qq.com/s/HohsD57cQtTR5SvuykEDuA
优图NeurIPS 2020论文,刷新滤波器剪枝的SOTA效果
还可以看看图森科技的论文:
https://www.zhihu.com/question/62068158
如何评价图森科技连发的三篇关于深度模型压缩的文章?
图森的思路比较有意思。其中的方法之一,是利用L1规则化会导致结果的稀疏化的特性,制造出一批接近0的参数。从而达到去除不重要的参数的目的。
除此之外,矩阵量化、Kronecker内积、霍夫曼编码、模型剪枝等也是常见的模型压缩方法。
彩票假说(ICLR2019会议的best paper):随机初始化的密集神经网络包含一个初始化的子网,当经过隔离训练时,它可以匹配训练后最多相同迭代次数的原始网络的测试精度。
https://mp.weixin.qq.com/s/wOaCjSifZqkndaGbst1-aw
一文带你了解NeurlPS2020的模型剪枝研究
权值稀疏化实战
这里讲一下韩松论文提到的裁剪方法中,最简单的一种——“权值稀疏化“的工程实现细节。以darknet框架为例。
1.在src/parser.c中找到save_XXX_weights函数。判断权值是否接近0,如果是,则强制设为0。
2.使用修改后的weights进行re-train。训练好之后,重复第1、2步。
3.反复多次之后,进入最终prune阶段。修改src/network.c:update_network,令其不更新0权值。
re-train时的learning rate一般不宜太大。如果出现re-train的效果,还不如直接prune的好,则多半是learning rate设置的问题。
一般采用稀疏化率来描述权值的稀疏化程度。每层的稀疏化率可以相同,也可以不同。前者被称作Magnitude Pruner,而后者被称作Sensitivity Pruner。
权值稀疏化的设置也和网络结构有关。比如分类网络,由于输入图片是高维数据,而分类结果是低维数据,因此在稀疏化处理的时候,越靠近输出结果的Layer,其稀疏化程度就可以越高。而最初的几层,即使只加少量稀疏化,也会导致精度的大幅下降,这时往往就不做或者少做稀疏化处理了。
上述方法的问题在于,分类网络的计算量主要集中在最初几层,所以这种triangle prune mode对于压缩计算量的效果一般。
除了训练后的权值稀疏化之外,权值稀疏化训练也是一种方法。
论文:
《FLOPs as a Direct Optimization Objective for Learning Sparse Neural Networks》
这篇论文,将计算量也就是FLOPs作为Loss function设计的一部分,由于稀疏化的权值没有运算量,因此,采用这种Loss训练出的网络,天生就是稀疏化的。
AutoML
由于模型压缩,本质上是一个精益求精的优化问题,因此采用AutoML技术对于各个超参数进行优化,就成为了一件很有必要的事情。
这里主要的问题在于超参数数量众多,导致状态空间过大。
论文:
《AMC: AutoML for Model Compression and Acceleration on Mobile Devices》
这是韩松组的何宜晖的作品。该论文采用深度强化学习的DDPG网络来优化目标网络,从而大大减少了需要搜索的状态空间。
EfficientNet
反思:为什么有些模型FLOPs很低,以EfficientNet为代表,其推理速度却很慢。
https://zhuanlan.zhihu.com/p/122943688
FLOPs与模型推理速度
参考:
https://mp.weixin.qq.com/s/on1YdDexq5ICZL70mvikyw
谷歌大脑提出EfficientNet平衡模型扩展三个维度,取得精度-效率的最大化!
https://mp.weixin.qq.com/s/tCdG9gvpav1SvEzyAyBZXA
谷歌EfficientNet缩放模型,PyTorch实现出炉,登上GitHub热榜
https://mp.weixin.qq.com/s/NPM4E2gGOf3awQw7-_s6Uw
令人拍案叫绝的EfficientNet和EfficientDet
https://mp.weixin.qq.com/s/_eJ27nKULYzUNzDEf62x2w
何恺明团队最新力作RegNet:超越EfficientNet,GPU上提速5倍
https://mp.weixin.qq.com/s/WYG0XAhoPTOn_qCilT9yfw
一文读懂EfficientDet
https://mp.weixin.qq.com/s/Jklyqt55-8NfKJ5oUXCmHw
EfficientDet框架详解
参考
https://github.com/memoiry/Awesome-model-compression-and-acceleration
模型压缩与加速相关资源汇总
https://mp.weixin.qq.com/s/bndECrtEcNCkCF5EG0wO-A
移动端机器学习资源合集
https://blog.csdn.net/hw5226349/article/details/84888416
Deep Compression/Acceleration:模型压缩加速论文汇总
https://zhuanlan.zhihu.com/p/58805980
深度学习的模型加速与模型裁剪方法
https://mp.weixin.qq.com/s/pAEoVs8xu0SY9tfBqOJHHA
Google DeepMind最新报告—深度神经网络压缩进展
http://blog.csdn.net/shuzfan/article/details/51383809
神经网络压缩:Deep Compression
https://mp.weixin.qq.com/s/2NOFyu_twx1EciDeDPBLKw
深度神经网络加速与压缩
https://mp.weixin.qq.com/s/lO2UM04PfSM5VJYh6vINhw
为模型减减肥:谈谈移动/嵌入式端的深度学习
https://mp.weixin.qq.com/s/cIGuJvYr4lZW01TdINBJnA
深度压缩网络:较大程度减少了网络参数存储问题
https://mp.weixin.qq.com/s/1JwLP0FmV1AGJ65iDgLWQw
神经网络模型压缩技术
http://mp.weixin.qq.com/s/iapih9Mme-VKCfsFCmO7hQ
简单聊聊压缩网络
https://mp.weixin.qq.com/s/dEdWz4bovmk65fwLknHBhg
韩松毕业论文:面向深度学习的高效方法与硬件
https://mp.weixin.qq.com/s/f1SCK0J5oTWNJvtld3UAHQ
神经网络修剪最新研究进展
知识蒸馏
基本概念
知识蒸馏是另一大类的模型压缩方法。
这类方法的开山之作,当属Geoffrey Hinton和Jeff Dean的论文:
《Distilling the Knowledge in a Neural Network》
一个很大的DNN往往训练出来的效果会比较好,并且多个DNN一起ensemble的话效果会更好。但是实际应用中,过于庞大的DNN ensemble会增大计算量,从而影响应用。于是一个问题就被提出了:有没有一个方法,能使降低网络的规模,但是保持(一定程度上的)精确度呢?
Hinton举了一个仿生学的例子,就是昆虫在幼生期的时候往往都是一样的,适于它们从环境中摄取能量和营养;然而当它们成长到成熟期,会基于不同的环境或者身份,变成另外一种形态以适应这种环境。
那么对于DNN是不是存在类似的方法?在一开始training的过程中比较庞杂,但是当后来需要拿去deploy的时候,可以转换成一个更小的模型。他把这种方法叫做Knowledge Distillation(KD)。
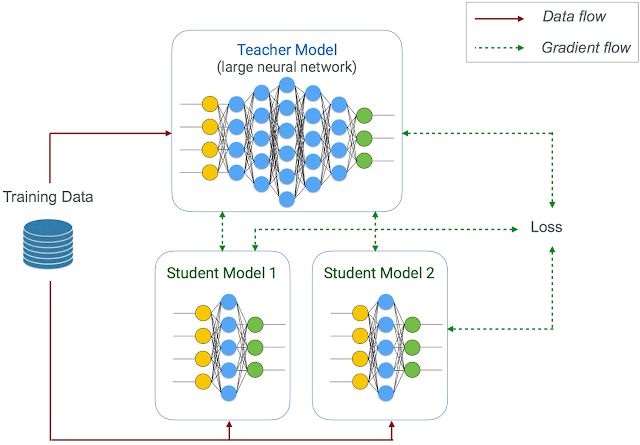
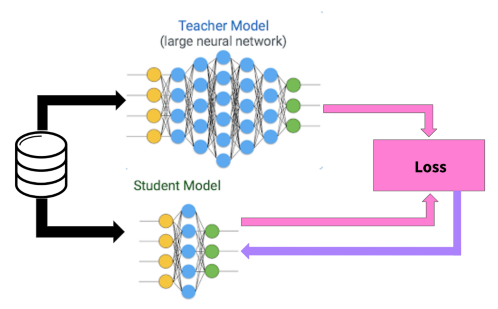
上图是KD的网络结构图。它的主要思想就是通过一个performance非常好的大网络(有可能是ensemble的)来教一个小网络进行学习。这里我们可以把大网络叫为:teacher network,小网络叫为:student network。
teacher network可以被固定(正如在精炼过程中)或联合优化,甚至同时训练多个不同大小的student network。
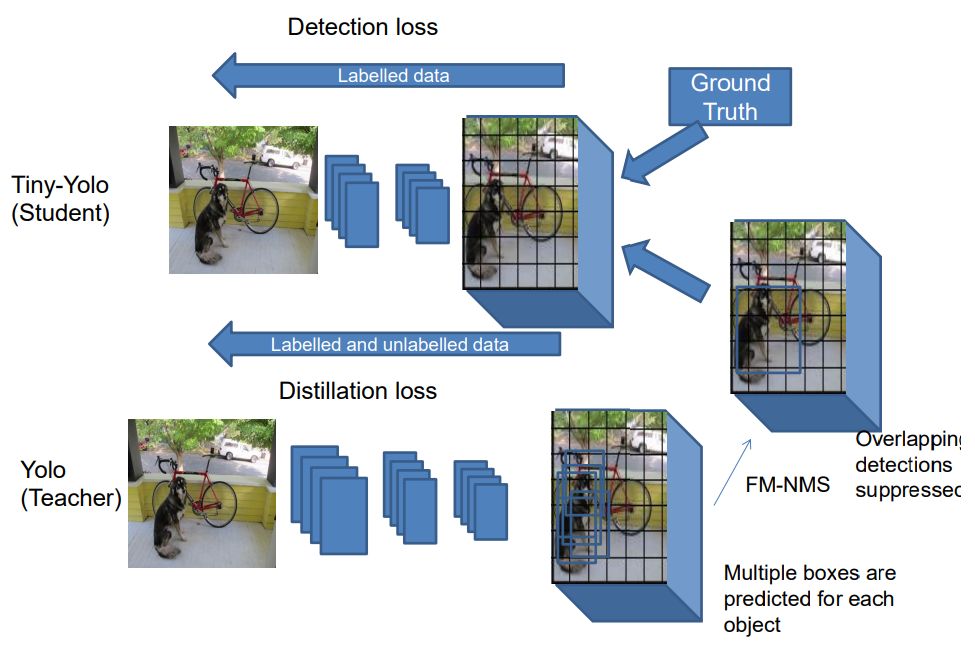
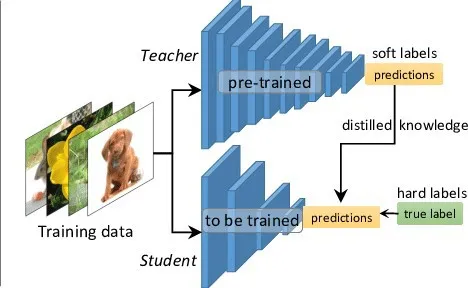
上图是另一篇论文的图:
《Object detection at 200 Frames Per Second》
该论文的中文版:
https://mp.weixin.qq.com/s/OCG1TiHl2dsuS24uacQ-MA
又快又准确,新目标检测器速度可达每秒200帧
soft target
由于有teacher network的存在,student network的训练也和普通的监督学习有所不同。
论文:
《Articulatory and Spectrum Features Integration using Generalized Distillation Framework》
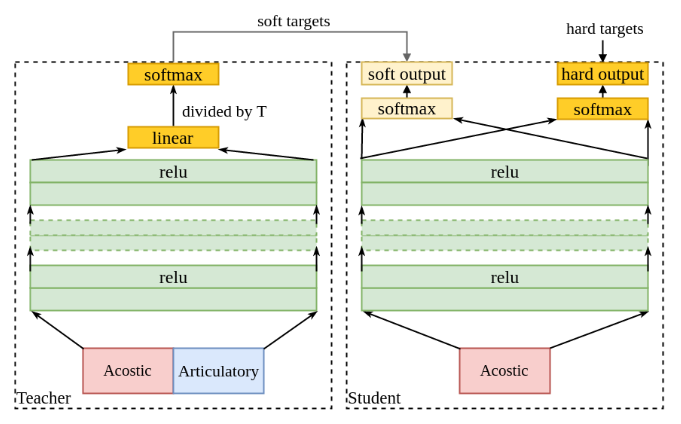
上图是两者的训练过程。
这里解释一下,何为soft target?
Hinton给了个例子:比如说在MNIST数据集中,有两个数字“2”,但是写法是不一样的:一个可能写的比较像3(后面多出了一点头),一个写的比较像7(出的头特别的短)。在这样的情况下,grund truth label都是“2”,然而一个学习的很好的大网络会给label“3”和“7”都有一定的概率值。通常叫这种信息为“soft targets”;相对的,gt label是一种“hard targets”因为它是one-hot label。总的来说就是,通过大网络的“soft targets”,能得到更加多的信息来更好的训练小网络。
soft targets的计算方法如下:
\[q_i = \frac{exp(z_i/T)}{\sum_j exp(z_j / T)}\]上式实际上是Boltzmann distribution的PDF。(参见《数学狂想曲(五)》)所以T也被称为温度(Temperature),通常默认1。对于分类任务来说使用\(T=1\)往往会导致不同类的概率差距很大,过度集中于某一个类,而其他类别的信息难以利用,这就是所谓的hard targets。
如果增大T的话,不同类别的差异就变小了,这也就是soft targets。类似于Label smoothing Regularization(LSR)。
如果T接近于0,则最大的值会越近1,其它值会接近0,近似于one-hot编码。
如果T等于无穷,那就是一个均匀分布。
综上,KD的流程就很自然了:
-
先训练一个teacher网络。
-
然后使用这个teacher网络的输出和数据的真实标签去训练student网络。
参考:
https://www.zhihu.com/question/50519680
如何理解soft target这一做法?
https://mp.weixin.qq.com/s/XR8OlGv5Ciglq03Ul_jpvQ
谈谈我眼中的Label Smooth
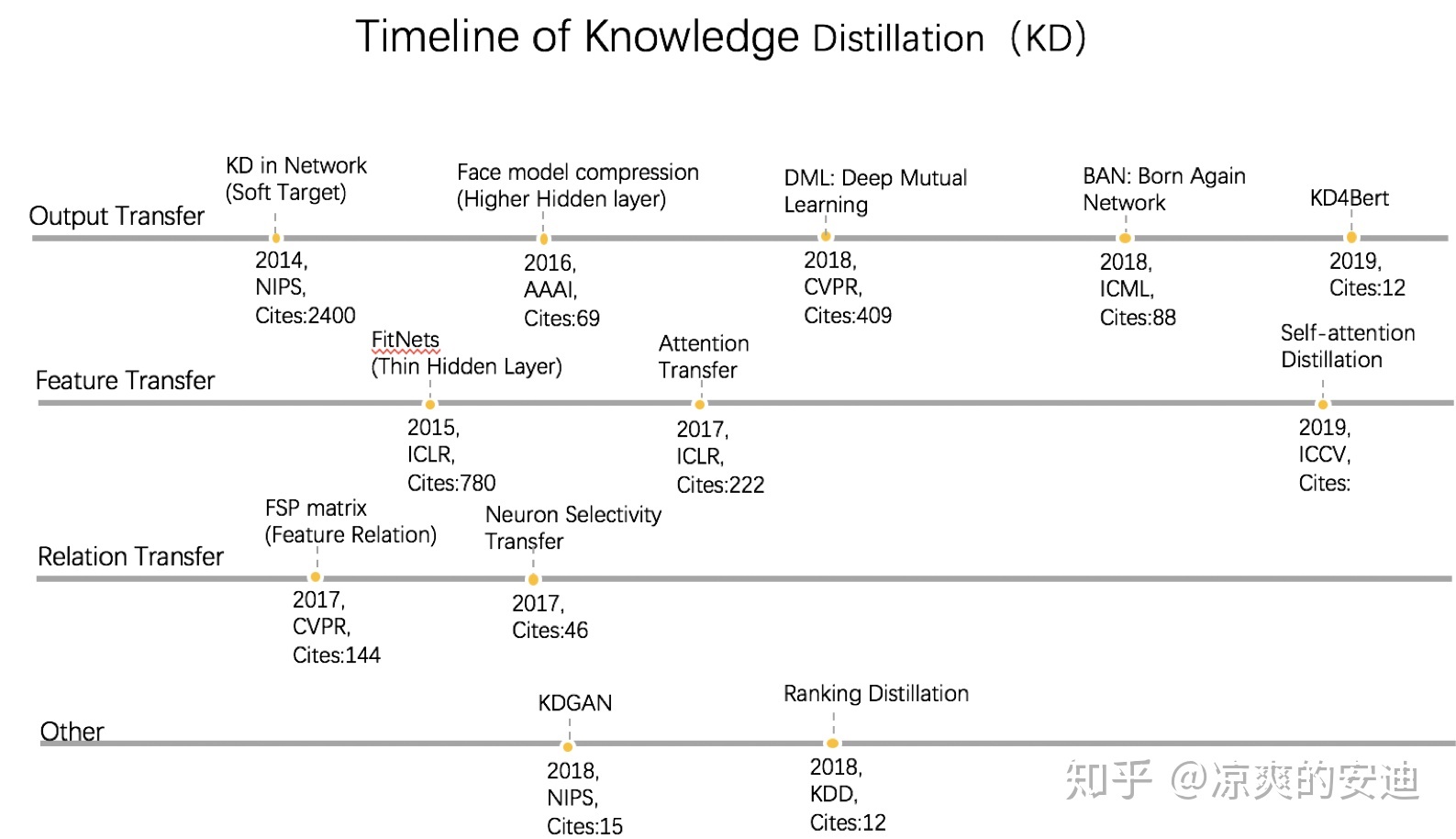
KD的进化史
Theseus压缩
研究者受到著名哲学思想实验“忒修斯之船”(The Ship of Theseus)启发(如果船上的木头逐渐被替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?),提出了Theseus Compression for BERT(BERT-of-Theseus),该方法逐步将BERT的原始模块替换成参数更少的替代模块。研究者将原始模型叫做“前辈”(predecessor),将压缩后的模型叫做“接替者“(successor),分别对应KD中的教师和学生。
参考:
https://mp.weixin.qq.com/s/HdG3_CaSdZP3lCp8J_VRQA
只需一个损失函数、一个超参数即可压缩BERT,MSRA提出模型压缩新方法

